 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Hybrid Captioner for Improved Long-form Video Understanding
Jul 22, 2025Video data, especially long-form video, is extremely dense and high-dimensional. Text-based summaries of video content offer a way to represent query-relevant content in a much more compact manner than raw video. In addition, textual representations are easily ingested by state-of-the-art large language models (LLMs), which enable reasoning over video content to answer complex natural language queries. To solve this issue, we rely on the progressive construction of a text-based memory by a video captioner operating on shorter chunks of the video, where spatio-temporal modeling is computationally feasible. We explore ways to improve the quality of the activity log comprised solely of short video captions. Because the video captions tend to be focused on human actions, and questions may pertain to other information in the scene, we seek to enrich the memory with static scene descriptions using Vision Language Models (VLMs). Our video understanding system relies on the LaViLa video captioner in combination with a LLM to answer questions about videos. We first explored different ways of partitioning the video into meaningful segments such that the textual descriptions more accurately reflect the structure of the video content. Furthermore, we incorporated static scene descriptions into the captioning pipeline using LLaVA VLM, resulting in a more detailed and complete caption log and expanding the space of questions that are answerable from the textual memory. Finally, we have successfully fine-tuned the LaViLa video captioner to produce both action and scene captions, significantly improving the efficiency of the captioning pipeline compared to using separate captioning models for the two tasks. Our model, controllable hybrid captioner, can alternate between different types of captions according to special input tokens that signals scene changes detected in the video.
MMMORRF: Multimodal Multilingual Modularized Reciprocal Rank Fusion
Mar 26, 2025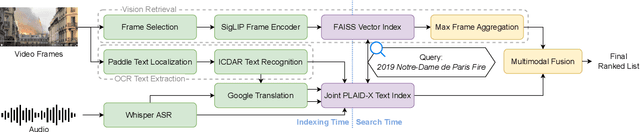


Videos inherently contain multiple modalities, including visual events, text overlays, sounds, and speech, all of which are important for retrieval. However, state-of-the-art multimodal language models like VAST and LanguageBind are built on vision-language models (VLMs), and thus overly prioritize visual signals. Retrieval benchmarks further reinforce this bias by focusing on visual queries and neglecting other modalities. We create a search system MMMORRF that extracts text and features from both visual and audio modalities and integrates them with a novel modality-aware weighted reciprocal rank fusion. MMMORRF is both effective and efficient, demonstrating practicality in searching videos based on users' information needs instead of visual descriptive queries. We evaluate MMMORRF on MultiVENT 2.0 and TVR, two multimodal benchmarks designed for more targeted information needs, and find that it improves nDCG@20 by 81% over leading multimodal encoders and 37% over single-modality retrieval, demonstrating the value of integrating diverse modalities.
Video-ColBERT: Contextualized Late Interaction for Text-to-Video Retrieval
Mar 24, 2025In this work, we tackle the problem of text-to-video retrieval (T2VR). Inspired by the success of late interaction techniques in text-document, text-image, and text-video retrieval, our approach, Video-ColBERT, introduces a simple and efficient mechanism for fine-grained similarity assessment between queries and videos. Video-ColBERT is built upon 3 main components: a fine-grained spatial and temporal token-wise interaction, query and visual expansions, and a dual sigmoid loss during training. We find that this interaction and training paradigm leads to strong individual, yet compatible, representations for encoding video content. These representations lead to increases in performance on common text-to-video retrieval benchmarks compared to other bi-encoder methods.
An Evaluation of Large Pre-Trained Models for Gesture Recognition using Synthetic Videos
Oct 03, 2024In this work, we explore the possibility of using synthetically generated data for video-based gesture recognition with large pre-trained models. We consider whether these models have sufficiently robust and expressive representation spaces to enable "training-free" classification. Specifically, we utilize various state-of-the-art video encoders to extract features for use in k-nearest neighbors classification, where the training data points are derived from synthetic videos only. We compare these results with another training-free approach -- zero-shot classification using text descriptions of each gesture. In our experiments with the RoCoG-v2 dataset, we find that using synthetic training videos yields significantly lower classification accuracy on real test videos compared to using a relatively small number of real training videos. We also observe that video backbones that were fine-tuned on classification tasks serve as superior feature extractors, and that the choice of fine-tuning data has a substantial impact on k-nearest neighbors performance. Lastly, we find that zero-shot text-based classification performs poorly on the gesture recognition task, as gestures are not easily described through natural language.
* Synthetic Data for Artificial Intelligence and Machine Learning: Tools, Techniques, and Applications II (SPIE Defense + Commercial Sensing, 2024)
Unsupervised Video Domain Adaptation with Masked Pre-Training and Collaborative Self-Training
Dec 06, 2023



In this work, we tackle the problem of unsupervised domain adaptation (UDA) for video action recognition. Our approach, which we call UNITE, uses an image teacher model to adapt a video student model to the target domain. UNITE first employs self-supervised pre-training to promote discriminative feature learning on target domain videos using a teacher-guided masked distillation objective. We then perform self-training on masked target data, using the video student model and image teacher model together to generate improved pseudolabels for unlabeled target videos. Our self-training process successfully leverages the strengths of both models to achieve strong transfer performance across domains. We evaluate our approach on multiple video domain adaptation benchmarks and observe significant improvements upon previously reported results.