 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Stop Sets on Stopping Active Learning for Text Classification
Jan 08, 2022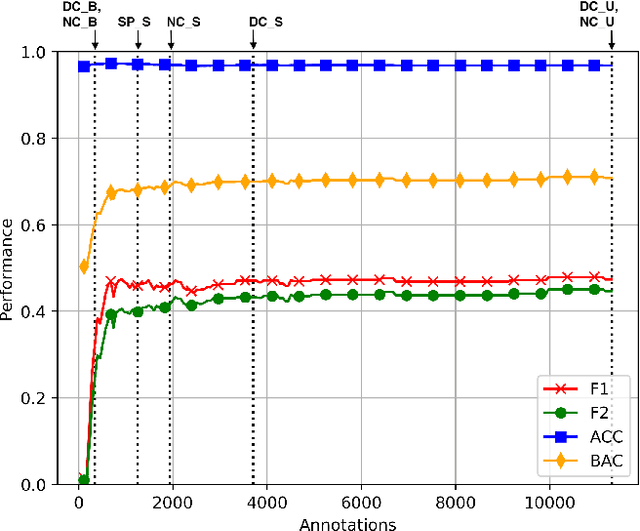

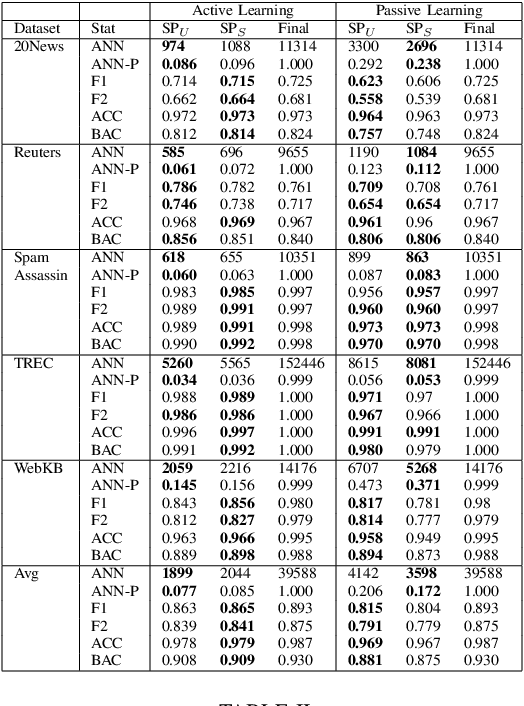
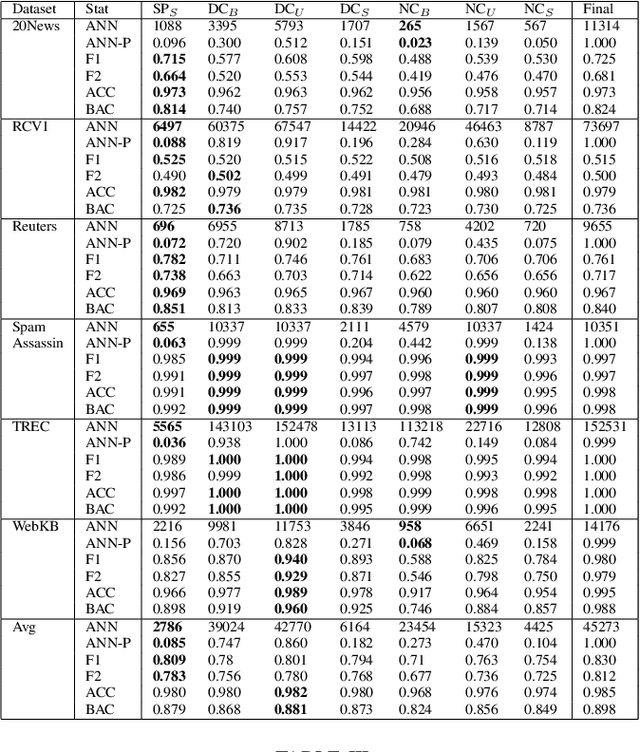
Active learning is an increasingly important branch of machine learning and a powerful technique for natural language processing. The main advantage of active learning is its potential to reduce the amount of labeled data needed to learn high-performing models. A vital aspect of an effective active learning algorithm is the determination of when to stop obtaining additional labeled data. Several leading state-of-the-art stopping methods use a stop set to help make this decision. However, there has been relatively less attention given to the choice of stop set than to the stopping algorithms that are applied on the stop set. Different choices of stop sets can lead to significant differences in stopping method performance. We investigate the impact of different stop set choices on different stopping methods. This paper shows the choice of the stop set can have a significant impact on the performance of stopping methods and the impact is different for stability-based methods from that on confidence-based methods. Furthermore, the unbiased representative stop sets suggested by original authors of methods work better than the systematically biased stop sets used in recently published work, and stopping methods based on stabilizing predictions have stronger performance than confidence-based stopping methods when unbiased representative stop sets are used. We provide the largest quantity of experimental results on the impact of stop sets to date. The findings are important for helping to illuminate the impact of this important aspect of stopping methods that has been under-considered in recently published work and that can have a large practical impact on the performance of stopping methods for important semantic computing applications such as technology assisted review and text classification more broadly.
Early Forecasting of Text Classification Accuracy and F-Measure with Active Learning
Jan 20, 2020
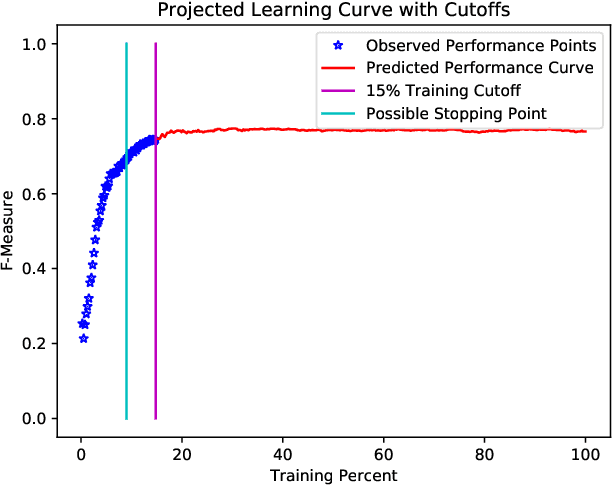
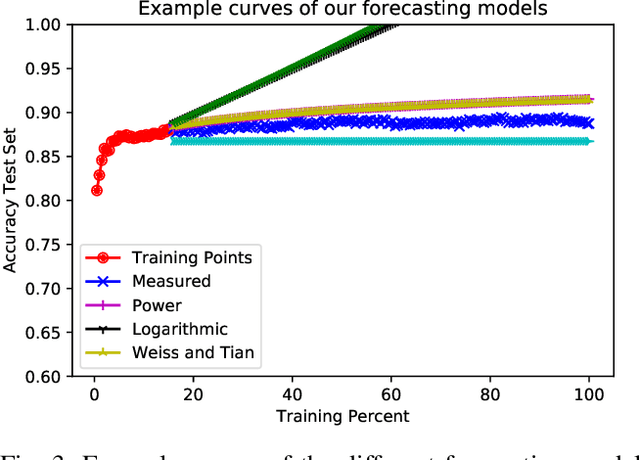
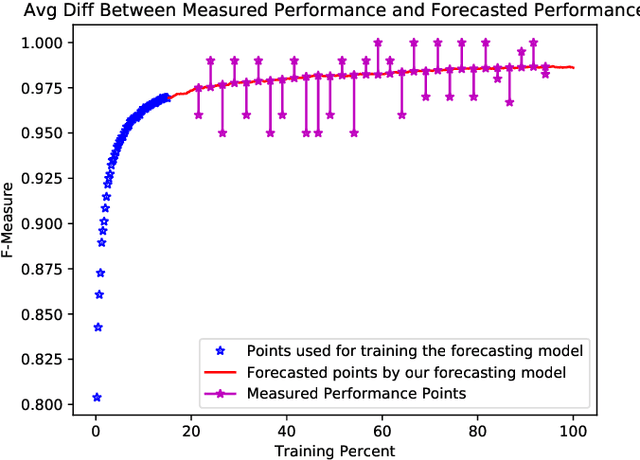
When creating text classification systems, one of the major bottlenecks is the annotation of training data. Active learning has been proposed to address this bottleneck using stopping methods to minimize the cost of data annotation. An important capability for improving the utility of stopping methods is to effectively forecast the performance of the text classification models. Forecasting can be done through the use of logarithmic models regressed on some portion of the data as learning is progressing. A critical unexplored question is what portion of the data is needed for accurate forecasting. There is a tension, where it is desirable to use less data so that the forecast can be made earlier, which is more useful, versus it being desirable to use more data, so that the forecast can be more accurate. We find that when using active learning it is even more important to generate forecasts earlier so as to make them more useful and not waste annotation effort. We investigate the difference in forecasting difficulty when using accuracy and F-measure as the text classification system performance metrics and we find that F-measure is more difficult to forecast. We conduct experiments on seven text classification datasets in different semantic domains with different characteristics and with three different base machine learning algorithms. We find that forecasting is easiest for decision tree learning, moderate for Support Vector Machines, and most difficult for neural networks.
The Use of Unlabeled Data versus Labeled Data for Stopping Active Learning for Text Classification
Jan 26, 2019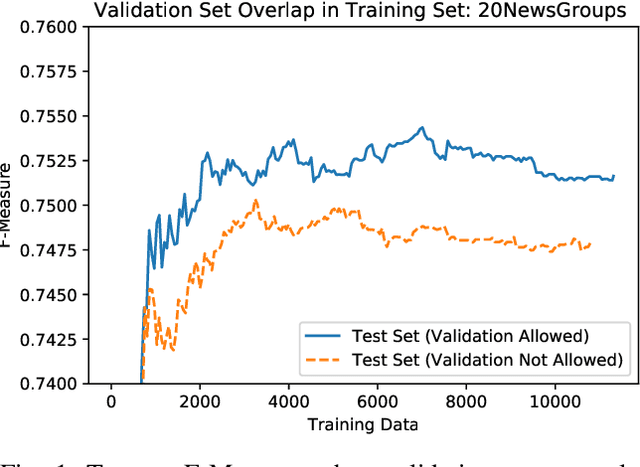
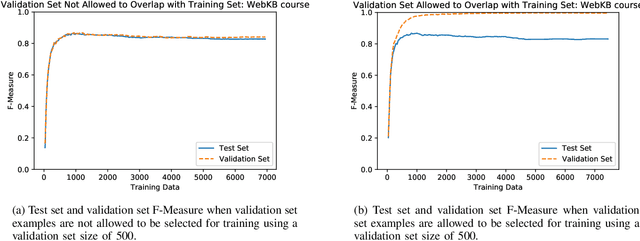
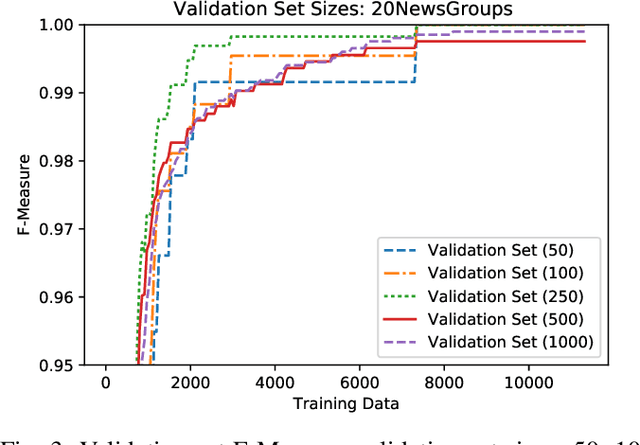
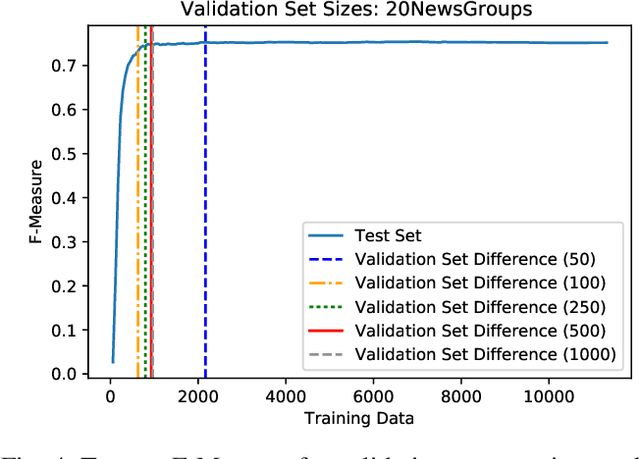
Annotation of training data is the major bottleneck in the creation of text classification systems. Active learning is a commonly used technique to reduce the amount of training data one needs to label. A crucial aspect of active learning is determining when to stop labeling data. Three potential sources for informing when to stop active learning are an additional labeled set of data, an unlabeled set of data, and the training data that is labeled during the process of active learning. To date, no one has compared and contrasted the advantages and disadvantages of stopping methods based on these three information sources. We find that stopping methods that use unlabeled data are more effective than methods that use labeled data.
Stopping Active Learning based on Predicted Change of F Measure for Text Classification
Jan 26, 2019
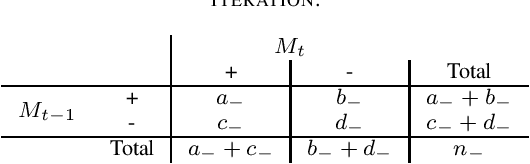
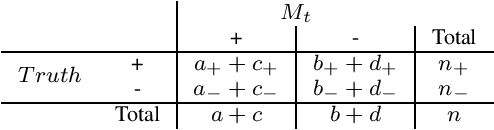
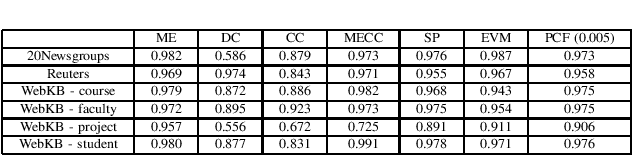
During active learning, an effective stopping method allows users to limit the number of annotations, which is cost effective. In this paper, a new stopping method called Predicted Change of F Measure will be introduced that attempts to provide the users an estimate of how much performance of the model is changing at each iteration. This stopping method can be applied with any base learner. This method is useful for reducing the data annotation bottleneck encountered when building text classification systems.
Support Vector Machine Active Learning Algorithms with Query-by-Committee versus Closest-to-Hyperplane Selection
May 16, 2018
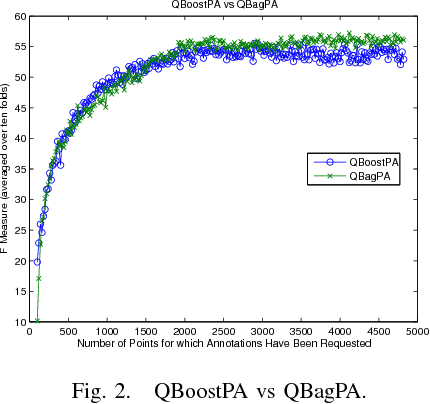
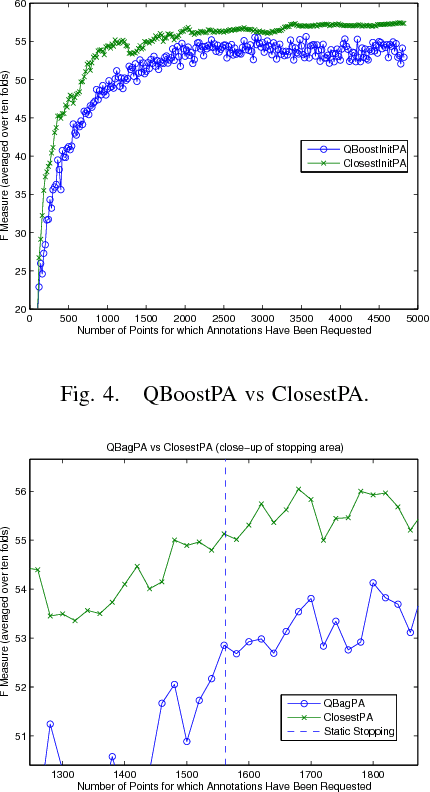
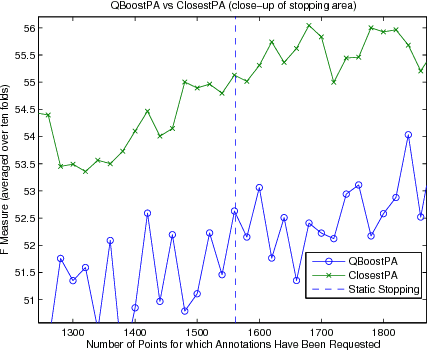
This paper investigates and evaluates support vector machine active learning algorithms for use with imbalanced datasets, which commonly arise in many applications such as information extraction applications. Algorithms based on closest-to-hyperplane selection and query-by-committee selection are combined with methods for addressing imbalance such as positive amplification based on prevalence statistics from initial random samples. Three algorithms (ClosestPA, QBagPA, and QBoostPA) are presented and carefully evaluated on datasets for text classification and relation extraction. The ClosestPA algorithm is shown to consistently outperform the other two in a variety of ways and insights are provided as to why this is the case.
* 8 pages, 7 figures, 3 tables; published in Proceedings of the IEEE 12th International Conference on Semantic Computing (ICSC 2018), Laguna Hills, CA, USA, pages 148-155, January 2018
Impact of Batch Size on Stopping Active Learning for Text Classification
May 16, 2018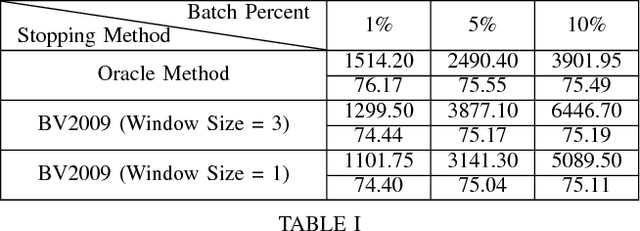
When using active learning, smaller batch sizes are typically more efficient from a learning efficiency perspective. However, in practice due to speed and human annotator considerations, the use of larger batch sizes is necessary. While past work has shown that larger batch sizes decrease learning efficiency from a learning curve perspective, it remains an open question how batch size impacts methods for stopping active learning. We find that large batch sizes degrade the performance of a leading stopping method over and above the degradation that results from reduced learning efficiency. We analyze this degradation and find that it can be mitigated by changing the window size parameter of how many past iterations of learning are taken into account when making the stopping decision. We find that when using larger batch sizes, stopping methods are more effective when smaller window sizes are used.
* 2 pages, 1 table; published in Proceedings of the IEEE 12th International Conference on Semantic Computing (ICSC 2018), Laguna Hills, CA, USA, pages 306-307, January 2018
Acquisition of Translation Lexicons for Historically Unwritten Languages via Bridging Loanwords
Aug 20, 2017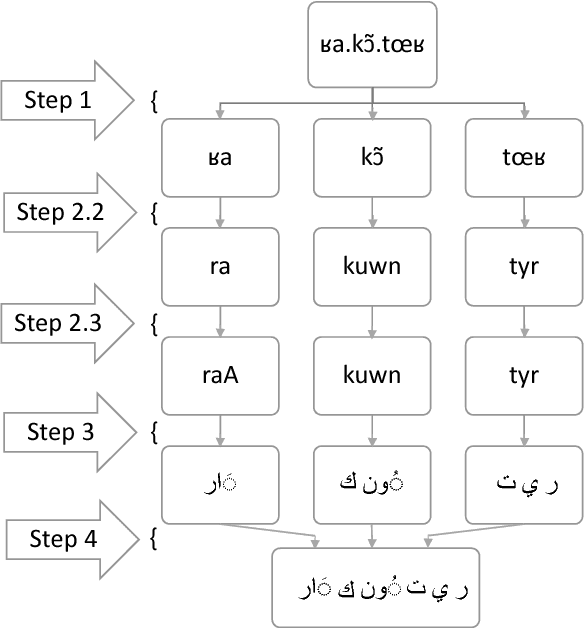

With the advent of informal electronic communications such as social media, colloquial languages that were historically unwritten are being written for the first time in heavily code-switched environments. We present a method for inducing portions of translation lexicons through the use of expert knowledge in these settings where there are approximately zero resources available other than a language informant, potentially not even large amounts of monolingual data. We investigate inducing a Moroccan Darija-English translation lexicon via French loanwords bridging into English and find that a useful lexicon is induced for human-assisted translation and statistical machine translation.
* 5 pages, 1 figure, 1 table; published in the Proceedings of the 10th Workshop on Building and Using Comparable Corpora, pages 21-25, Vancouver, Canada, August 2017
Using Global Constraints and Reranking to Improve Cognates Detection
Aug 19, 2017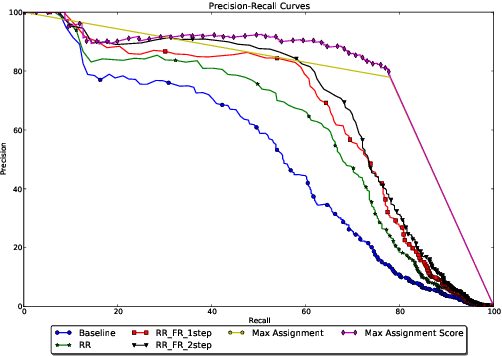
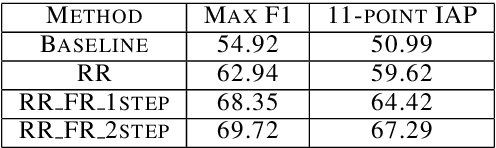
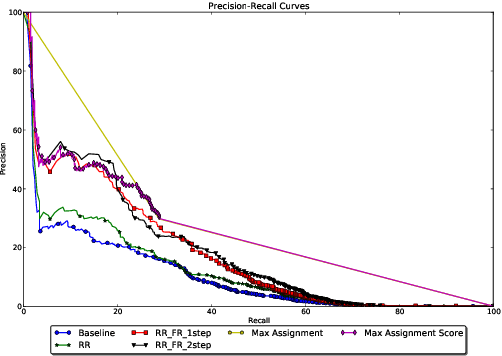
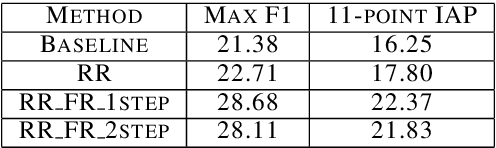
Global constraints and reranking have not been used in cognates detection research to date. We propose methods for using global constraints by performing rescoring of the score matrices produced by state of the art cognates detection systems. Using global constraints to perform rescoring is complementary to state of the art methods for performing cognates detection and results in significant performance improvements beyond current state of the art performance on publicly available datasets with different language pairs and various conditions such as different levels of baseline state of the art performance and different data size conditions, including with more realistic large data size conditions than have been evaluated with in the past.
* 10 pages, 6 figures, 6 tables; published in the Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1983-1992, Vancouver, Canada, July 2017
Filtering Tweets for Social Unrest
Apr 01, 2017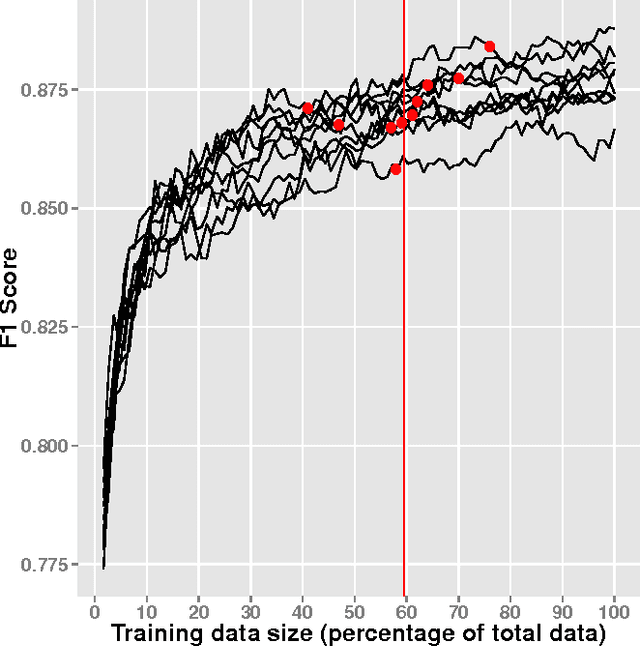
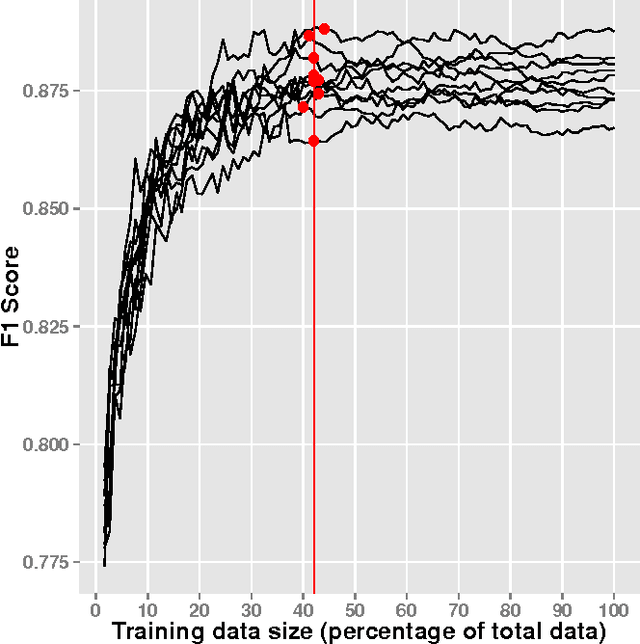
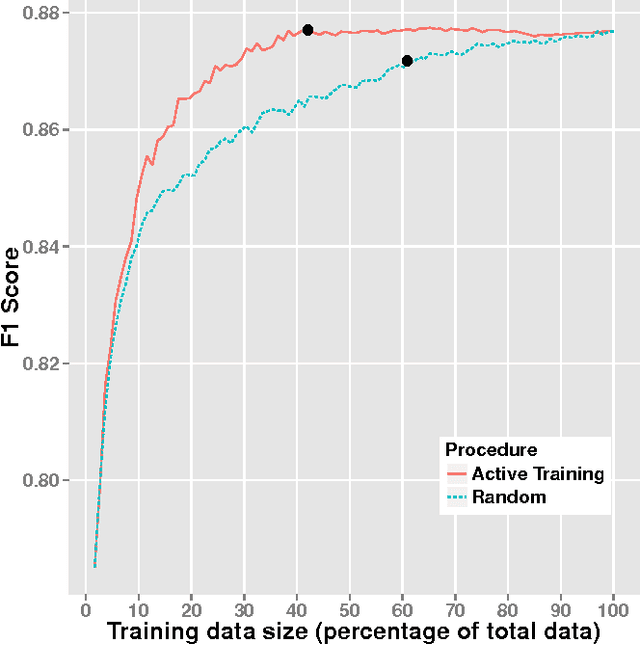
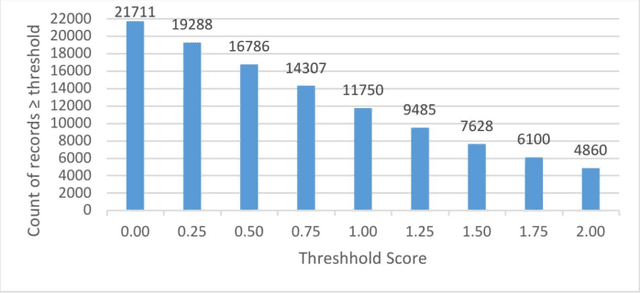
Since the events of the Arab Spring, there has been increased interest in using social media to anticipate social unrest. While efforts have been made toward automated unrest prediction, we focus on filtering the vast volume of tweets to identify tweets relevant to unrest, which can be provided to downstream users for further analysis. We train a supervised classifier that is able to label Arabic language tweets as relevant to unrest with high reliability. We examine the relationship between training data size and performance and investigate ways to optimize the model building process while minimizing cost. We also explore how confidence thresholds can be set to achieve desired levels of performance.
* 7 pages, 8 figures, 3 tables; published in Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, pages 17-23, January 2017
Data Cleaning for XML Electronic Dictionaries via Statistical Anomaly Detection
Apr 11, 2016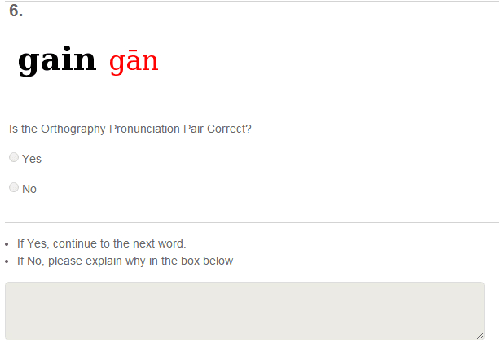
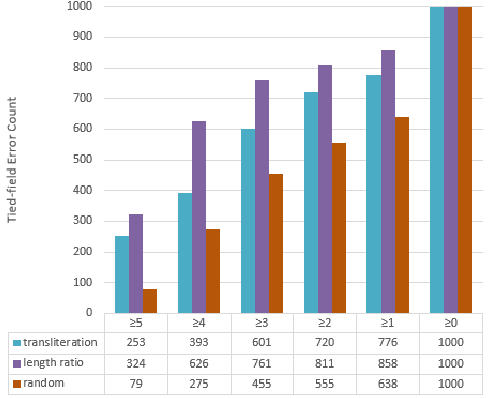
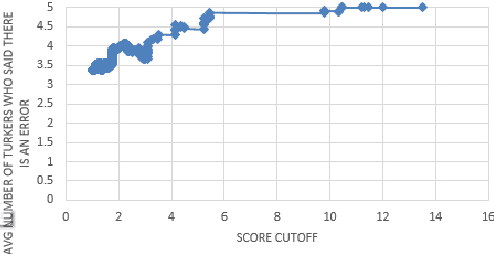
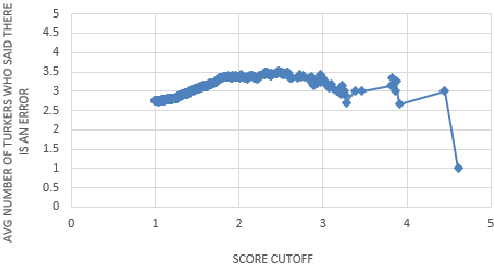
Many important forms of data are stored digitally in XML format. Errors can occur in the textual content of the data in the fields of the XML. Fixing these errors manually is time-consuming and expensive, especially for large amounts of data. There is increasing interest in the research, development, and use of automated techniques for assisting with data cleaning. Electronic dictionaries are an important form of data frequently stored in XML format that frequently have errors introduced through a mixture of manual typographical entry errors and optical character recognition errors. In this paper we describe methods for flagging statistical anomalies as likely errors in electronic dictionaries stored in XML format. We describe six systems based on different sources of information. The systems detect errors using various signals in the data including uncommon characters, text length, character-based language models, word-based language models, tied-field length ratios, and tied-field transliteration models. Four of the systems detect errors based on expectations automatically inferred from content within elements of a single field type. We call these single-field systems. Two of the systems detect errors based on correspondence expectations automatically inferred from content within elements of multiple related field types. We call these tied-field systems. For each system, we provide an intuitive analysis of the type of error that it is successful at detecting. Finally, we describe two larger-scale evaluations using crowdsourcing with Amazon's Mechanical Turk platform and using the annotations of a domain expert. The evaluations consistently show that the systems are useful for improving the efficiency with which errors in XML electronic dictionaries can be detected.
* 8 pages, 4 figures, 5 tables; published in Proceedings of the 2016 IEEE Tenth International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, pages 79-86, February 2016