 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTranslating the Untranslatable: An Operationalizable Ontology for Untranslatability
Jun 15, 2026Untranslatability, cases where meaning cannot be directly preserved across languages, is well-studied in linguistics but underexplored in NLP. As machine translation (MT) systems improve on standard benchmarks, their limitations increasingly concentrate in such cases, where translation cannot be reduced to one-to-one equivalence. We introduce a structured ontology of untranslatability along with a taxonomy of compensation strategies, which are specific techniques to convey meaning under these untranslatable circumstances. We operationalize this framework into a multilingual dataset of untranslatable sentences paired with strategy-based translations, enabling controlled analysis of translation behavior. Initial human preference studies suggest that translation quality depends on the strategy used, with consistent preferences for outputs that include explanatory context, known as the Annotation compensation strategy. Our framework and dataset provide a foundation for studying and modeling strategy-informed machine translation.
Machine Translation Robustness to Natural Asemantic Variation
May 25, 2022
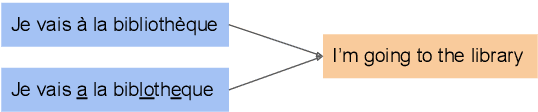

We introduce and formalize an under-studied linguistic phenomenon we call Natural Asemantic Variation (NAV) and investigate it in the context of Machine Translation (MT) robustness. Standard MT models are shown to be less robust to rarer, nuanced language forms, and current robustness techniques do not account for this kind of perturbation despite their prevalence in "real world" data. Experiment results provide more insight into the nature of NAV and we demonstrate strategies to improve performance on NAV. We also show that NAV robustness can be transferred across languages and fine that synthetic perturbations can achieve some but not all of the benefits of human-generated NAV data.
The Multilingual TEDx Corpus for Speech Recognition and Translation
Feb 02, 2021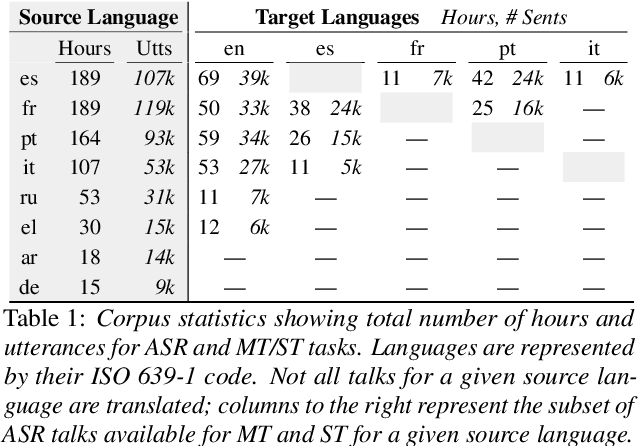
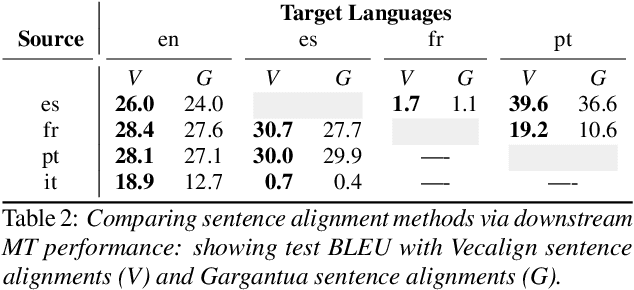
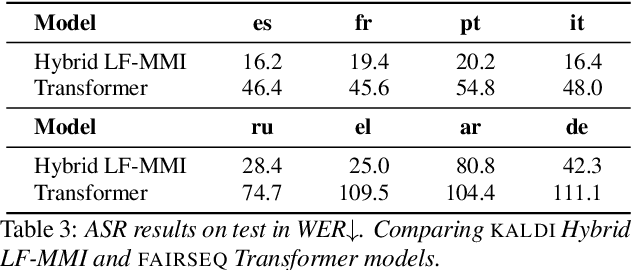
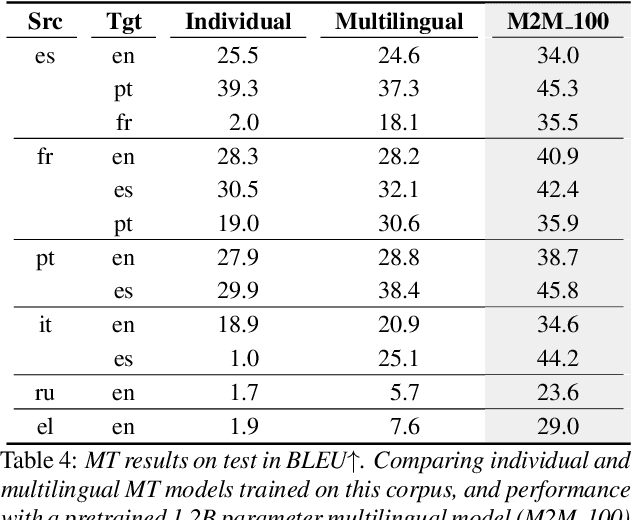
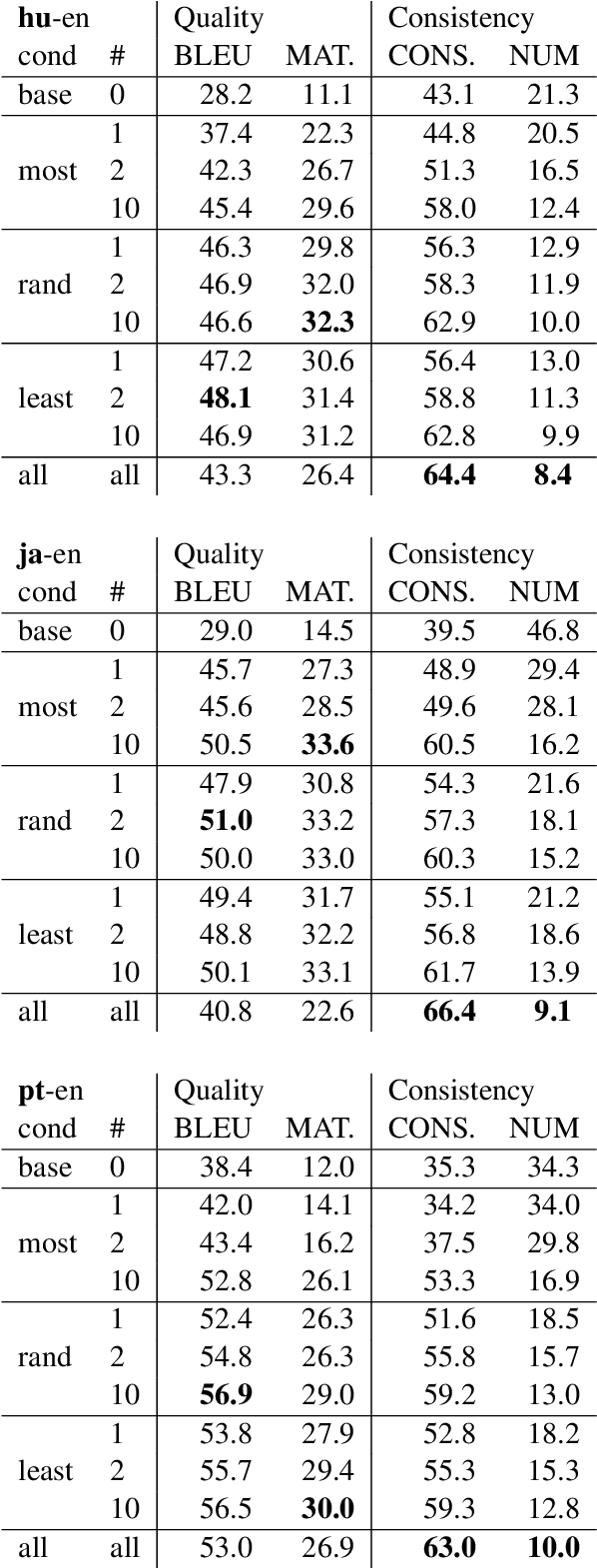
We present the Multilingual TEDx corpus, built to support speech recognition (ASR) and speech translation (ST) research across many non-English source languages. The corpus is a collection of audio recordings from TEDx talks in 8 source languages. We segment transcripts into sentences and align them to the source-language audio and target-language translations. The corpus is released along with open-sourced code enabling extension to new talks and languages as they become available. Our corpus creation methodology can be applied to more languages than previous work, and creates multi-way parallel evaluation sets. We provide baselines in multiple ASR and ST settings, including multilingual models to improve translation performance for low-resource language pairs.