Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Use of Unlabeled Data versus Labeled Data for Stopping Active Learning for Text Classification
Paper and Code
Jan 26, 2019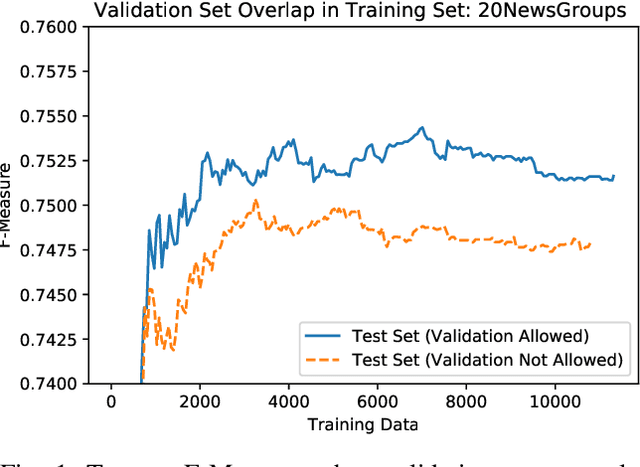
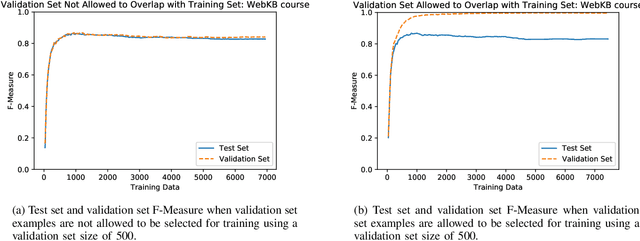
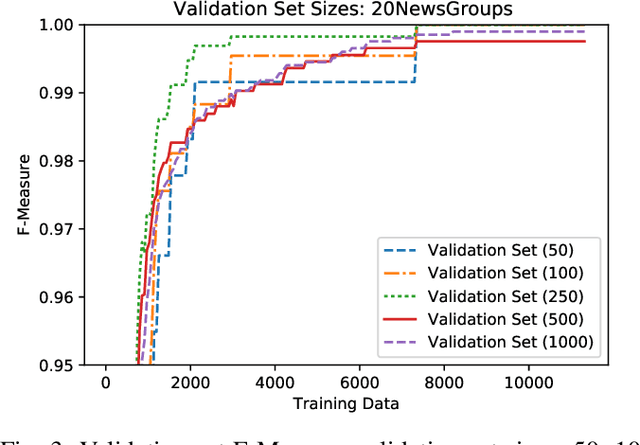
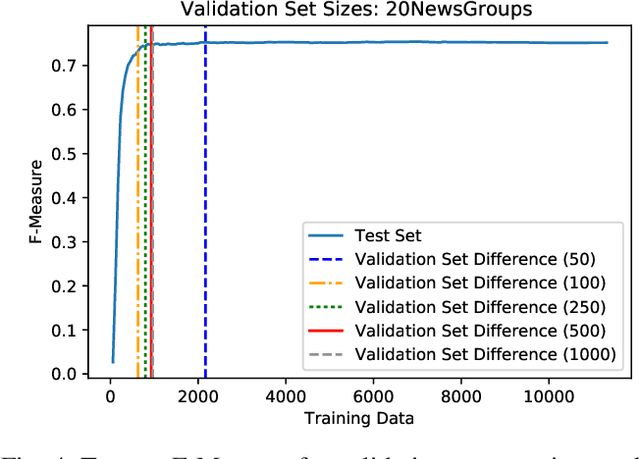
Annotation of training data is the major bottleneck in the creation of text classification systems. Active learning is a commonly used technique to reduce the amount of training data one needs to label. A crucial aspect of active learning is determining when to stop labeling data. Three potential sources for informing when to stop active learning are an additional labeled set of data, an unlabeled set of data, and the training data that is labeled during the process of active learning. To date, no one has compared and contrasted the advantages and disadvantages of stopping methods based on these three information sources. We find that stopping methods that use unlabeled data are more effective than methods that use labeled data.
* 8 pages, 4 figures, 3 tables; to appear in Proceedings of the IEEE
13th International Conference on Semantic Computing (ICSC 2019), Newport
Beach, California, 2019
View paper on