 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNeuCLIRTech: Chinese Monolingual and Cross-Language Information Retrieval Evaluation in a Challenging Domain
Feb 05, 2026Measuring advances in retrieval requires test collections with relevance judgments that can faithfully distinguish systems. This paper presents NeuCLIRTech, an evaluation collection for cross-language retrieval over technical information. The collection consists of technical documents written natively in Chinese and those same documents machine translated into English. It includes 110 queries with relevance judgments. The collection supports two retrieval scenarios: monolingual retrieval in Chinese, and cross-language retrieval with English as the query language. NeuCLIRTech combines the TREC NeuCLIR track topics of 2023 and 2024. The 110 queries with 35,962 document judgments provide strong statistical discriminatory power when trying to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included so that developers of reranking algorithms are not reliant on BM25 as their first stage retriever. The dataset and artifacts are released on Huggingface Datasets
NeuCLIRBench: A Modern Evaluation Collection for Monolingual, Cross-Language, and Multilingual Information Retrieval
Nov 18, 2025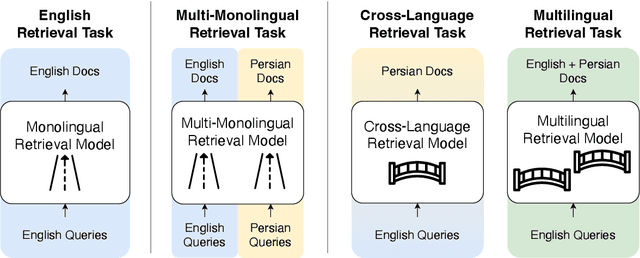

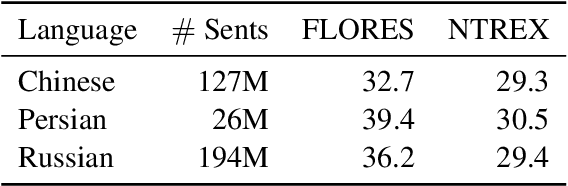
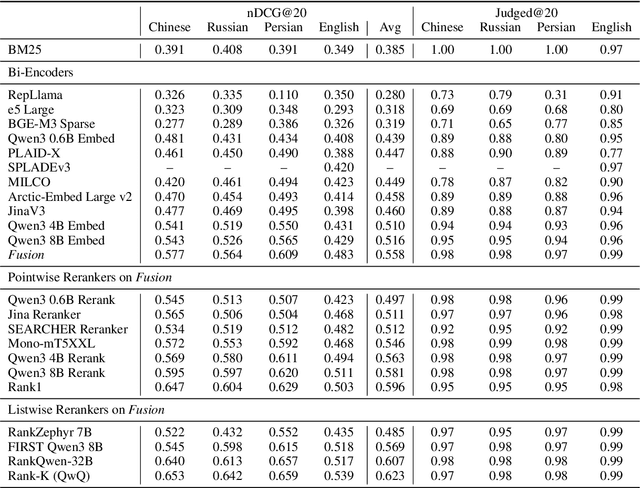
To measure advances in retrieval, test collections with relevance judgments that can faithfully distinguish systems are required. This paper presents NeuCLIRBench, an evaluation collection for cross-language and multilingual retrieval. The collection consists of documents written natively in Chinese, Persian, and Russian, as well as those same documents machine translated into English. The collection supports several retrieval scenarios including: monolingual retrieval in English, Chinese, Persian, or Russian; cross-language retrieval with English as the query language and one of the other three languages as the document language; and multilingual retrieval, again with English as the query language and relevant documents in all three languages. NeuCLIRBench combines the TREC NeuCLIR track topics of 2022, 2023, and 2024. The 250,128 judgments across approximately 150 queries for the monolingual and cross-language tasks and 100 queries for multilingual retrieval provide strong statistical discriminatory power to distinguish retrieval approaches. A fusion baseline of strong neural retrieval systems is included with the collection so that developers of reranking algorithms are no longer reliant on BM25 as their first-stage retriever. NeuCLIRBench is publicly available.
MURR: Model Updating with Regularized Replay for Searching a Document Stream
Apr 14, 2025The Internet produces a continuous stream of new documents and user-generated queries. These naturally change over time based on events in the world and the evolution of language. Neural retrieval models that were trained once on a fixed set of query-document pairs will quickly start misrepresenting newly-created content and queries, leading to less effective retrieval. Traditional statistical sparse retrieval can update collection statistics to reflect these changes in the use of language in documents and queries. In contrast, continued fine-tuning of the language model underlying neural retrieval approaches such as DPR and ColBERT creates incompatibility with previously-encoded documents. Re-encoding and re-indexing all previously-processed documents can be costly. In this work, we explore updating a neural dual encoder retrieval model without reprocessing past documents in the stream. We propose MURR, a model updating strategy with regularized replay, to ensure the model can still faithfully search existing documents without reprocessing, while continuing to update the model for the latest topics. In our simulated streaming environments, we show that fine-tuning models using MURR leads to more effective and more consistent retrieval results than other strategies as the stream of documents and queries progresses.
Translate-Distill: Learning Cross-Language Dense Retrieval by Translation and Distillation
Jan 09, 2024



Prior work on English monolingual retrieval has shown that a cross-encoder trained using a large number of relevance judgments for query-document pairs can be used as a teacher to train more efficient, but similarly effective, dual-encoder student models. Applying a similar knowledge distillation approach to training an efficient dual-encoder model for Cross-Language Information Retrieval (CLIR), where queries and documents are in different languages, is challenging due to the lack of a sufficiently large training collection when the query and document languages differ. The state of the art for CLIR thus relies on translating queries, documents, or both from the large English MS MARCO training set, an approach called Translate-Train. This paper proposes an alternative, Translate-Distill, in which knowledge distillation from either a monolingual cross-encoder or a CLIR cross-encoder is used to train a dual-encoder CLIR student model. This richer design space enables the teacher model to perform inference in an optimized setting, while training the student model directly for CLIR. Trained models and artifacts are publicly available on Huggingface.
Synthetic Cross-language Information Retrieval Training Data
Apr 29, 2023A key stumbling block for neural cross-language information retrieval (CLIR) systems has been the paucity of training data. The appearance of the MS MARCO monolingual training set led to significant advances in the state of the art in neural monolingual retrieval. By translating the MS MARCO documents into other languages using machine translation, this resource has been made useful to the CLIR community. Yet such translation suffers from a number of problems. While MS MARCO is a large resource, it is of fixed size; its genre and domain of discourse are fixed; and the translated documents are not written in the language of a native speaker of the language, but rather in translationese. To address these problems, we introduce the JH-POLO CLIR training set creation methodology. The approach begins by selecting a pair of non-English passages. A generative large language model is then used to produce an English query for which the first passage is relevant and the second passage is not relevant. By repeating this process, collections of arbitrary size can be created in the style of MS MARCO but using naturally-occurring documents in any desired genre and domain of discourse. This paper describes the methodology in detail, shows its use in creating new CLIR training sets, and describes experiments using the newly created training data.
Impact of Subword Pooling Strategy on Cross-lingual Event Detection
Feb 23, 2023



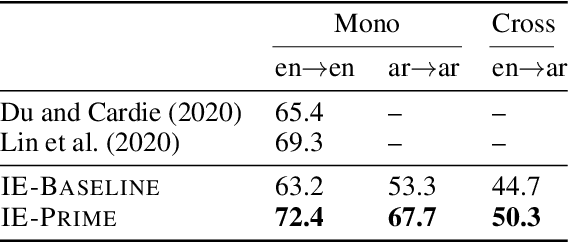
Pre-trained multilingual language models (e.g., mBERT, XLM-RoBERTa) have significantly advanced the state-of-the-art for zero-shot cross-lingual information extraction. These language models ubiquitously rely on word segmentation techniques that break a word into smaller constituent subwords. Therefore, all word labeling tasks (e.g. named entity recognition, event detection, etc.), necessitate a pooling strategy that takes the subword representations as input and outputs a representation for the entire word. Taking the task of cross-lingual event detection as a motivating example, we show that the choice of pooling strategy can have a significant impact on the target language performance. For example, the performance varies by up to 16 absolute $f_{1}$ points depending on the pooling strategy when training in English and testing in Arabic on the ACE task. We carry out our analysis with five different pooling strategies across nine languages in diverse multi-lingual datasets. Across configurations, we find that the canonical strategy of taking just the first subword to represent the entire word is usually sub-optimal. On the other hand, we show that attention pooling is robust to language and dataset variations by being either the best or close to the optimal strategy. For reproducibility, we make our code available at https://github.com/isi-boston/ed-pooling.
Language Model Priming for Cross-Lingual Event Extraction
Sep 25, 2021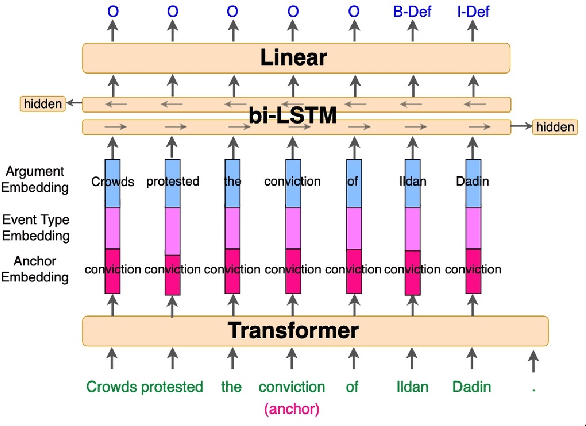
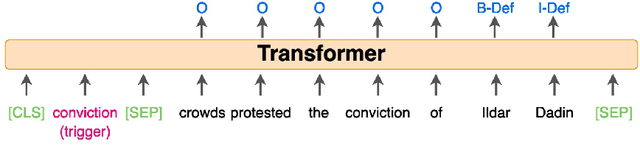

We present a novel, language-agnostic approach to "priming" language models for the task of event extraction, providing particularly effective performance in low-resource and zero-shot cross-lingual settings. With priming, we augment the input to the transformer stack's language model differently depending on the question(s) being asked of the model at runtime. For instance, if the model is being asked to identify arguments for the trigger "protested", we will provide that trigger as part of the input to the language model, allowing it to produce different representations for candidate arguments than when it is asked about arguments for the trigger "arrest" elsewhere in the same sentence. We show that by enabling the language model to better compensate for the deficits of sparse and noisy training data, our approach improves both trigger and argument detection and classification significantly over the state of the art in a zero-shot cross-lingual setting.
Event Extraction as Natural Language Generation
Aug 29, 2021
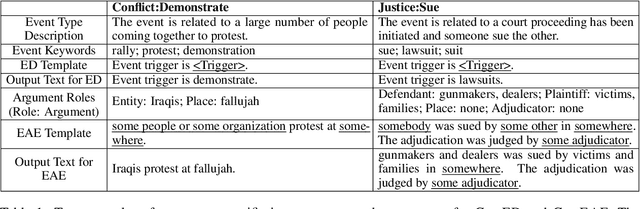
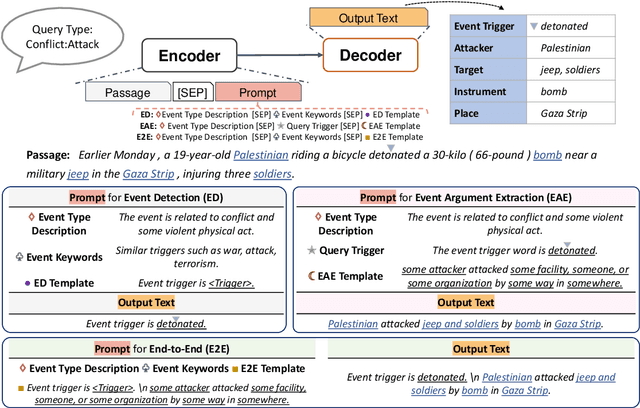
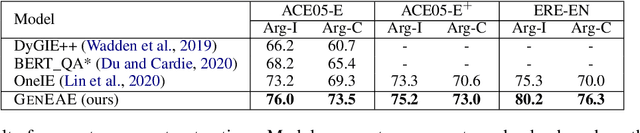
Event extraction (EE), the task that identifies event triggers and their arguments in text, is usually formulated as a classification or structured prediction problem. Such models usually reduce labels to numeric identifiers, making them unable to take advantage of label semantics (e.g. an event type named Arrest is related to words like arrest, detain, or apprehend). This prevents the generalization to new event types. In this work, we formulate EE as a natural language generation task and propose GenEE, a model that not only captures complex dependencies within an event but also generalizes well to unseen or rare event types. Given a passage and an event type, GenEE is trained to generate a natural sentence following a predefined template for that event type. The generated output is then decoded into trigger and argument predictions. The autoregressive generation process naturally models the dependencies among the predictions -- each new word predicted depends on those already generated in the output sentence. Using carefully designed input prompts during generation, GenEE is able to capture label semantics, which enables the generalization to new event types. Empirical results show that our model achieves strong performance on event extraction tasks under all zero-shot, few-shot, and high-resource scenarios. Especially, in the high-resource setting, GenEE outperforms the state-of-the-art model on argument extraction and gets competitive results with the current best on end-to-end EE tasks.
Use of Modality and Negation in Semantically-Informed Syntactic MT
Feb 05, 2015This paper describes the resource- and system-building efforts of an eight-week Johns Hopkins University Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation (SIMT). We describe a new modality/negation (MN) annotation scheme, the creation of a (publicly available) MN lexicon, and two automated MN taggers that we built using the annotation scheme and lexicon. Our annotation scheme isolates three components of modality and negation: a trigger (a word that conveys modality or negation), a target (an action associated with modality or negation) and a holder (an experiencer of modality). We describe how our MN lexicon was semi-automatically produced and we demonstrate that a structure-based MN tagger results in precision around 86% (depending on genre) for tagging of a standard LDC data set. We apply our MN annotation scheme to statistical machine translation using a syntactic framework that supports the inclusion of semantic annotations. Syntactic tags enriched with semantic annotations are assigned to parse trees in the target-language training texts through a process of tree grafting. While the focus of our work is modality and negation, the tree grafting procedure is general and supports other types of semantic information. We exploit this capability by including named entities, produced by a pre-existing tagger, in addition to the MN elements produced by the taggers described in this paper. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English test set. This finding supports the hypothesis that both syntactic and semantic information can improve translation quality.
* 28 pages, 13 figures, 2 tables; appeared in Computational Linguistics, 38(2):411-438, 2012
Semantically-Informed Syntactic Machine Translation: A Tree-Grafting Approach
Sep 24, 2014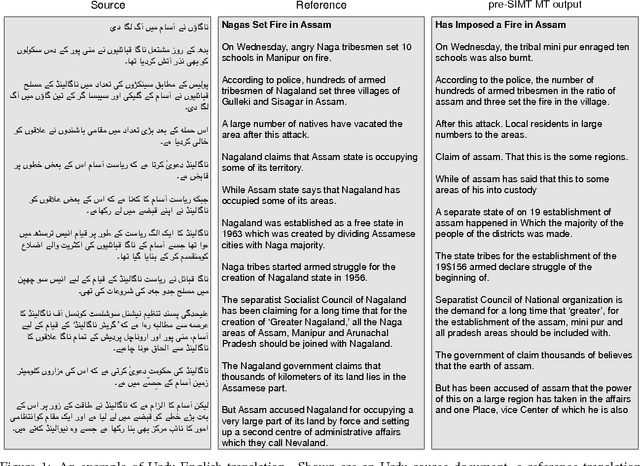
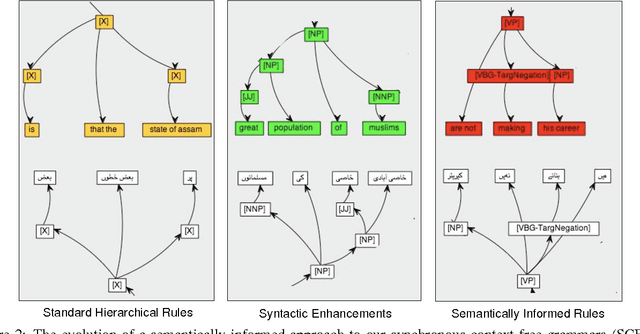

We describe a unified and coherent syntactic framework for supporting a semantically-informed syntactic approach to statistical machine translation. Semantically enriched syntactic tags assigned to the target-language training texts improved translation quality. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English translation task. This finding supports the hypothesis (posed by many researchers in the MT community, e.g., in DARPA GALE) that both syntactic and semantic information are critical for improving translation quality---and further demonstrates that large gains can be achieved for low-resource languages with different word order than English.
* 10 pages, 7 figures, 3 tables; appeared in Proceedings of the Ninth Conference of the Association for Machine Translation in the Americas (AMTA), October 2010