 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAcquisition of Translation Lexicons for Historically Unwritten Languages via Bridging Loanwords
Aug 20, 2017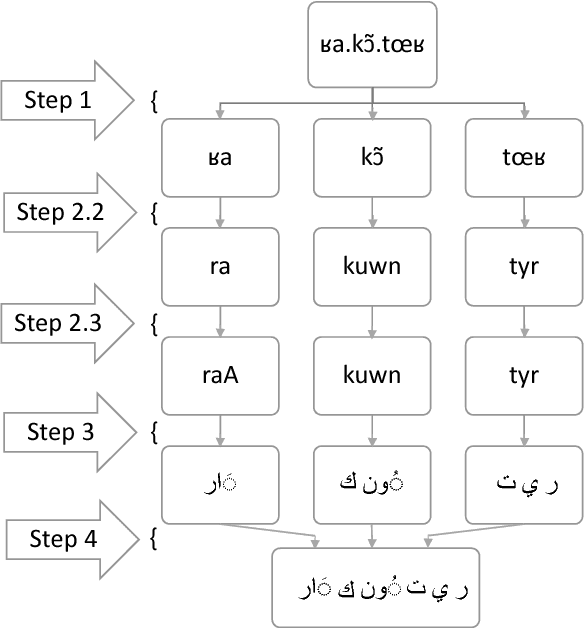

With the advent of informal electronic communications such as social media, colloquial languages that were historically unwritten are being written for the first time in heavily code-switched environments. We present a method for inducing portions of translation lexicons through the use of expert knowledge in these settings where there are approximately zero resources available other than a language informant, potentially not even large amounts of monolingual data. We investigate inducing a Moroccan Darija-English translation lexicon via French loanwords bridging into English and find that a useful lexicon is induced for human-assisted translation and statistical machine translation.
* 5 pages, 1 figure, 1 table; published in the Proceedings of the 10th Workshop on Building and Using Comparable Corpora, pages 21-25, Vancouver, Canada, August 2017
Using Global Constraints and Reranking to Improve Cognates Detection
Aug 19, 2017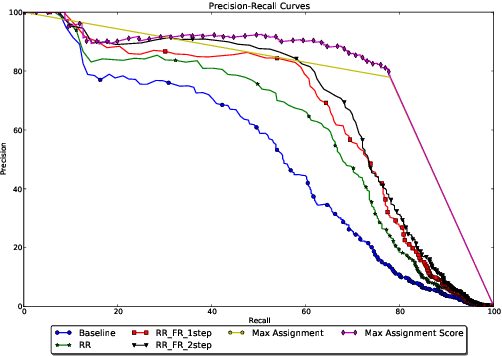
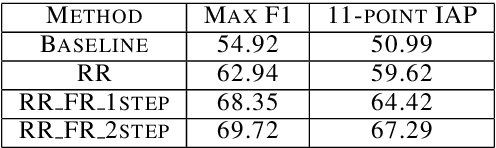
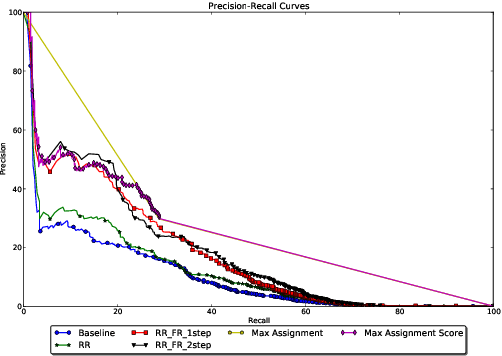
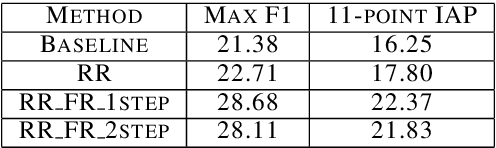
Global constraints and reranking have not been used in cognates detection research to date. We propose methods for using global constraints by performing rescoring of the score matrices produced by state of the art cognates detection systems. Using global constraints to perform rescoring is complementary to state of the art methods for performing cognates detection and results in significant performance improvements beyond current state of the art performance on publicly available datasets with different language pairs and various conditions such as different levels of baseline state of the art performance and different data size conditions, including with more realistic large data size conditions than have been evaluated with in the past.
* 10 pages, 6 figures, 6 tables; published in the Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, pages 1983-1992, Vancouver, Canada, July 2017
Data Cleaning for XML Electronic Dictionaries via Statistical Anomaly Detection
Apr 11, 2016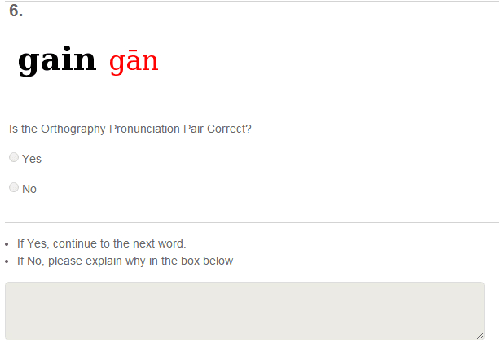
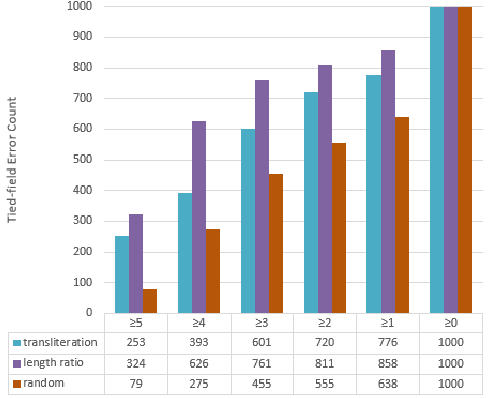
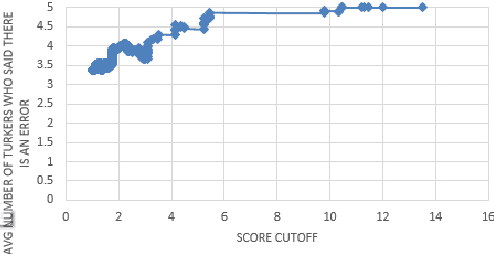
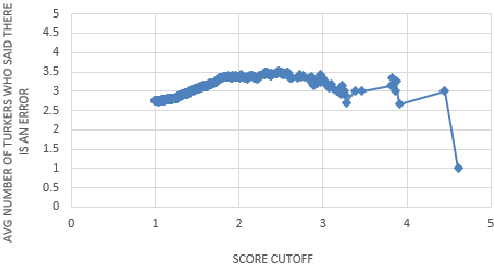
Many important forms of data are stored digitally in XML format. Errors can occur in the textual content of the data in the fields of the XML. Fixing these errors manually is time-consuming and expensive, especially for large amounts of data. There is increasing interest in the research, development, and use of automated techniques for assisting with data cleaning. Electronic dictionaries are an important form of data frequently stored in XML format that frequently have errors introduced through a mixture of manual typographical entry errors and optical character recognition errors. In this paper we describe methods for flagging statistical anomalies as likely errors in electronic dictionaries stored in XML format. We describe six systems based on different sources of information. The systems detect errors using various signals in the data including uncommon characters, text length, character-based language models, word-based language models, tied-field length ratios, and tied-field transliteration models. Four of the systems detect errors based on expectations automatically inferred from content within elements of a single field type. We call these single-field systems. Two of the systems detect errors based on correspondence expectations automatically inferred from content within elements of multiple related field types. We call these tied-field systems. For each system, we provide an intuitive analysis of the type of error that it is successful at detecting. Finally, we describe two larger-scale evaluations using crowdsourcing with Amazon's Mechanical Turk platform and using the annotations of a domain expert. The evaluations consistently show that the systems are useful for improving the efficiency with which errors in XML electronic dictionaries can be detected.
* 8 pages, 4 figures, 5 tables; published in Proceedings of the 2016 IEEE Tenth International Conference on Semantic Computing (ICSC), Laguna Hills, CA, USA, pages 79-86, February 2016
Translation Memory Retrieval Methods
May 21, 2015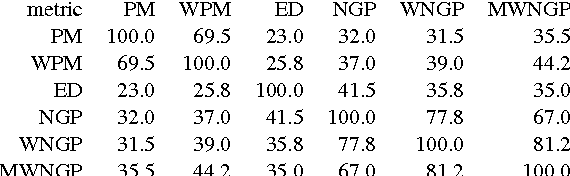
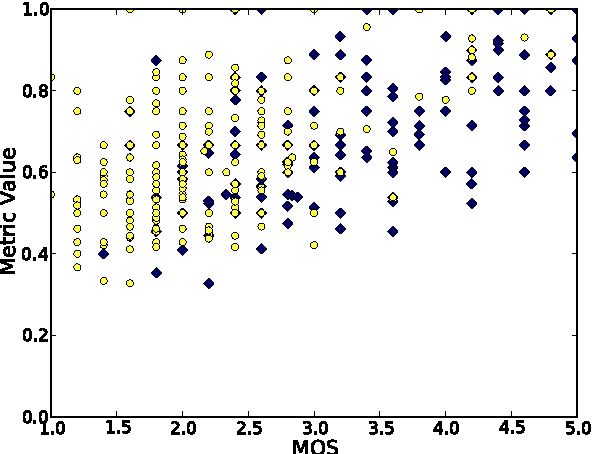
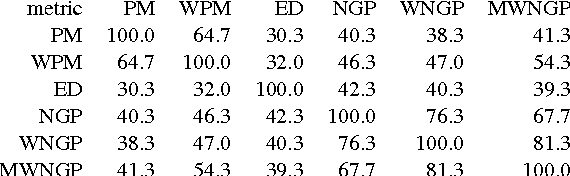
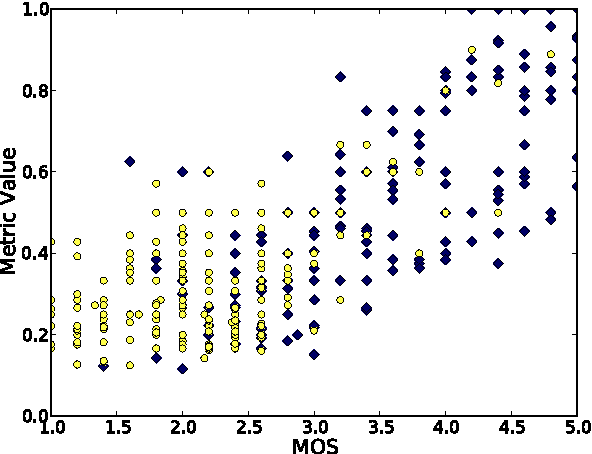
Translation Memory (TM) systems are one of the most widely used translation technologies. An important part of TM systems is the matching algorithm that determines what translations get retrieved from the bank of available translations to assist the human translator. Although detailed accounts of the matching algorithms used in commercial systems can't be found in the literature, it is widely believed that edit distance algorithms are used. This paper investigates and evaluates the use of several matching algorithms, including the edit distance algorithm that is believed to be at the heart of most modern commercial TM systems. This paper presents results showing how well various matching algorithms correlate with human judgments of helpfulness (collected via crowdsourcing with Amazon's Mechanical Turk). A new algorithm based on weighted n-gram precision that can be adjusted for translator length preferences consistently returns translations judged to be most helpful by translators for multiple domains and language pairs.
* 9 pages, 6 tables, 3 figures; appeared in Proceedings of the 14th Conference of the European Chapter of the Association for Computational Linguistics, April 2014