 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslation Memory Retrieval Methods
Paper and Code
May 21, 2015
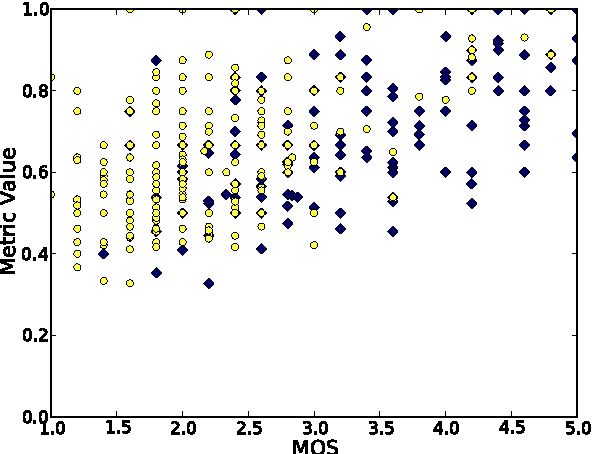
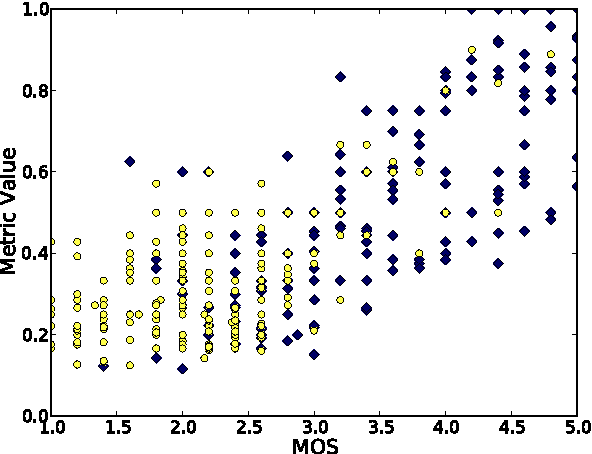
Translation Memory (TM) systems are one of the most widely used translation technologies. An important part of TM systems is the matching algorithm that determines what translations get retrieved from the bank of available translations to assist the human translator. Although detailed accounts of the matching algorithms used in commercial systems can't be found in the literature, it is widely believed that edit distance algorithms are used. This paper investigates and evaluates the use of several matching algorithms, including the edit distance algorithm that is believed to be at the heart of most modern commercial TM systems. This paper presents results showing how well various matching algorithms correlate with human judgments of helpfulness (collected via crowdsourcing with Amazon's Mechanical Turk). A new algorithm based on weighted n-gram precision that can be adjusted for translator length preferences consistently returns translations judged to be most helpful by translators for multiple domains and language pairs.