Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFiltering Tweets for Social Unrest
Apr 01, 2017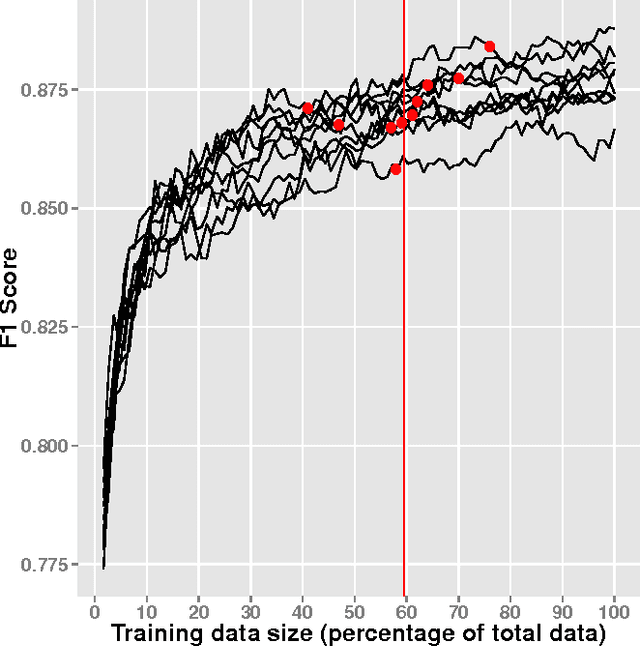
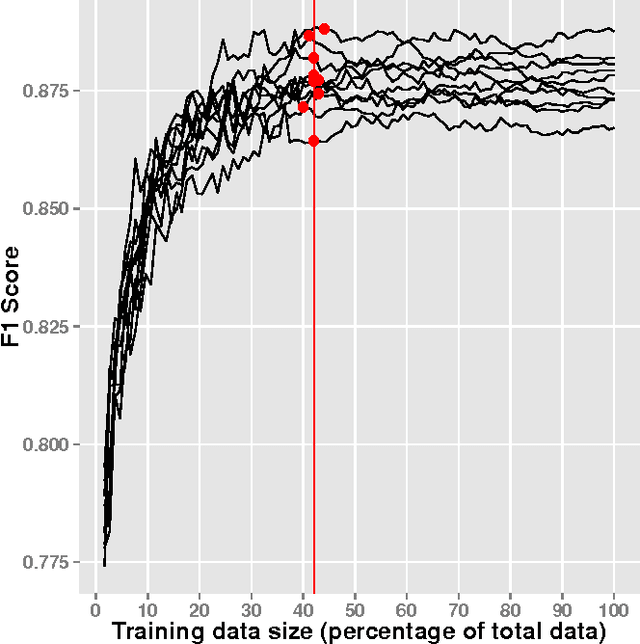
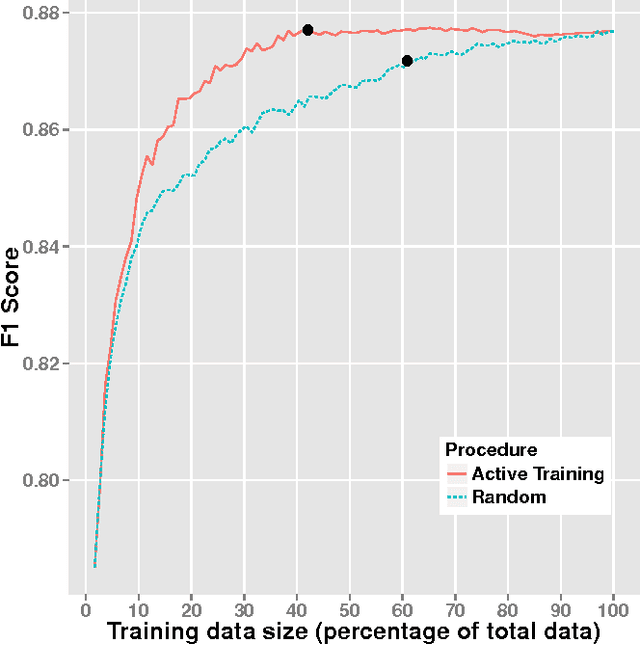
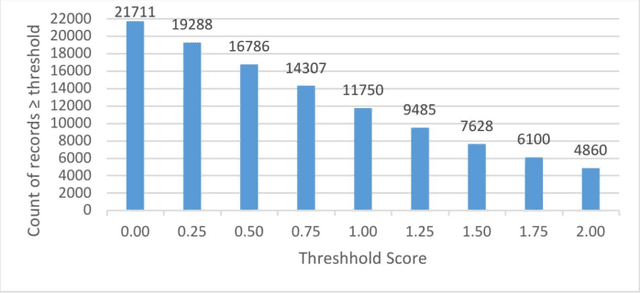
Since the events of the Arab Spring, there has been increased interest in using social media to anticipate social unrest. While efforts have been made toward automated unrest prediction, we focus on filtering the vast volume of tweets to identify tweets relevant to unrest, which can be provided to downstream users for further analysis. We train a supervised classifier that is able to label Arabic language tweets as relevant to unrest with high reliability. We examine the relationship between training data size and performance and investigate ways to optimize the model building process while minimizing cost. We also explore how confidence thresholds can be set to achieve desired levels of performance.
* In Proceedings of the 2017 IEEE 11th International Conference on
Semantic Computing (ICSC), pages 17-23, San Diego, CA, USA, January 2017.
IEEE
* 7 pages, 8 figures, 3 tables; published in Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, pages 17-23, January 2017
* 7 pages, 8 figures, 3 tables; published in Proceedings of the 2017 IEEE 11th International Conference on Semantic Computing (ICSC), San Diego, CA, USA, pages 17-23, January 2017
Via