 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImpact of Stop Sets on Stopping Active Learning for Text Classification
Paper and Code
Jan 08, 2022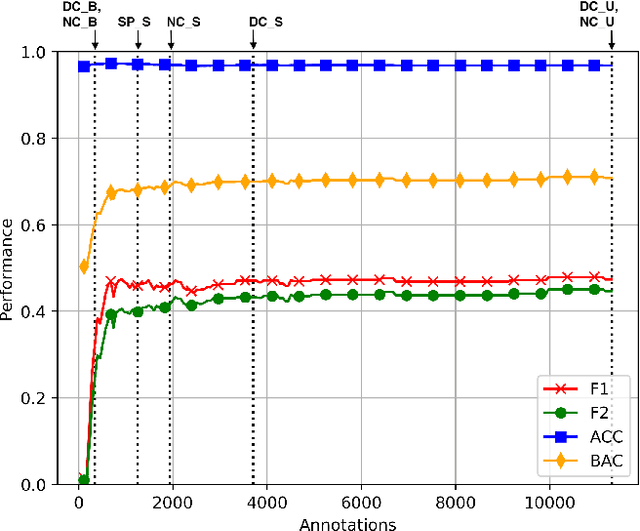

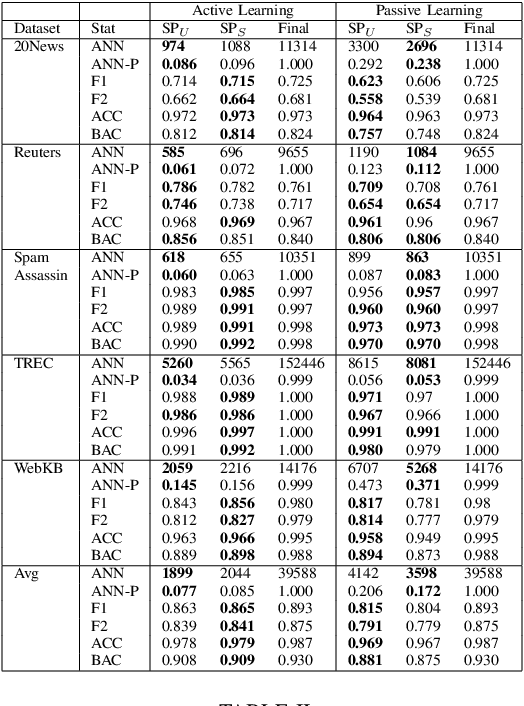
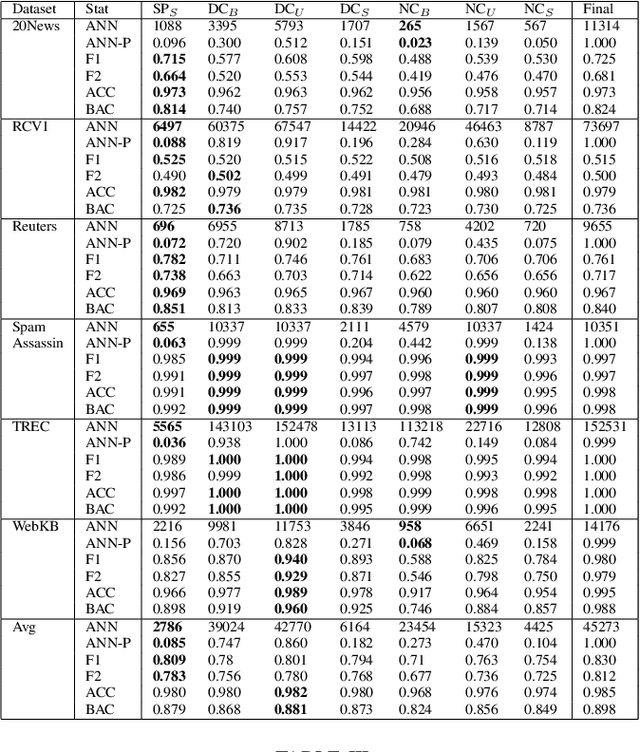
Active learning is an increasingly important branch of machine learning and a powerful technique for natural language processing. The main advantage of active learning is its potential to reduce the amount of labeled data needed to learn high-performing models. A vital aspect of an effective active learning algorithm is the determination of when to stop obtaining additional labeled data. Several leading state-of-the-art stopping methods use a stop set to help make this decision. However, there has been relatively less attention given to the choice of stop set than to the stopping algorithms that are applied on the stop set. Different choices of stop sets can lead to significant differences in stopping method performance. We investigate the impact of different stop set choices on different stopping methods. This paper shows the choice of the stop set can have a significant impact on the performance of stopping methods and the impact is different for stability-based methods from that on confidence-based methods. Furthermore, the unbiased representative stop sets suggested by original authors of methods work better than the systematically biased stop sets used in recently published work, and stopping methods based on stabilizing predictions have stronger performance than confidence-based stopping methods when unbiased representative stop sets are used. We provide the largest quantity of experimental results on the impact of stop sets to date. The findings are important for helping to illuminate the impact of this important aspect of stopping methods that has been under-considered in recently published work and that can have a large practical impact on the performance of stopping methods for important semantic computing applications such as technology assisted review and text classification more broadly.