 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Token-Level Credit Assignment in RLVR: A Polarity-Entropy Analysis
Apr 13, 2026Reinforcement Learning with Verifiable Rewards (RLVR) has substantially improved the reasoning ability of Large Language Models (LLMs). However, its sparse outcome-based rewards pose a fundamental credit assignment problem. We analyze this problem through the joint lens of reward polarity and token entropy. Our diagnostic tool, the Four Quadrant Decomposition, isolates token updates by polarity and entropy, and controlled ablations show that reasoning improvements concentrate in the high-entropy quadrants. To justify this observation theoretically, we adapt Conditional Mutual Information to the autoregressive RLVR setting and prove that the credit a token can carry is upper-bounded by its entropy. This view yields testable predictions that reasoning gains arise primarily from high-entropy tokens, with unique roles for positive and negative updates. A gradient analysis of GRPO further reveals how uniform reward broadcast dilutes signal at high-entropy positions while over-crediting deterministic tokens. Grounded in these insights, we propose Entropy-Aware Policy Optimization (EAPO) that modulates token-level learning signals accordingly. Extensive experiments demonstrate that EAPO outperforms strong baselines across two model families.
Latent Bias Alignment for High-Fidelity Diffusion Inversion in Real-World Image Reconstruction and Manipulation
Mar 25, 2026Recent research has shown that text-to-image diffusion models are capable of generating high-quality images guided by text prompts. But can they be used to generate or approximate real-world images from the seed noise? This is known as the diffusion inversion problem, which serves as a fundamental building block for bridging diffusion models and real-world scenarios. However, existing diffusion inversion methods often suffer from low reconstruction quality or weak robustness. Two major challenges need to be carefully addressed: (1) the misalignment between the inversion and generation trajectories during the diffusion process, and (2) the mismatch between the diffusion inversion process and the VQ autoencoder (VQAE) reconstruction. To address these challenges, we introduce a latent bias vector at each inversion step, which is learned to reduce the misalignment between inversion and generation trajectories. We refer to this strategy as Latent Bias Optimization (LBO). Furthermore, we perform an approximate joint optimization of the diffusion inversion and VQAE reconstruction processes by learning to adjust the image latent representation, which serves as the connecting interface between them. We refer to this technique as Image Latent Boosting (ILB). Extensive experimental results demonstrate that the proposed method significantly improves the image reconstruction quality of the diffusion model, as well as the performance of downstream tasks, including image editing and rare concept generation.
CoCoEmo: Composable and Controllable Human-Like Emotional TTS via Activation Steering
Feb 03, 2026Emotional expression in human speech is nuanced and compositional, often involving multiple, sometimes conflicting, affective cues that may diverge from linguistic content. In contrast, most expressive text-to-speech systems enforce a single utterance-level emotion, collapsing affective diversity and suppressing mixed or text-emotion-misaligned expression. While activation steering via latent direction vectors offers a promising solution, it remains unclear whether emotion representations are linearly steerable in TTS, where steering should be applied within hybrid TTS architectures, and how such complex emotion behaviors should be evaluated. This paper presents the first systematic analysis of activation steering for emotional control in hybrid TTS models, introducing a quantitative, controllable steering framework, and multi-rater evaluation protocols that enable composable mixed-emotion synthesis and reliable text-emotion mismatch synthesis. Our results demonstrate, for the first time, that emotional prosody and expressive variability are primarily synthesized by the TTS language module instead of the flow-matching module, and also provide a lightweight steering approach for generating natural, human-like emotional speech.
Retrieval-Infused Reasoning Sandbox: A Benchmark for Decoupling Retrieval and Reasoning Capabilities
Jan 29, 2026Despite strong performance on existing benchmarks, it remains unclear whether large language models can reason over genuinely novel scientific information. Most evaluations score end-to-end RAG pipelines, where reasoning is confounded with retrieval and toolchain choices, and the signal is further contaminated by parametric memorization and open-web volatility. We introduce DeR2, a controlled deep-research sandbox that isolates document-grounded reasoning while preserving core difficulties of deep search: multi-step synthesis, denoising, and evidence-based conclusion making. DeR2 decouples evidence access from reasoning via four regimes--Instruction-only, Concepts (gold concepts without documents), Related-only (only relevant documents), and Full-set (relevant documents plus topically related distractors)--yielding interpretable regime gaps that operationalize retrieval loss vs. reasoning loss and enable fine-grained error attribution. To prevent parametric leakage, we apply a two-phase validation that requires parametric failure without evidence while ensuring oracle-concept solvability. To ensure reproducibility, each instance provides a frozen document library (drawn from 2023-2025 theoretical papers) with expert-annotated concepts and validated rationales. Experiments across a diverse set of state-of-the-art foundation models reveal substantial variation and significant headroom: some models exhibit mode-switch fragility, performing worse with the Full-set than with Instruction-only, while others show structural concept misuse, correctly naming concepts but failing to execute them as procedures.
Unbiased Visual Reasoning with Controlled Visual Inputs
Dec 19, 2025End-to-end Vision-language Models (VLMs) often answer visual questions by exploiting spurious correlations instead of causal visual evidence, and can become more shortcut-prone when fine-tuned. We introduce VISTA (Visual-Information Separation for Text-based Analysis), a modular framework that decouples perception from reasoning via an explicit information bottleneck. A frozen VLM sensor is restricted to short, objective perception queries, while a text-only LLM reasoner decomposes each question, plans queries, and aggregates visual facts in natural language. This controlled interface defines a reward-aligned environment for training unbiased visual reasoning with reinforcement learning. Instantiated with Qwen2.5-VL and Llama3.2-Vision sensors, and trained with GRPO from only 641 curated multi-step questions, VISTA significantly improves robustness to real-world spurious correlations on SpuriVerse (+16.29% with Qwen-2.5-VL-7B and +6.77% with Llama-3.2-Vision-11B), while remaining competitive on MMVP and a balanced SeedBench subset. VISTA transfers robustly across unseen VLM sensors and is able to recognize and recover from VLM perception failures. Human analysis further shows that VISTA's reasoning traces are more neutral, less reliant on spurious attributes, and more explicitly grounded in visual evidence than end-to-end VLM baselines.
Learning Human-Perceived Fakeness in AI-Generated Videos via Multimodal LLMs
Sep 26, 2025Can humans identify AI-generated (fake) videos and provide grounded reasons? While video generation models have advanced rapidly, a critical dimension -- whether humans can detect deepfake traces within a generated video, i.e., spatiotemporal grounded visual artifacts that reveal a video as machine generated -- has been largely overlooked. We introduce DeeptraceReward, the first fine-grained, spatially- and temporally- aware benchmark that annotates human-perceived fake traces for video generation reward. The dataset comprises 4.3K detailed annotations across 3.3K high-quality generated videos. Each annotation provides a natural-language explanation, pinpoints a bounding-box region containing the perceived trace, and marks precise onset and offset timestamps. We consolidate these annotations into 9 major categories of deepfake traces that lead humans to identify a video as AI-generated, and train multimodal language models (LMs) as reward models to mimic human judgments and localizations. On DeeptraceReward, our 7B reward model outperforms GPT-5 by 34.7% on average across fake clue identification, grounding, and explanation. Interestingly, we observe a consistent difficulty gradient: binary fake v.s. real classification is substantially easier than fine-grained deepfake trace detection; within the latter, performance degrades from natural language explanations (easiest), to spatial grounding, to temporal labeling (hardest). By foregrounding human-perceived deepfake traces, DeeptraceReward provides a rigorous testbed and training signal for socially aware and trustworthy video generation.
Mixture of Length and Pruning Experts for Knowledge Graphs Reasoning
Jul 28, 2025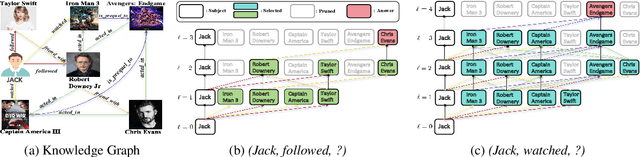
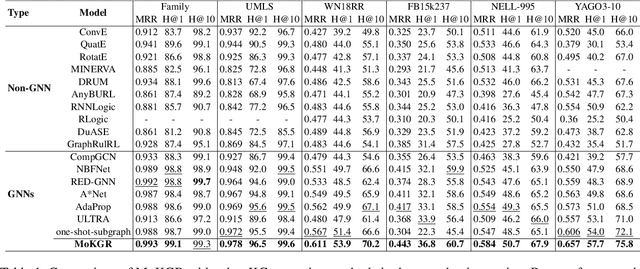
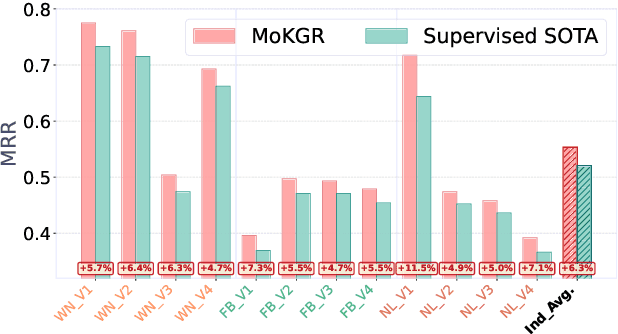
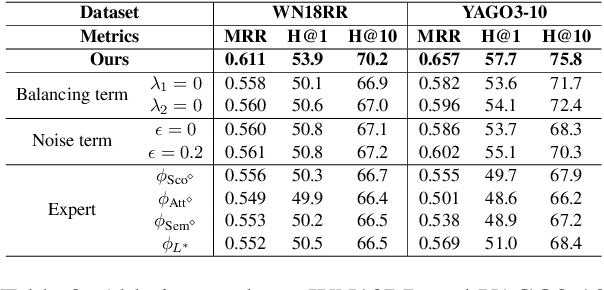
Knowledge Graph (KG) reasoning, which aims to infer new facts from structured knowledge repositories, plays a vital role in Natural Language Processing (NLP) systems. Its effectiveness critically depends on constructing informative and contextually relevant reasoning paths. However, existing graph neural networks (GNNs) often adopt rigid, query-agnostic path-exploration strategies, limiting their ability to adapt to diverse linguistic contexts and semantic nuances. To address these limitations, we propose \textbf{MoKGR}, a mixture-of-experts framework that personalizes path exploration through two complementary components: (1) a mixture of length experts that adaptively selects and weights candidate path lengths according to query complexity, providing query-specific reasoning depth; and (2) a mixture of pruning experts that evaluates candidate paths from a complementary perspective, retaining the most informative paths for each query. Through comprehensive experiments on diverse benchmark, MoKGR demonstrates superior performance in both transductive and inductive settings, validating the effectiveness of personalized path exploration in KGs reasoning.
GraphOracle: A Foundation Model for Knowledge Graph Reasoning
May 16, 2025
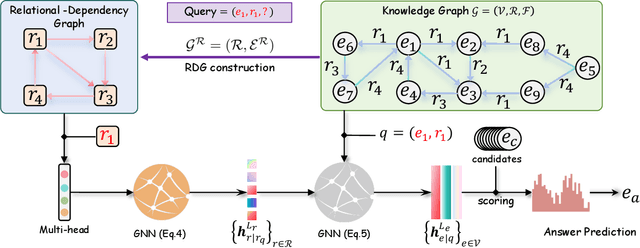
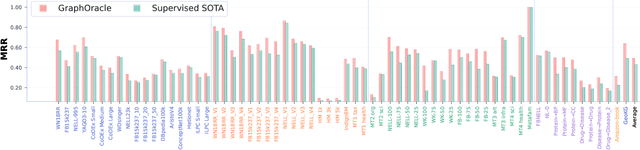

Foundation models have demonstrated remarkable capabilities across various domains, but developing analogous models for knowledge graphs presents unique challenges due to their dynamic nature and the need for cross-domain reasoning. To address these issues, we introduce \textbf{\textsc{GraphOracle}}, a relation-centric foundation model that unifies reasoning across knowledge graphs by converting them into Relation-Dependency Graphs (RDG), explicitly encoding compositional patterns with fewer edges than prior methods. A query-dependent attention mechanism is further developed to learn inductive representations for both relations and entities. Pre-training on diverse knowledge graphs, followed by minutes-level fine-tuning, enables effective generalization to unseen entities, relations, and entire graphs. Through comprehensive experiments on 31 diverse benchmarks spanning transductive, inductive, and cross-domain settings, we demonstrate consistent state-of-the-art performance with minimal adaptation, improving the prediction performance by up to 35\% compared to the strongest baselines.
Towards Long Context Hallucination Detection
Apr 28, 2025Large Language Models (LLMs) have demonstrated remarkable performance across various tasks. However, they are prone to contextual hallucination, generating information that is either unsubstantiated or contradictory to the given context. Although many studies have investigated contextual hallucinations in LLMs, addressing them in long-context inputs remains an open problem. In this work, we take an initial step toward solving this problem by constructing a dataset specifically designed for long-context hallucination detection. Furthermore, we propose a novel architecture that enables pre-trained encoder models, such as BERT, to process long contexts and effectively detect contextual hallucinations through a decomposition and aggregation mechanism. Our experimental results show that the proposed architecture significantly outperforms previous models of similar size as well as LLM-based models across various metrics, while providing substantially faster inference.
Conflicts in Texts: Data, Implications and Challenges
Apr 28, 2025
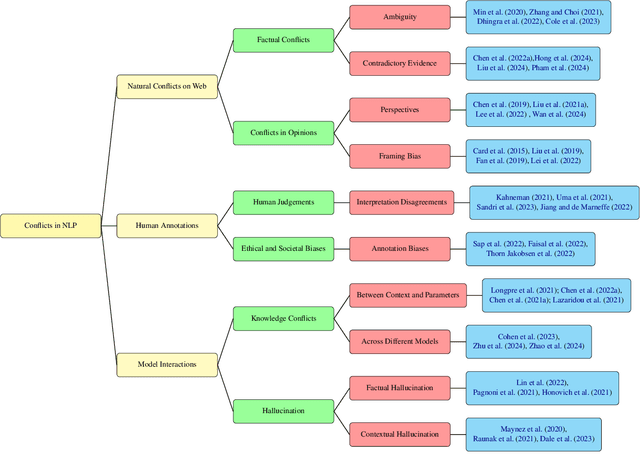
As NLP models become increasingly integrated into real-world applications, it becomes clear that there is a need to address the fact that models often rely on and generate conflicting information. Conflicts could reflect the complexity of situations, changes that need to be explained and dealt with, difficulties in data annotation, and mistakes in generated outputs. In all cases, disregarding the conflicts in data could result in undesired behaviors of models and undermine NLP models' reliability and trustworthiness. This survey categorizes these conflicts into three key areas: (1) natural texts on the web, where factual inconsistencies, subjective biases, and multiple perspectives introduce contradictions; (2) human-annotated data, where annotator disagreements, mistakes, and societal biases impact model training; and (3) model interactions, where hallucinations and knowledge conflicts emerge during deployment. While prior work has addressed some of these conflicts in isolation, we unify them under the broader concept of conflicting information, analyze their implications, and discuss mitigation strategies. We highlight key challenges and future directions for developing conflict-aware NLP systems that can reason over and reconcile conflicting information more effectively.