 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSeparating Style from Substance: Enhancing Cross-Genre Authorship Attribution through Data Selection and Presentation
Aug 09, 2024The task of deciding whether two documents are written by the same author is challenging for both machines and humans. This task is even more challenging when the two documents are written about different topics (e.g. baseball vs. politics) or in different genres (e.g. a blog post vs. an academic article). For machines, the problem is complicated by the relative lack of real-world training examples that cross the topic boundary and the vanishing scarcity of cross-genre data. We propose targeted methods for training data selection and a novel learning curriculum that are designed to discourage a model's reliance on topic information for authorship attribution and correspondingly force it to incorporate information more robustly indicative of style no matter the topic. These refinements yield a 62.7% relative improvement in average cross-genre authorship attribution, as well as 16.6% in the per-genre condition.
Granting GPT-4 License and Opportunity: Enhancing Accuracy and Confidence Estimation for Few-Shot Event Detection
Aug 01, 2024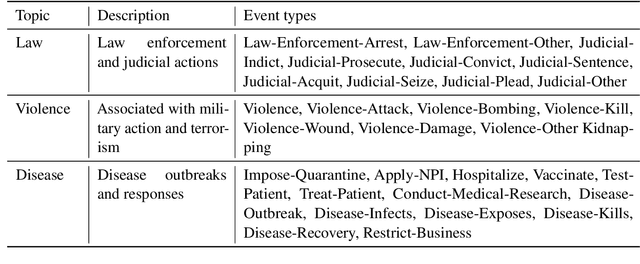

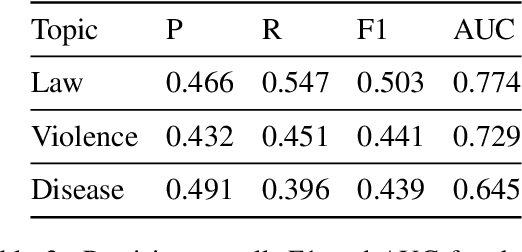
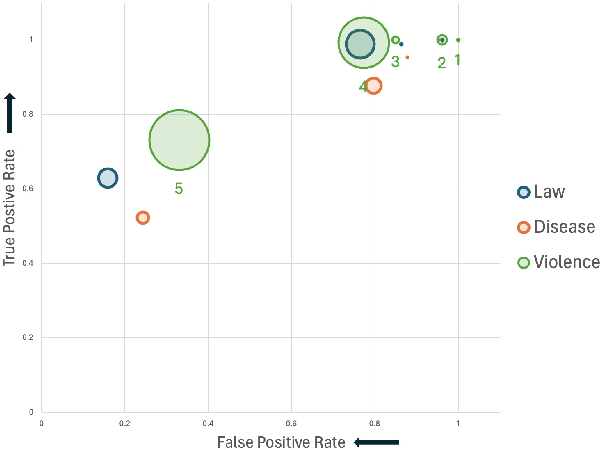
Large Language Models (LLMs) such as GPT-4 have shown enough promise in the few-shot learning context to suggest use in the generation of "silver" data and refinement of new ontologies through iterative application and review. Such workflows become more effective with reliable confidence estimation. Unfortunately, confidence estimation is a documented weakness of models such as GPT-4, and established methods to compensate require significant additional complexity and computation. The present effort explores methods for effective confidence estimation with GPT-4 with few-shot learning for event detection in the BETTER ontology as a vehicle. The key innovation is expanding the prompt and task presented to GPT-4 to provide License to speculate when unsure and Opportunity to quantify and explain its uncertainty (L&O). This approach improves accuracy and provides usable confidence measures (0.759 AUC) with no additional machinery.
Massively Multi-Lingual Event Understanding: Extraction, Visualization, and Search
May 17, 2023
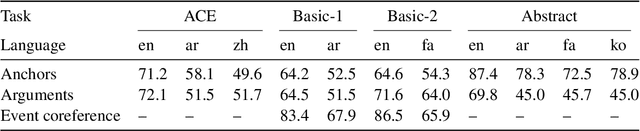

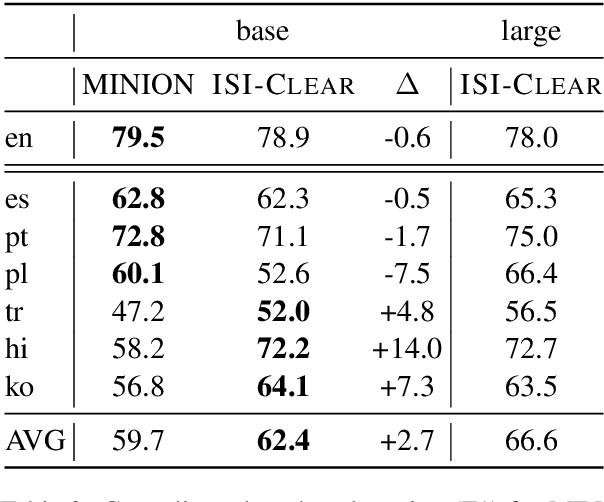
In this paper, we present ISI-Clear, a state-of-the-art, cross-lingual, zero-shot event extraction system and accompanying user interface for event visualization & search. Using only English training data, ISI-Clear makes global events available on-demand, processing user-supplied text in 100 languages ranging from Afrikaans to Yiddish. We provide multiple event-centric views of extracted events, including both a graphical representation and a document-level summary. We also integrate existing cross-lingual search algorithms with event extraction capabilities to provide cross-lingual event-centric search, allowing English-speaking users to search over events automatically extracted from a corpus of non-English documents, using either English natural language queries (e.g. cholera outbreaks in Iran) or structured queries (e.g. find all events of type Disease-Outbreak with agent cholera and location Iran).
Impact of Subword Pooling Strategy on Cross-lingual Event Detection
Feb 23, 2023



Pre-trained multilingual language models (e.g., mBERT, XLM-RoBERTa) have significantly advanced the state-of-the-art for zero-shot cross-lingual information extraction. These language models ubiquitously rely on word segmentation techniques that break a word into smaller constituent subwords. Therefore, all word labeling tasks (e.g. named entity recognition, event detection, etc.), necessitate a pooling strategy that takes the subword representations as input and outputs a representation for the entire word. Taking the task of cross-lingual event detection as a motivating example, we show that the choice of pooling strategy can have a significant impact on the target language performance. For example, the performance varies by up to 16 absolute $f_{1}$ points depending on the pooling strategy when training in English and testing in Arabic on the ACE task. We carry out our analysis with five different pooling strategies across nine languages in diverse multi-lingual datasets. Across configurations, we find that the canonical strategy of taking just the first subword to represent the entire word is usually sub-optimal. On the other hand, we show that attention pooling is robust to language and dataset variations by being either the best or close to the optimal strategy. For reproducibility, we make our code available at https://github.com/isi-boston/ed-pooling.
Language Model Priming for Cross-Lingual Event Extraction
Sep 25, 2021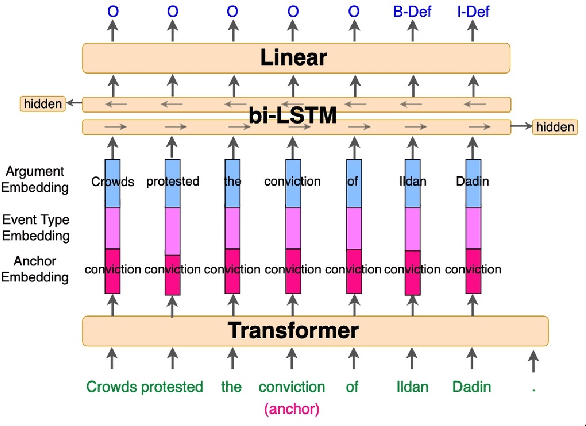
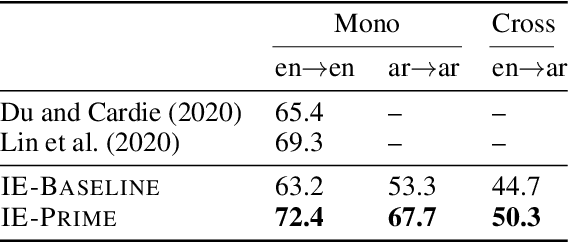
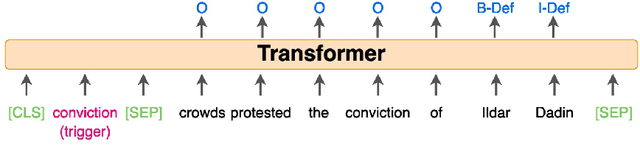

We present a novel, language-agnostic approach to "priming" language models for the task of event extraction, providing particularly effective performance in low-resource and zero-shot cross-lingual settings. With priming, we augment the input to the transformer stack's language model differently depending on the question(s) being asked of the model at runtime. For instance, if the model is being asked to identify arguments for the trigger "protested", we will provide that trigger as part of the input to the language model, allowing it to produce different representations for candidate arguments than when it is asked about arguments for the trigger "arrest" elsewhere in the same sentence. We show that by enabling the language model to better compensate for the deficits of sparse and noisy training data, our approach improves both trigger and argument detection and classification significantly over the state of the art in a zero-shot cross-lingual setting.