 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertainty and Uncertainty Guided Active Domain Adaptation
May 26, 2025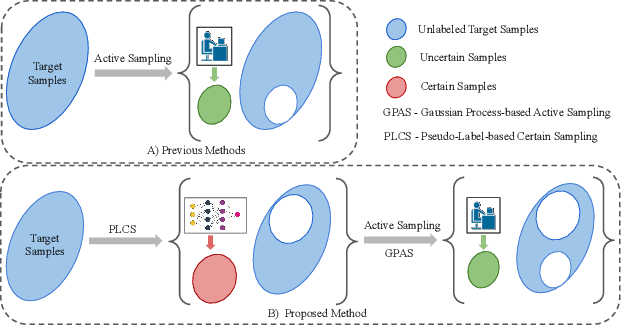
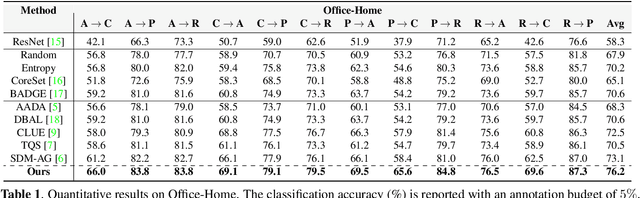
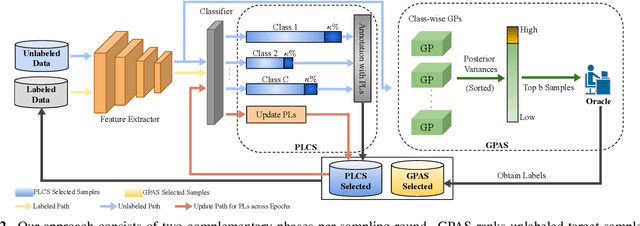

Active Domain Adaptation (ADA) adapts models to target domains by selectively labeling a few target samples. Existing ADA methods prioritize uncertain samples but overlook confident ones, which often match ground-truth. We find that incorporating confident predictions into the labeled set before active sampling reduces the search space and improves adaptation. To address this, we propose a collaborative framework that labels uncertain samples while treating highly confident predictions as ground truth. Our method combines Gaussian Process-based Active Sampling (GPAS) for identifying uncertain samples and Pseudo-Label-based Certain Sampling (PLCS) for confident ones, progressively enhancing adaptation. PLCS refines the search space, and GPAS reduces the domain gap, boosting the proportion of confident samples. Extensive experiments on Office-Home and DomainNet show that our approach outperforms state-of-the-art ADA methods.
FaceXBench: Evaluating Multimodal LLMs on Face Understanding
Jan 17, 2025Multimodal Large Language Models (MLLMs) demonstrate impressive problem-solving abilities across a wide range of tasks and domains. However, their capacity for face understanding has not been systematically studied. To address this gap, we introduce FaceXBench, a comprehensive benchmark designed to evaluate MLLMs on complex face understanding tasks. FaceXBench includes 5,000 multimodal multiple-choice questions derived from 25 public datasets and a newly created dataset, FaceXAPI. These questions cover 14 tasks across 6 broad categories, assessing MLLMs' face understanding abilities in bias and fairness, face authentication, recognition, analysis, localization and tool retrieval. Using FaceXBench, we conduct an extensive evaluation of 26 open-source MLLMs alongside 2 proprietary models, revealing the unique challenges in complex face understanding tasks. We analyze the models across three evaluation settings: zero-shot, in-context task description, and chain-of-thought prompting. Our detailed analysis reveals that current MLLMs, including advanced models like GPT-4o, and GeminiPro 1.5, show significant room for improvement. We believe FaceXBench will be a crucial resource for developing MLLMs equipped to perform sophisticated face understanding. Code: https://github.com/Kartik-3004/facexbench
Zero-Shot Scene Understanding for Automatic Target Recognition Using Large Vision-Language Models
Jan 13, 2025



Automatic target recognition (ATR) plays a critical role in tasks such as navigation and surveillance, where safety and accuracy are paramount. In extreme use cases, such as military applications, these factors are often challenged due to the presence of unknown terrains, environmental conditions, and novel object categories. Current object detectors, including open-world detectors, lack the ability to confidently recognize novel objects or operate in unknown environments, as they have not been exposed to these new conditions. However, Large Vision-Language Models (LVLMs) exhibit emergent properties that enable them to recognize objects in varying conditions in a zero-shot manner. Despite this, LVLMs struggle to localize objects effectively within a scene. To address these limitations, we propose a novel pipeline that combines the detection capabilities of open-world detectors with the recognition confidence of LVLMs, creating a robust system for zero-shot ATR of novel classes and unknown domains. In this study, we compare the performance of various LVLMs for recognizing military vehicles, which are often underrepresented in training datasets. Additionally, we examine the impact of factors such as distance range, modality, and prompting methods on the recognition performance, providing insights into the development of more reliable ATR systems for novel conditions and classes.
SegFace: Face Segmentation of Long-Tail Classes
Dec 11, 2024Face parsing refers to the semantic segmentation of human faces into key facial regions such as eyes, nose, hair, etc. It serves as a prerequisite for various advanced applications, including face editing, face swapping, and facial makeup, which often require segmentation masks for classes like eyeglasses, hats, earrings, and necklaces. These infrequently occurring classes are called long-tail classes, which are overshadowed by more frequently occurring classes known as head classes. Existing methods, primarily CNN-based, tend to be dominated by head classes during training, resulting in suboptimal representation for long-tail classes. Previous works have largely overlooked the problem of poor segmentation performance of long-tail classes. To address this issue, we propose SegFace, a simple and efficient approach that uses a lightweight transformer-based model which utilizes learnable class-specific tokens. The transformer decoder leverages class-specific tokens, allowing each token to focus on its corresponding class, thereby enabling independent modeling of each class. The proposed approach improves the performance of long-tail classes, thereby boosting overall performance. To the best of our knowledge, SegFace is the first work to employ transformer models for face parsing. Moreover, our approach can be adapted for low-compute edge devices, achieving 95.96 FPS. We conduct extensive experiments demonstrating that SegFace significantly outperforms previous state-of-the-art models, achieving a mean F1 score of 88.96 (+2.82) on the CelebAMask-HQ dataset and 93.03 (+0.65) on the LaPa dataset. Code: https://github.com/Kartik-3004/SegFace
FaceXFormer: A Unified Transformer for Facial Analysis
Mar 19, 2024In this work, we introduce FaceXformer, an end-to-end unified transformer model for a comprehensive range of facial analysis tasks such as face parsing, landmark detection, head pose estimation, attributes recognition, and estimation of age, gender, race, and landmarks visibility. Conventional methods in face analysis have often relied on task-specific designs and preprocessing techniques, which limit their approach to a unified architecture. Unlike these conventional methods, our FaceXformer leverages a transformer-based encoder-decoder architecture where each task is treated as a learnable token, enabling the integration of multiple tasks within a single framework. Moreover, we propose a parameter-efficient decoder, FaceX, which jointly processes face and task tokens, thereby learning generalized and robust face representations across different tasks. To the best of our knowledge, this is the first work to propose a single model capable of handling all these facial analysis tasks using transformers. We conducted a comprehensive analysis of effective backbones for unified face task processing and evaluated different task queries and the synergy between them. We conduct experiments against state-of-the-art specialized models and previous multi-task models in both intra-dataset and cross-dataset evaluations across multiple benchmarks. Additionally, our model effectively handles images "in-the-wild," demonstrating its robustness and generalizability across eight different tasks, all while maintaining the real-time performance of 37 FPS.
PosSAM: Panoptic Open-vocabulary Segment Anything
Mar 14, 2024
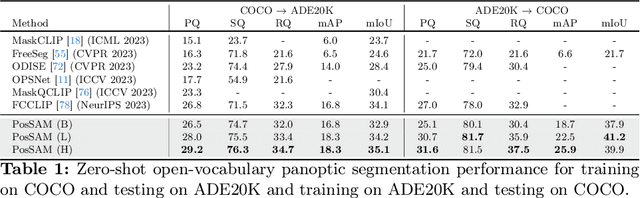

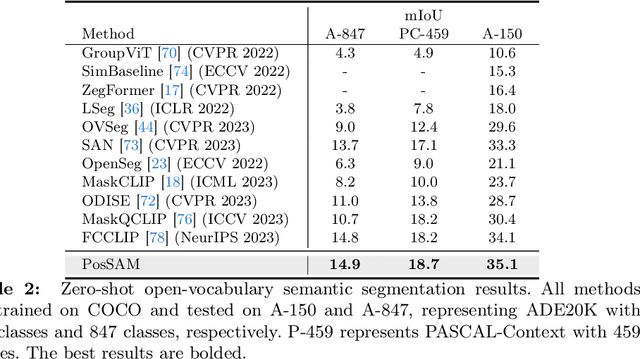
In this paper, we introduce an open-vocabulary panoptic segmentation model that effectively unifies the strengths of the Segment Anything Model (SAM) with the vision-language CLIP model in an end-to-end framework. While SAM excels in generating spatially-aware masks, it's decoder falls short in recognizing object class information and tends to oversegment without additional guidance. Existing approaches address this limitation by using multi-stage techniques and employing separate models to generate class-aware prompts, such as bounding boxes or segmentation masks. Our proposed method, PosSAM is an end-to-end model which leverages SAM's spatially rich features to produce instance-aware masks and harnesses CLIP's semantically discriminative features for effective instance classification. Specifically, we address the limitations of SAM and propose a novel Local Discriminative Pooling (LDP) module leveraging class-agnostic SAM and class-aware CLIP features for unbiased open-vocabulary classification. Furthermore, we introduce a Mask-Aware Selective Ensembling (MASE) algorithm that adaptively enhances the quality of generated masks and boosts the performance of open-vocabulary classification during inference for each image. We conducted extensive experiments to demonstrate our methods strong generalization properties across multiple datasets, achieving state-of-the-art performance with substantial improvements over SOTA open-vocabulary panoptic segmentation methods. In both COCO to ADE20K and ADE20K to COCO settings, PosSAM outperforms the previous state-of-the-art methods by a large margin, 2.4 PQ and 4.6 PQ, respectively. Project Website: https://vibashan.github.io/possam-web/.
Entropic Open-set Active Learning
Dec 21, 2023Active Learning (AL) aims to enhance the performance of deep models by selecting the most informative samples for annotation from a pool of unlabeled data. Despite impressive performance in closed-set settings, most AL methods fail in real-world scenarios where the unlabeled data contains unknown categories. Recently, a few studies have attempted to tackle the AL problem for the open-set setting. However, these methods focus more on selecting known samples and do not efficiently utilize unknown samples obtained during AL rounds. In this work, we propose an Entropic Open-set AL (EOAL) framework which leverages both known and unknown distributions effectively to select informative samples during AL rounds. Specifically, our approach employs two different entropy scores. One measures the uncertainty of a sample with respect to the known-class distributions. The other measures the uncertainty of the sample with respect to the unknown-class distributions. By utilizing these two entropy scores we effectively separate the known and unknown samples from the unlabeled data resulting in better sampling. Through extensive experiments, we show that the proposed method outperforms existing state-of-the-art methods on CIFAR-10, CIFAR-100, and TinyImageNet datasets. Code is available at \url{https://github.com/bardisafa/EOAL}.
Mask-free OVIS: Open-Vocabulary Instance Segmentation without Manual Mask Annotations
Mar 29, 2023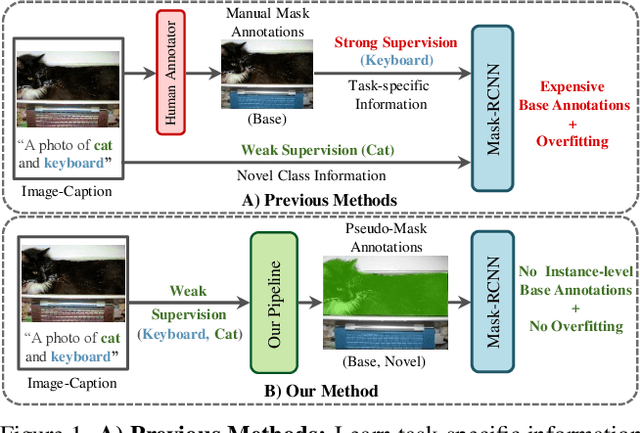
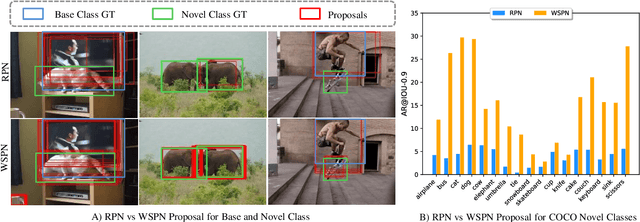
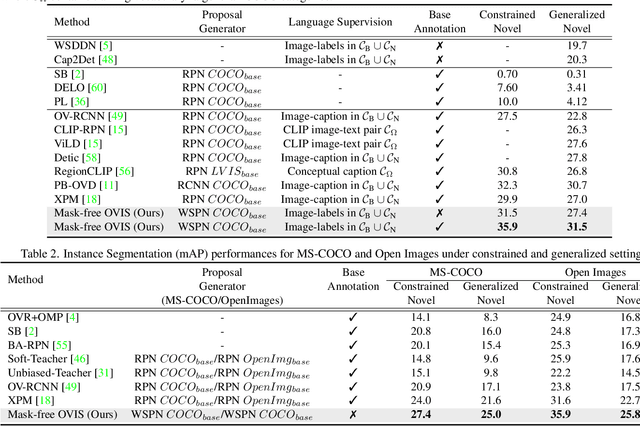
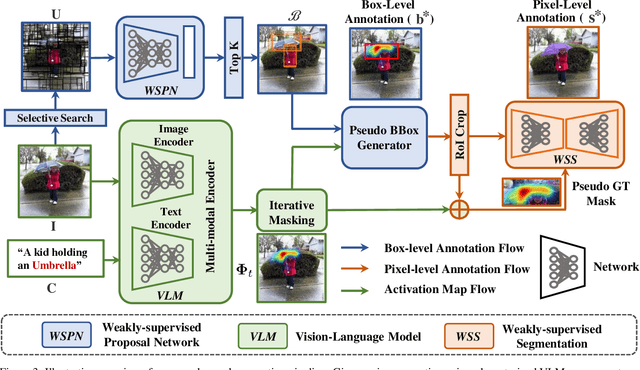
Existing instance segmentation models learn task-specific information using manual mask annotations from base (training) categories. These mask annotations require tremendous human effort, limiting the scalability to annotate novel (new) categories. To alleviate this problem, Open-Vocabulary (OV) methods leverage large-scale image-caption pairs and vision-language models to learn novel categories. In summary, an OV method learns task-specific information using strong supervision from base annotations and novel category information using weak supervision from image-captions pairs. This difference between strong and weak supervision leads to overfitting on base categories, resulting in poor generalization towards novel categories. In this work, we overcome this issue by learning both base and novel categories from pseudo-mask annotations generated by the vision-language model in a weakly supervised manner using our proposed Mask-free OVIS pipeline. Our method automatically generates pseudo-mask annotations by leveraging the localization ability of a pre-trained vision-language model for objects present in image-caption pairs. The generated pseudo-mask annotations are then used to supervise an instance segmentation model, freeing the entire pipeline from any labour-expensive instance-level annotations and overfitting. Our extensive experiments show that our method trained with just pseudo-masks significantly improves the mAP scores on the MS-COCO dataset and OpenImages dataset compared to the recent state-of-the-art methods trained with manual masks. Codes and models are provided in https://vibashan.github.io/ovis-web/.
Open-Set Automatic Target Recognition
Nov 10, 2022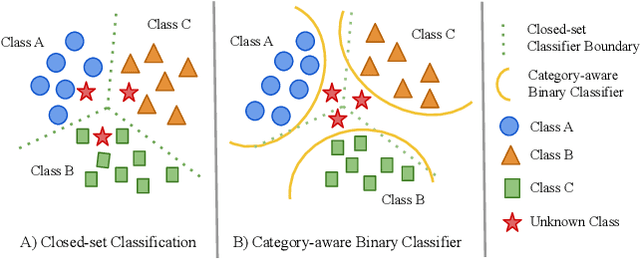

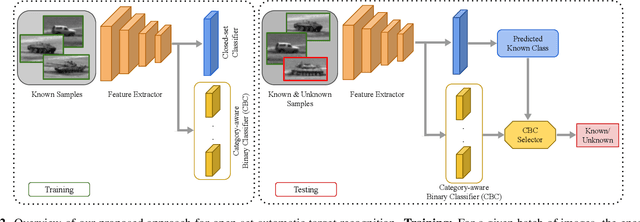

Automatic Target Recognition (ATR) is a category of computer vision algorithms which attempts to recognize targets on data obtained from different sensors. ATR algorithms are extensively used in real-world scenarios such as military and surveillance applications. Existing ATR algorithms are developed for traditional closed-set methods where training and testing have the same class distribution. Thus, these algorithms have not been robust to unknown classes not seen during the training phase, limiting their utility in real-world applications. To this end, we propose an Open-set Automatic Target Recognition framework where we enable open-set recognition capability for ATR algorithms. In addition, we introduce a plugin Category-aware Binary Classifier (CBC) module to effectively tackle unknown classes seen during inference. The proposed CBC module can be easily integrated with any existing ATR algorithms and can be trained in an end-to-end manner. Experimental results show that the proposed approach outperforms many open-set methods on the DSIAC and CIFAR-10 datasets. To the best of our knowledge, this is the first work to address the open-set classification problem for ATR algorithms. Source code is available at: https://github.com/bardisafa/Open-set-ATR.
Towards Online Domain Adaptive Object Detection
Apr 11, 2022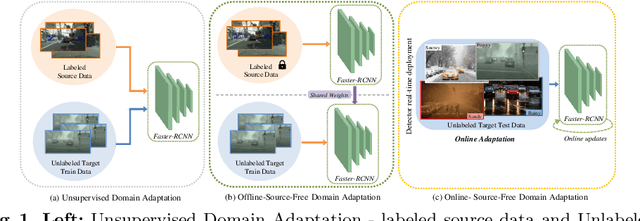
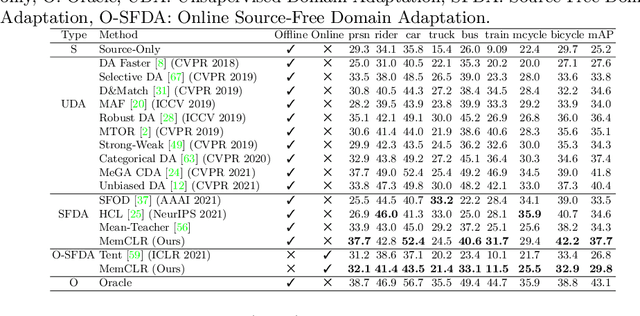
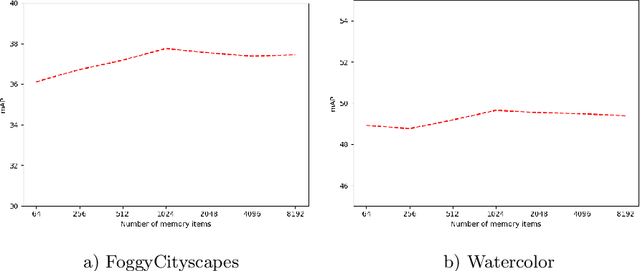
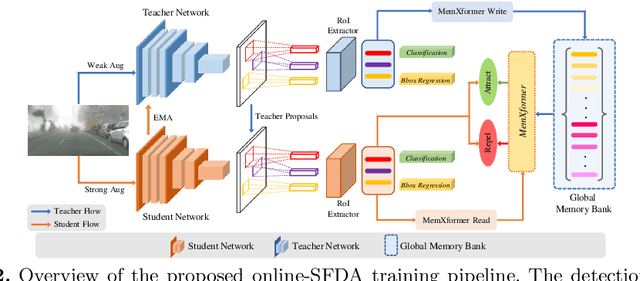
Existing object detection models assume both the training and test data are sampled from the same source domain. This assumption does not hold true when these detectors are deployed in real-world applications, where they encounter new visual domain. Unsupervised Domain Adaptation (UDA) methods are generally employed to mitigate the adverse effects caused by domain shift. Existing UDA methods operate in an offline manner where the model is first adapted towards the target domain and then deployed in real-world applications. However, this offline adaptation strategy is not suitable for real-world applications as the model frequently encounters new domain shifts. Hence, it becomes critical to develop a feasible UDA method that generalizes to these domain shifts encountered during deployment time in a continuous online manner. To this end, we propose a novel unified adaptation framework that adapts and improves generalization on the target domain in online settings. In particular, we introduce MemXformer - a cross-attention transformer-based memory module where items in the memory take advantage of domain shifts and record prototypical patterns of the target distribution. Further, MemXformer produces strong positive and negative pairs to guide a novel contrastive loss, which enhances target specific representation learning. Experiments on diverse detection benchmarks show that the proposed strategy can produce state-of-the-art performance in both online and offline settings. To the best of our knowledge, this is the first work to address online and offline adaptation settings for object detection. Code at https://github.com/Vibashan/online-od