 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranting GPT-4 License and Opportunity: Enhancing Accuracy and Confidence Estimation for Few-Shot Event Detection
Aug 01, 2024

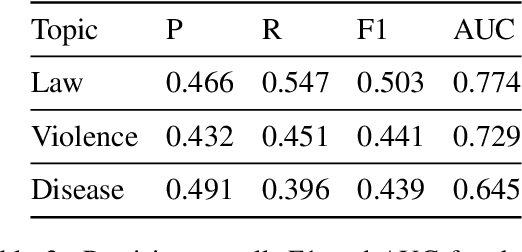
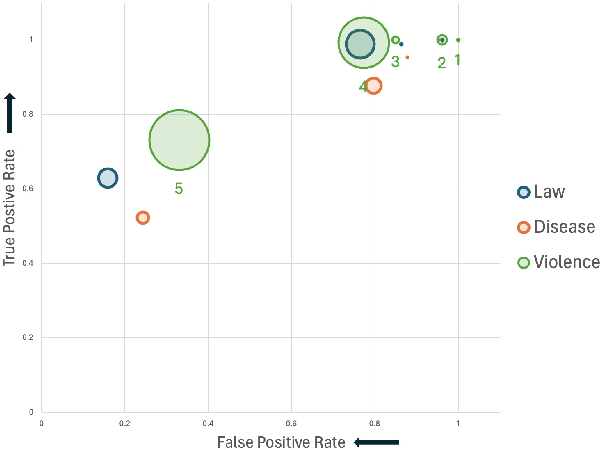
Large Language Models (LLMs) such as GPT-4 have shown enough promise in the few-shot learning context to suggest use in the generation of "silver" data and refinement of new ontologies through iterative application and review. Such workflows become more effective with reliable confidence estimation. Unfortunately, confidence estimation is a documented weakness of models such as GPT-4, and established methods to compensate require significant additional complexity and computation. The present effort explores methods for effective confidence estimation with GPT-4 with few-shot learning for event detection in the BETTER ontology as a vehicle. The key innovation is expanding the prompt and task presented to GPT-4 to provide License to speculate when unsure and Opportunity to quantify and explain its uncertainty (L&O). This approach improves accuracy and provides usable confidence measures (0.759 AUC) with no additional machinery.
SO and O Equivariance in Image Recognition with Bessel-Convolutional Neural Networks
Apr 18, 2023

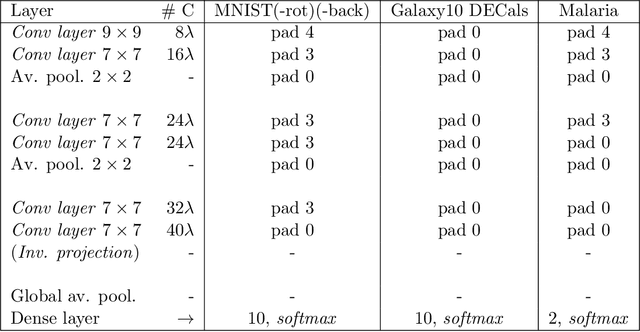
For many years, it has been shown how much exploiting equivariances can be beneficial when solving image analysis tasks. For example, the superiority of convolutional neural networks (CNNs) compared to dense networks mainly comes from an elegant exploitation of the translation equivariance. Patterns can appear at arbitrary positions and convolutions take this into account to achieve translation invariant operations through weight sharing. Nevertheless, images often involve other symmetries that can also be exploited. It is the case of rotations and reflections that have drawn particular attention and led to the development of multiple equivariant CNN architectures. Among all these methods, Bessel-convolutional neural networks (B-CNNs) exploit a particular decomposition based on Bessel functions to modify the key operation between images and filters and make it by design equivariant to all the continuous set of planar rotations. In this work, the mathematical developments of B-CNNs are presented along with several improvements, including the incorporation of reflection and multi-scale equivariances. Extensive study is carried out to assess the performances of B-CNNs compared to other methods. Finally, we emphasize the theoretical advantages of B-CNNs by giving more insights and in-depth mathematical details.
DumbleDR: Predicting User Preferences of Dimensionality Reduction Projection Quality
May 19, 2021
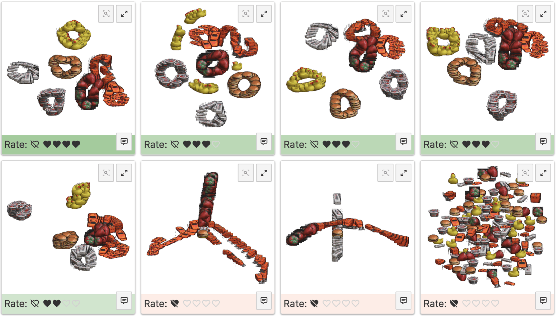
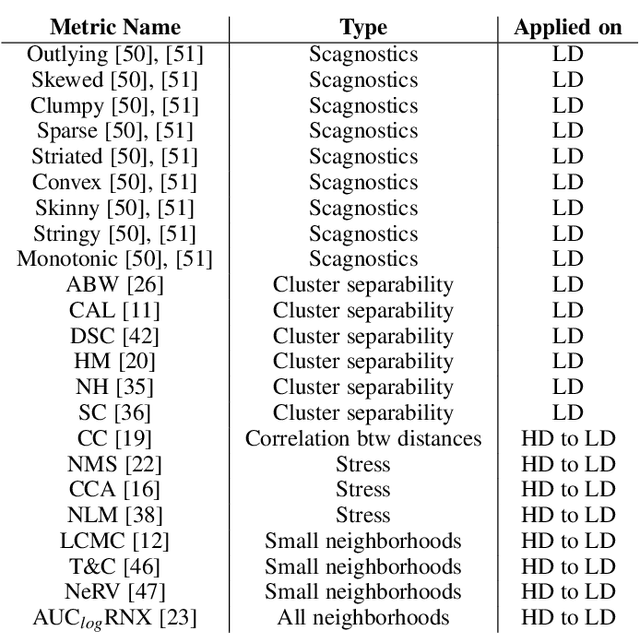
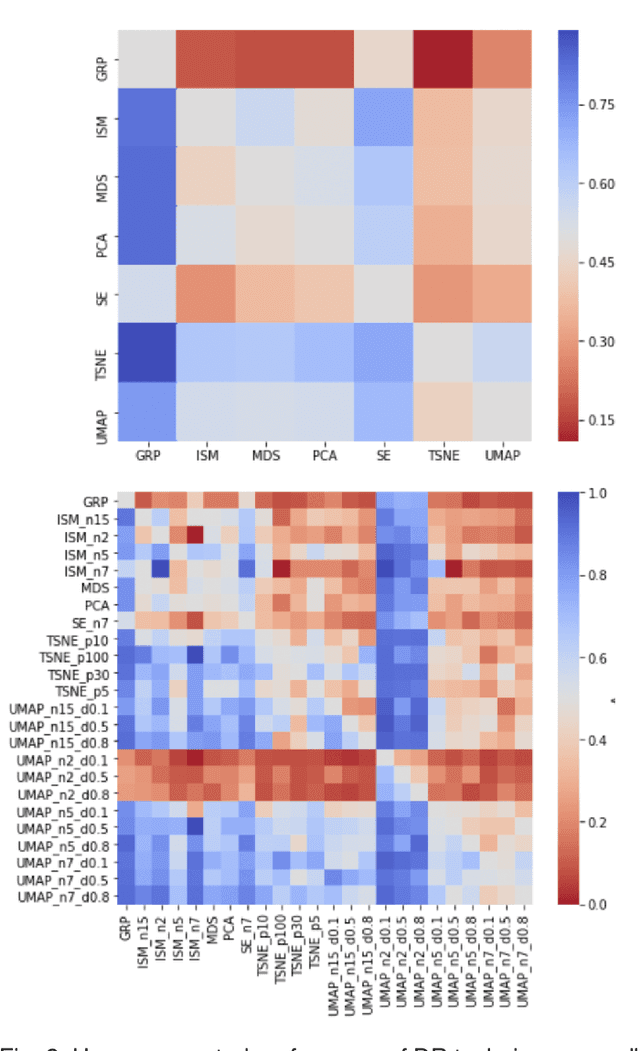
A plethora of dimensionality reduction techniques have emerged over the past decades, leaving researchers and analysts with a wide variety of choices for reducing their data, all the more so given some techniques come with additional parametrization (e.g. t-SNE, UMAP, etc.). Recent studies are showing that people often use dimensionality reduction as a black-box regardless of the specific properties the method itself preserves. Hence, evaluating and comparing 2D projections is usually qualitatively decided, by setting projections side-by-side and letting human judgment decide which projection is the best. In this work, we propose a quantitative way of evaluating projections, that nonetheless places human perception at the center. We run a comparative study, where we ask people to select 'good' and 'misleading' views between scatterplots of low-level projections of image datasets, simulating the way people usually select projections. We use the study data as labels for a set of quality metrics whose purpose is to discover and quantify what exactly people are looking for when deciding between projections. With this proxy for human judgments, we use it to rank projections on new datasets, explain why they are relevant, and quantify the degree of subjectivity in projections selected.
Impact of Legal Requirements on Explainability in Machine Learning
Jul 10, 2020
The requirements on explainability imposed by European laws and their implications for machine learning (ML) models are not always clear. In that perspective, our research analyzes explanation obligations imposed for private and public decision-making, and how they can be implemented by machine learning techniques.
ML + FV = $\heartsuit$? A Survey on the Application of Machine Learning to Formal Verification
Jun 12, 2018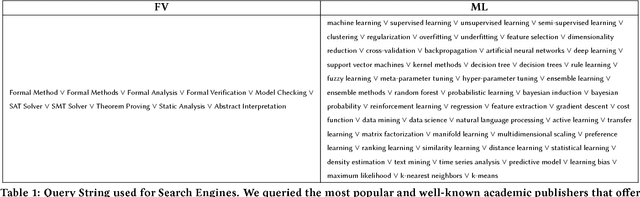
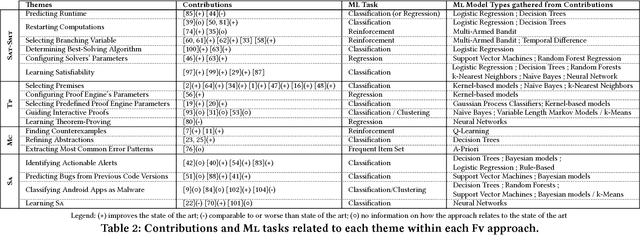

Formal Verification (FV) and Machine Learning (ML) can seem incompatible due to their opposite mathematical foundations and their use in real-life problems: FV mostly relies on discrete mathematics and aims at ensuring correctness; ML often relies on probabilistic models and consists of learning patterns from training data. In this paper, we postulate that they are complementary in practice, and explore how ML helps FV in its classical approaches: static analysis, model-checking, theorem-proving, and SAT solving. We draw a landscape of the current practice and catalog some of the most prominent uses of ML inside FV tools, thus offering a new perspective on FV techniques that can help researchers and practitioners to better locate the possible synergies. We discuss lessons learned from our work, point to possible improvements and offer visions for the future of the domain in the light of the science of software and systems modeling.
Learning Interpretability for Visualizations using Adapted Cox Models through a User Experiment
Nov 18, 2016

In order to be useful, visualizations need to be interpretable. This paper uses a user-based approach to combine and assess quality measures in order to better model user preferences. Results show that cluster separability measures are outperformed by a neighborhood conservation measure, even though the former are usually considered as intuitively representative of user motives. Moreover, combining measures, as opposed to using a single measure, further improves prediction performances.