 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Use of Unlabeled Data versus Labeled Data for Stopping Active Learning for Text Classification
Jan 26, 2019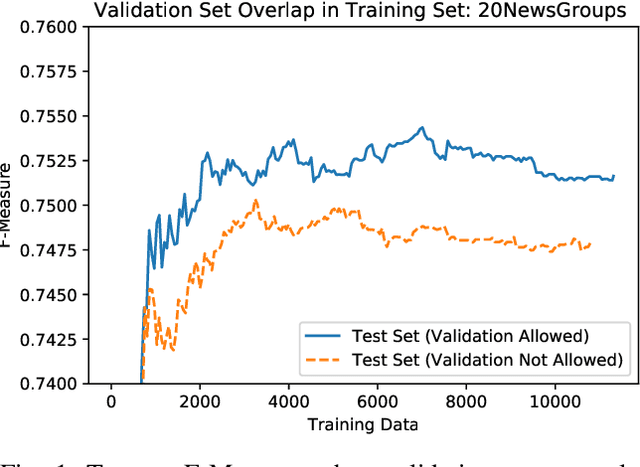
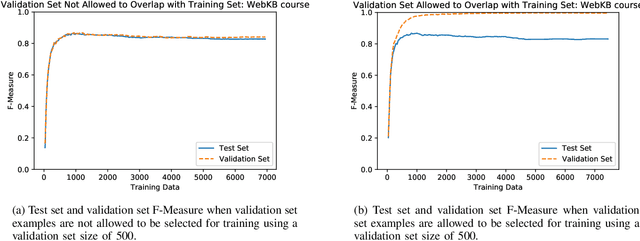
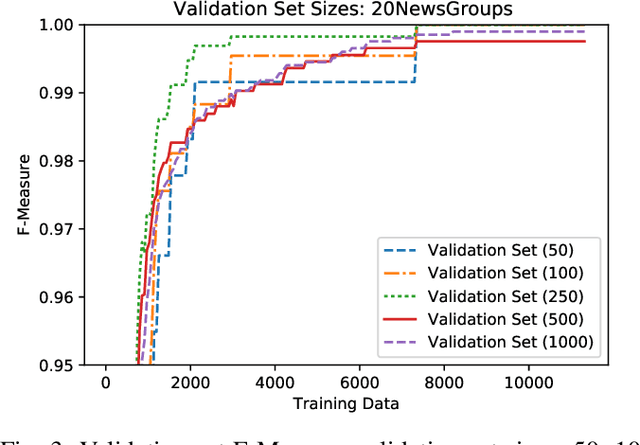
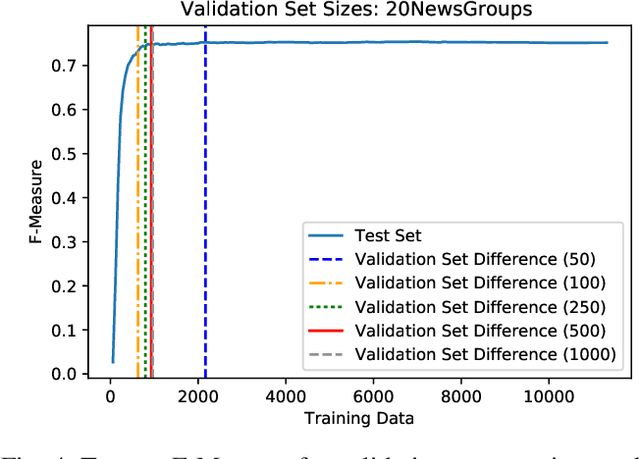
Annotation of training data is the major bottleneck in the creation of text classification systems. Active learning is a commonly used technique to reduce the amount of training data one needs to label. A crucial aspect of active learning is determining when to stop labeling data. Three potential sources for informing when to stop active learning are an additional labeled set of data, an unlabeled set of data, and the training data that is labeled during the process of active learning. To date, no one has compared and contrasted the advantages and disadvantages of stopping methods based on these three information sources. We find that stopping methods that use unlabeled data are more effective than methods that use labeled data.
Impact of Batch Size on Stopping Active Learning for Text Classification
May 16, 2018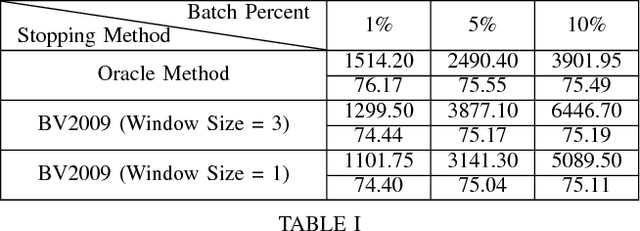
When using active learning, smaller batch sizes are typically more efficient from a learning efficiency perspective. However, in practice due to speed and human annotator considerations, the use of larger batch sizes is necessary. While past work has shown that larger batch sizes decrease learning efficiency from a learning curve perspective, it remains an open question how batch size impacts methods for stopping active learning. We find that large batch sizes degrade the performance of a leading stopping method over and above the degradation that results from reduced learning efficiency. We analyze this degradation and find that it can be mitigated by changing the window size parameter of how many past iterations of learning are taken into account when making the stopping decision. We find that when using larger batch sizes, stopping methods are more effective when smaller window sizes are used.
* 2 pages, 1 table; published in Proceedings of the IEEE 12th International Conference on Semantic Computing (ICSC 2018), Laguna Hills, CA, USA, pages 306-307, January 2018