 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUse of Modality and Negation in Semantically-Informed Syntactic MT
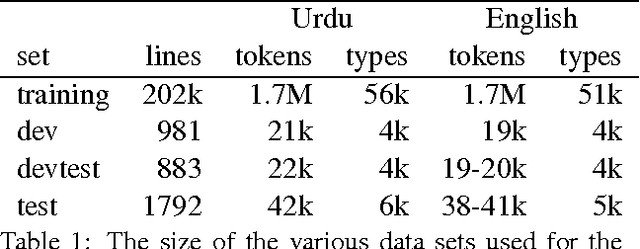
Feb 05, 2015This paper describes the resource- and system-building efforts of an eight-week Johns Hopkins University Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation (SIMT). We describe a new modality/negation (MN) annotation scheme, the creation of a (publicly available) MN lexicon, and two automated MN taggers that we built using the annotation scheme and lexicon. Our annotation scheme isolates three components of modality and negation: a trigger (a word that conveys modality or negation), a target (an action associated with modality or negation) and a holder (an experiencer of modality). We describe how our MN lexicon was semi-automatically produced and we demonstrate that a structure-based MN tagger results in precision around 86% (depending on genre) for tagging of a standard LDC data set. We apply our MN annotation scheme to statistical machine translation using a syntactic framework that supports the inclusion of semantic annotations. Syntactic tags enriched with semantic annotations are assigned to parse trees in the target-language training texts through a process of tree grafting. While the focus of our work is modality and negation, the tree grafting procedure is general and supports other types of semantic information. We exploit this capability by including named entities, produced by a pre-existing tagger, in addition to the MN elements produced by the taggers described in this paper. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English test set. This finding supports the hypothesis that both syntactic and semantic information can improve translation quality.
* 28 pages, 13 figures, 2 tables; appeared in Computational Linguistics, 38(2):411-438, 2012
A Modality Lexicon and its use in Automatic Tagging
Oct 17, 2014

This paper describes our resource-building results for an eight-week JHU Human Language Technology Center of Excellence Summer Camp for Applied Language Exploration (SCALE-2009) on Semantically-Informed Machine Translation. Specifically, we describe the construction of a modality annotation scheme, a modality lexicon, and two automated modality taggers that were built using the lexicon and annotation scheme. Our annotation scheme is based on identifying three components of modality: a trigger, a target and a holder. We describe how our modality lexicon was produced semi-automatically, expanding from an initial hand-selected list of modality trigger words and phrases. The resulting expanded modality lexicon is being made publicly available. We demonstrate that one tagger---a structure-based tagger---results in precision around 86% (depending on genre) for tagging of a standard LDC data set. In a machine translation application, using the structure-based tagger to annotate English modalities on an English-Urdu training corpus improved the translation quality score for Urdu by 0.3 Bleu points in the face of sparse training data.
* 6 pages, 5 figures; appeared in Proceedings of the Seventh International Conference on Language Resources and Evaluation (LREC'10), May 2010
Semantically-Informed Syntactic Machine Translation: A Tree-Grafting Approach
Sep 24, 2014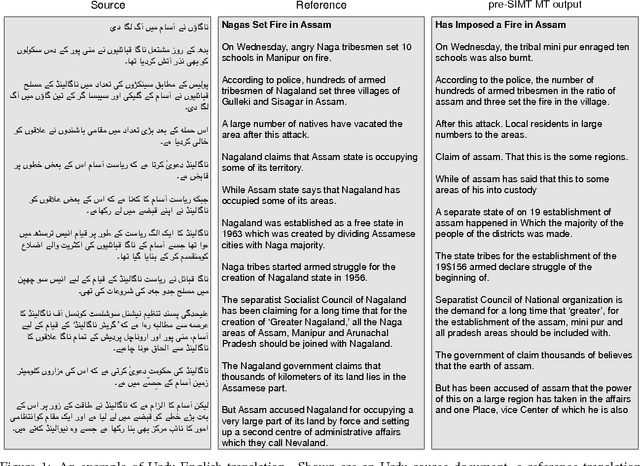
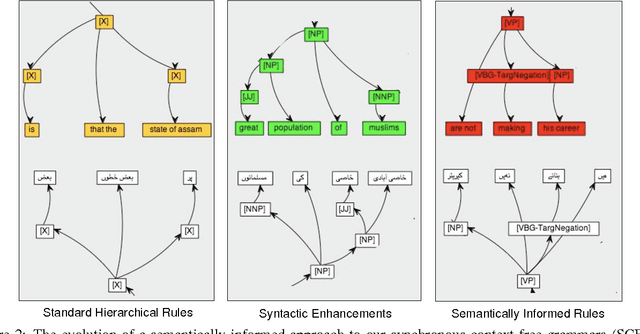

We describe a unified and coherent syntactic framework for supporting a semantically-informed syntactic approach to statistical machine translation. Semantically enriched syntactic tags assigned to the target-language training texts improved translation quality. The resulting system significantly outperformed a linguistically naive baseline model (Hiero), and reached the highest scores yet reported on the NIST 2009 Urdu-English translation task. This finding supports the hypothesis (posed by many researchers in the MT community, e.g., in DARPA GALE) that both syntactic and semantic information are critical for improving translation quality---and further demonstrates that large gains can be achieved for low-resource languages with different word order than English.
* 10 pages, 7 figures, 3 tables; appeared in Proceedings of the Ninth Conference of the Association for Machine Translation in the Americas (AMTA), October 2010