Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Translation Robustness to Natural Asemantic Variation
Paper and Code


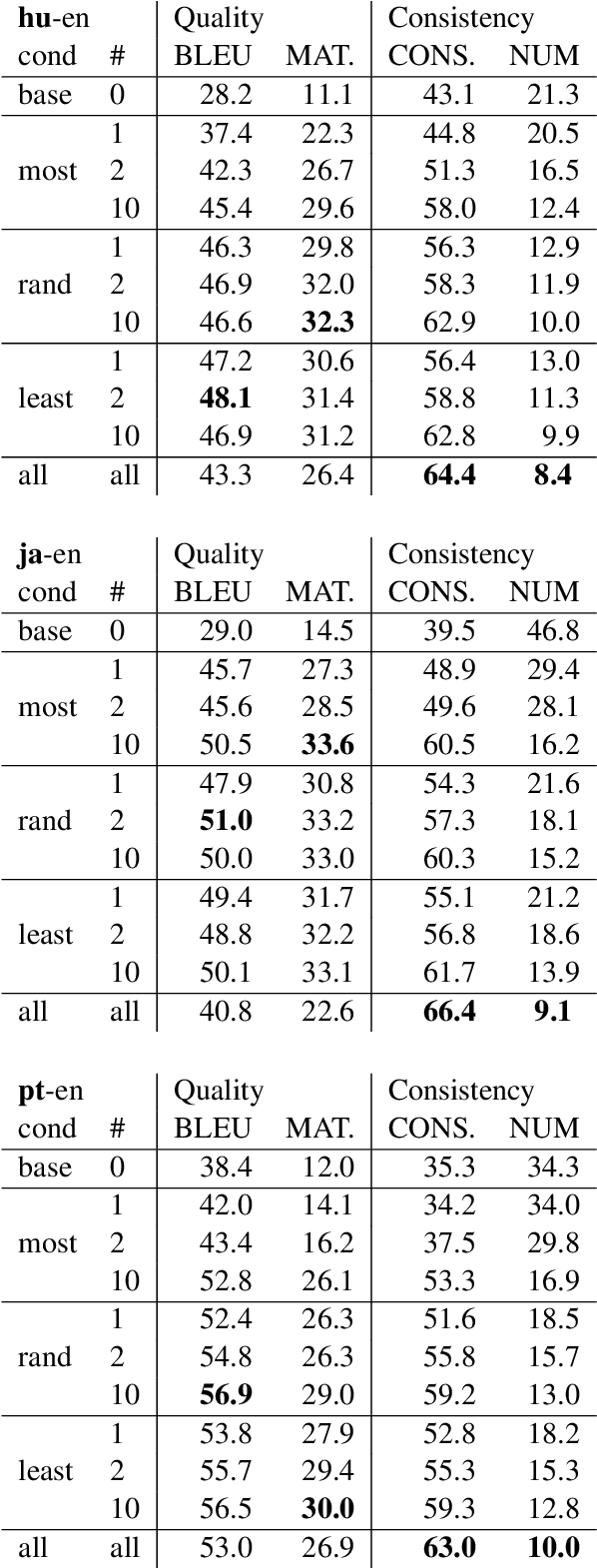
We introduce and formalize an under-studied linguistic phenomenon we call Natural Asemantic Variation (NAV) and investigate it in the context of Machine Translation (MT) robustness. Standard MT models are shown to be less robust to rarer, nuanced language forms, and current robustness techniques do not account for this kind of perturbation despite their prevalence in "real world" data. Experiment results provide more insight into the nature of NAV and we demonstrate strategies to improve performance on NAV. We also show that NAV robustness can be transferred across languages and fine that synthetic perturbations can achieve some but not all of the benefits of human-generated NAV data.
View paper on