Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSupport Vector Machine Active Learning Algorithms with Query-by-Committee versus Closest-to-Hyperplane Selection
Paper and Code
May 16, 2018
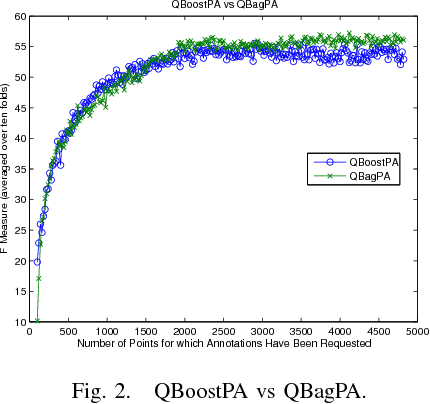
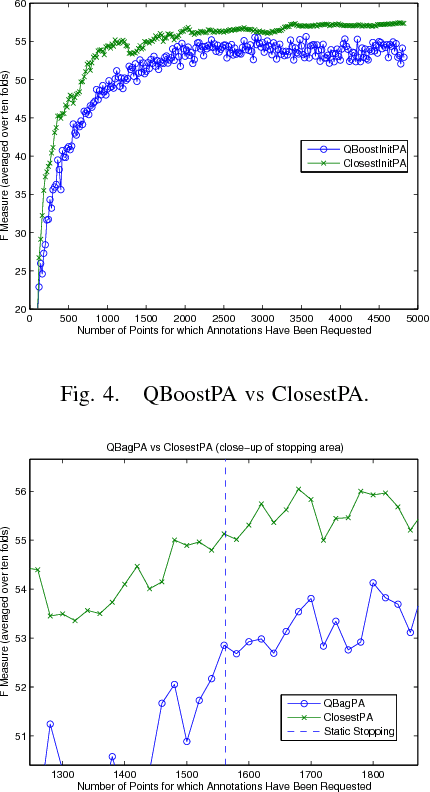
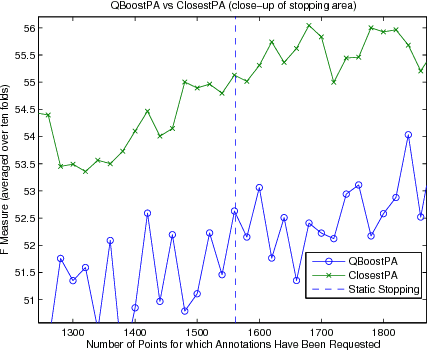
This paper investigates and evaluates support vector machine active learning algorithms for use with imbalanced datasets, which commonly arise in many applications such as information extraction applications. Algorithms based on closest-to-hyperplane selection and query-by-committee selection are combined with methods for addressing imbalance such as positive amplification based on prevalence statistics from initial random samples. Three algorithms (ClosestPA, QBagPA, and QBoostPA) are presented and carefully evaluated on datasets for text classification and relation extraction. The ClosestPA algorithm is shown to consistently outperform the other two in a variety of ways and insights are provided as to why this is the case.
* In Proceedings of the 2018 IEEE 12th International Conference on
Semantic Computing (ICSC), pages 148-155, Laguna Hills, CA, USA, January
2018. IEEE * 8 pages, 7 figures, 3 tables; published in Proceedings of the IEEE
12th International Conference on Semantic Computing (ICSC 2018), Laguna
Hills, CA, USA, pages 148-155, January 2018
View paper on