 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMassively Multi-Lingual Event Understanding: Extraction, Visualization, and Search
May 17, 2023
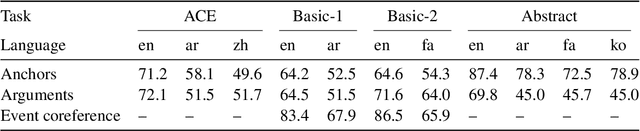

In this paper, we present ISI-Clear, a state-of-the-art, cross-lingual, zero-shot event extraction system and accompanying user interface for event visualization & search. Using only English training data, ISI-Clear makes global events available on-demand, processing user-supplied text in 100 languages ranging from Afrikaans to Yiddish. We provide multiple event-centric views of extracted events, including both a graphical representation and a document-level summary. We also integrate existing cross-lingual search algorithms with event extraction capabilities to provide cross-lingual event-centric search, allowing English-speaking users to search over events automatically extracted from a corpus of non-English documents, using either English natural language queries (e.g. cholera outbreaks in Iran) or structured queries (e.g. find all events of type Disease-Outbreak with agent cholera and location Iran).
Impact of Subword Pooling Strategy on Cross-lingual Event Detection
Feb 23, 2023



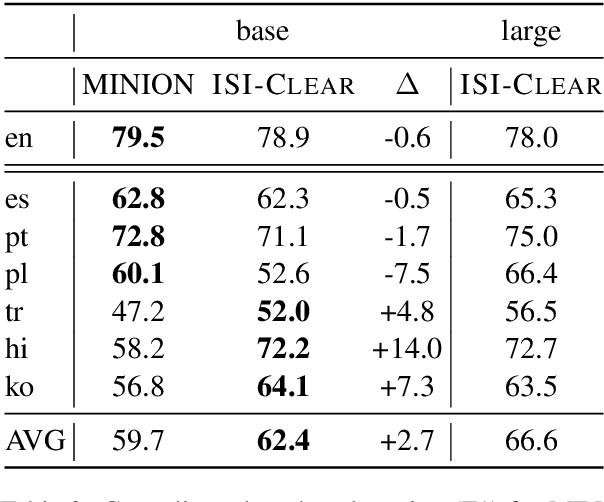
Pre-trained multilingual language models (e.g., mBERT, XLM-RoBERTa) have significantly advanced the state-of-the-art for zero-shot cross-lingual information extraction. These language models ubiquitously rely on word segmentation techniques that break a word into smaller constituent subwords. Therefore, all word labeling tasks (e.g. named entity recognition, event detection, etc.), necessitate a pooling strategy that takes the subword representations as input and outputs a representation for the entire word. Taking the task of cross-lingual event detection as a motivating example, we show that the choice of pooling strategy can have a significant impact on the target language performance. For example, the performance varies by up to 16 absolute $f_{1}$ points depending on the pooling strategy when training in English and testing in Arabic on the ACE task. We carry out our analysis with five different pooling strategies across nine languages in diverse multi-lingual datasets. Across configurations, we find that the canonical strategy of taking just the first subword to represent the entire word is usually sub-optimal. On the other hand, we show that attention pooling is robust to language and dataset variations by being either the best or close to the optimal strategy. For reproducibility, we make our code available at https://github.com/isi-boston/ed-pooling.