 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAuthorship Style Transfer with Policy Optimization
Mar 12, 2024Authorship style transfer aims to rewrite a given text into a specified target while preserving the original meaning in the source. Existing approaches rely on the availability of a large number of target style exemplars for model training. However, these overlook cases where a limited number of target style examples are available. The development of parameter-efficient transfer learning techniques and policy optimization (PO) approaches suggest lightweight PO is a feasible approach to low-resource style transfer. In this work, we propose a simple two step tune-and-optimize technique for low-resource textual style transfer. We apply our technique to authorship transfer as well as a larger-data native language style task and in both cases find it outperforms state-of-the-art baseline models.
VecFusion: Vector Font Generation with Diffusion
Dec 16, 2023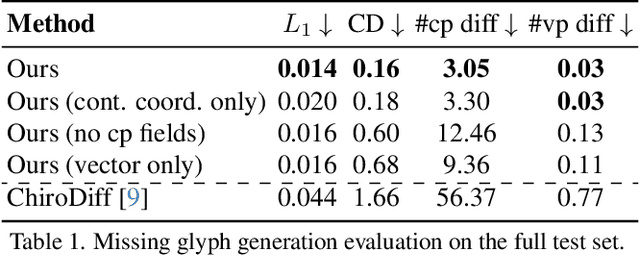

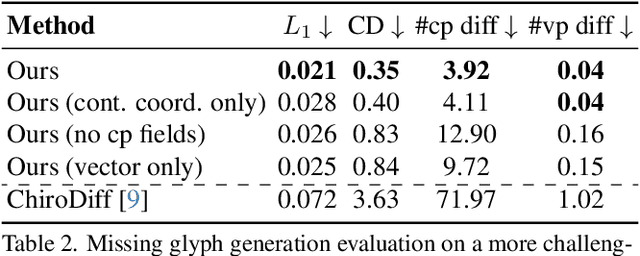

We present VecFusion, a new neural architecture that can generate vector fonts with varying topological structures and precise control point positions. Our approach is a cascaded diffusion model which consists of a raster diffusion model followed by a vector diffusion model. The raster model generates low-resolution, rasterized fonts with auxiliary control point information, capturing the global style and shape of the font, while the vector model synthesizes vector fonts conditioned on the low-resolution raster fonts from the first stage. To synthesize long and complex curves, our vector diffusion model uses a transformer architecture and a novel vector representation that enables the modeling of diverse vector geometry and the precise prediction of control points. Our experiments show that, in contrast to previous generative models for vector graphics, our new cascaded vector diffusion model generates higher quality vector fonts, with complex structures and diverse styles.
Massively Multi-Lingual Event Understanding: Extraction, Visualization, and Search
May 17, 2023
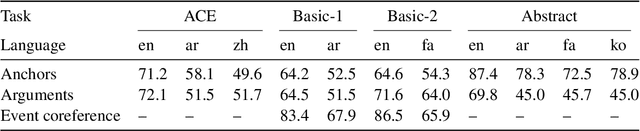

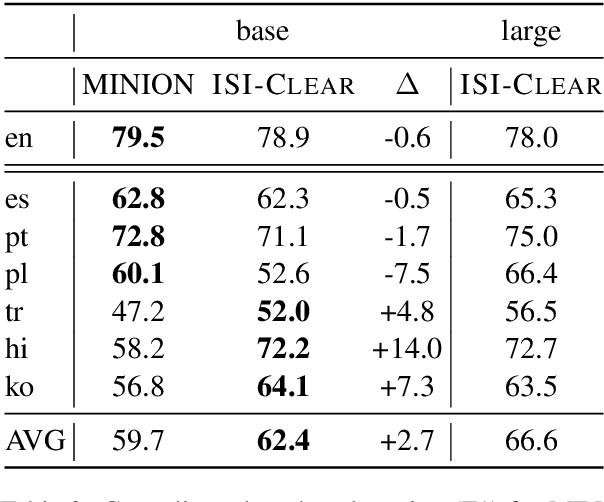
In this paper, we present ISI-Clear, a state-of-the-art, cross-lingual, zero-shot event extraction system and accompanying user interface for event visualization & search. Using only English training data, ISI-Clear makes global events available on-demand, processing user-supplied text in 100 languages ranging from Afrikaans to Yiddish. We provide multiple event-centric views of extracted events, including both a graphical representation and a document-level summary. We also integrate existing cross-lingual search algorithms with event extraction capabilities to provide cross-lingual event-centric search, allowing English-speaking users to search over events automatically extracted from a corpus of non-English documents, using either English natural language queries (e.g. cholera outbreaks in Iran) or structured queries (e.g. find all events of type Disease-Outbreak with agent cholera and location Iran).
Impact of Subword Pooling Strategy on Cross-lingual Event Detection
Feb 23, 2023



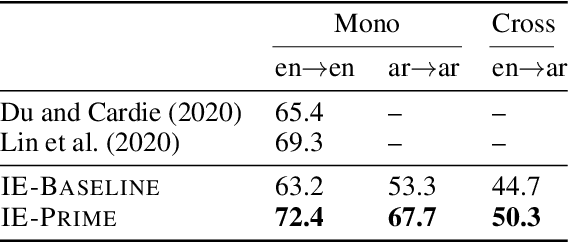
Pre-trained multilingual language models (e.g., mBERT, XLM-RoBERTa) have significantly advanced the state-of-the-art for zero-shot cross-lingual information extraction. These language models ubiquitously rely on word segmentation techniques that break a word into smaller constituent subwords. Therefore, all word labeling tasks (e.g. named entity recognition, event detection, etc.), necessitate a pooling strategy that takes the subword representations as input and outputs a representation for the entire word. Taking the task of cross-lingual event detection as a motivating example, we show that the choice of pooling strategy can have a significant impact on the target language performance. For example, the performance varies by up to 16 absolute $f_{1}$ points depending on the pooling strategy when training in English and testing in Arabic on the ACE task. We carry out our analysis with five different pooling strategies across nine languages in diverse multi-lingual datasets. Across configurations, we find that the canonical strategy of taking just the first subword to represent the entire word is usually sub-optimal. On the other hand, we show that attention pooling is robust to language and dataset variations by being either the best or close to the optimal strategy. For reproducibility, we make our code available at https://github.com/isi-boston/ed-pooling.
Language Model Priming for Cross-Lingual Event Extraction
Sep 25, 2021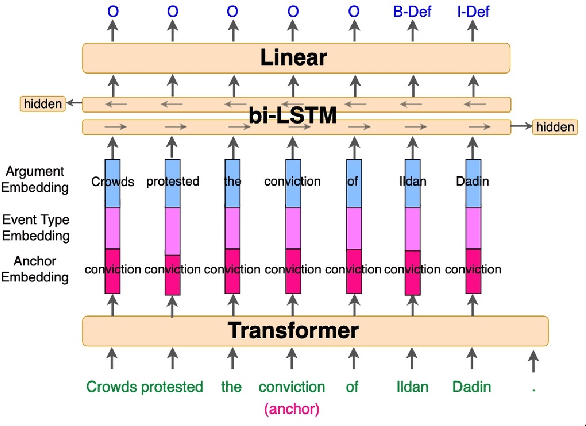
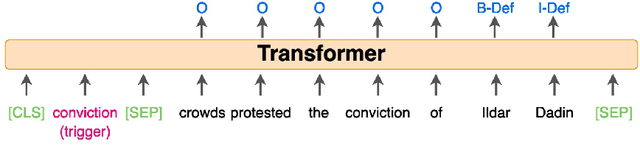

We present a novel, language-agnostic approach to "priming" language models for the task of event extraction, providing particularly effective performance in low-resource and zero-shot cross-lingual settings. With priming, we augment the input to the transformer stack's language model differently depending on the question(s) being asked of the model at runtime. For instance, if the model is being asked to identify arguments for the trigger "protested", we will provide that trigger as part of the input to the language model, allowing it to produce different representations for candidate arguments than when it is asked about arguments for the trigger "arrest" elsewhere in the same sentence. We show that by enabling the language model to better compensate for the deficits of sparse and noisy training data, our approach improves both trigger and argument detection and classification significantly over the state of the art in a zero-shot cross-lingual setting.
End-to-End Learning of Flowchart Grounded Task-Oriented Dialogs
Sep 15, 2021
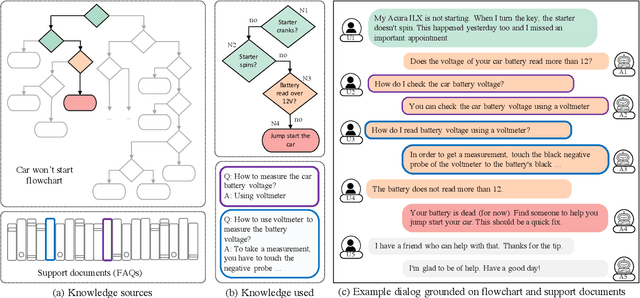
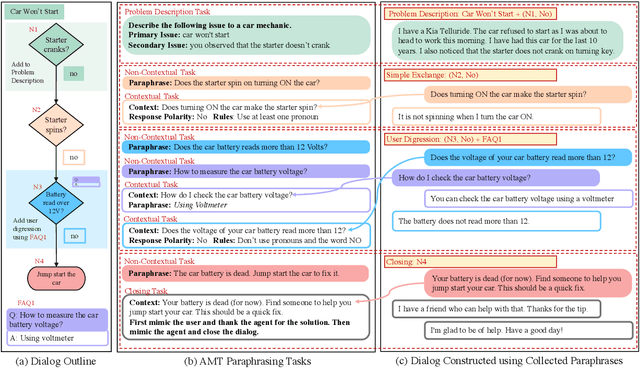
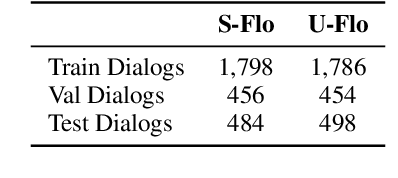
We propose a novel problem within end-to-end learning of task-oriented dialogs (TOD), in which the dialog system mimics a troubleshooting agent who helps a user by diagnosing their problem (e.g., car not starting). Such dialogs are grounded in domain-specific flowcharts, which the agent is supposed to follow during the conversation. Our task exposes novel technical challenges for neural TOD, such as grounding an utterance to the flowchart without explicit annotation, referring to additional manual pages when user asks a clarification question, and ability to follow unseen flowcharts at test time. We release a dataset (FloDial) consisting of 2,738 dialogs grounded on 12 different troubleshooting flowcharts. We also design a neural model, FloNet, which uses a retrieval-augmented generation architecture to train the dialog agent. Our experiments find that FloNet can do zero-shot transfer to unseen flowcharts, and sets a strong baseline for future research.