 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoison Once, Exploit Forever: Environment-Injected Memory Poisoning Attacks on Web Agents
Apr 03, 2026Memory makes LLM-based web agents personalized, powerful, yet exploitable. By storing past interactions to personalize future tasks, agents inadvertently create a persistent attack surface that spans websites and sessions. While existing security research on memory assumes attackers can directly inject into memory storage or exploit shared memory across users, we present a more realistic threat model: contamination through environmental observation alone. We introduce Environment-injected Trajectory-based Agent Memory Poisoning (eTAMP), the first attack to achieve cross-session, cross-site compromise without requiring direct memory access. A single contaminated observation (e.g., viewing a manipulated product page) silently poisons an agent's memory and activates during future tasks on different websites, bypassing permission-based defenses. Our experiments on (Visual)WebArena reveal two key findings. First, eTAMP achieves substantial attack success rates: up to 32.5% on GPT-5-mini, 23.4% on GPT-5.2, and 19.5% on GPT-OSS-120B. Second, we discover Frustration Exploitation: agents under environmental stress become dramatically more susceptible, with ASR increasing up to 8 times when agents struggle with dropped clicks or garbled text. Notably, more capable models are not more secure. GPT-5.2 shows substantial vulnerability despite superior task performance. With the rise of AI browsers like OpenClaw, ChatGPT Atlas, and Perplexity Comet, our findings underscore the urgent need for defenses against environment-injected memory poisoning.
Metric-Fair Prompting: Treating Similar Samples Similarly
Dec 08, 2025



We introduce \emph{Metric-Fair Prompting}, a fairness-aware prompting framework that guides large language models (LLMs) to make decisions under metric-fairness constraints. In the application of multiple-choice medical question answering, each {(question, option)} pair is treated as a binary instance with label $+1$ (correct) or $-1$ (incorrect). To promote {individual fairness}~--~treating similar instances similarly~--~we compute question similarity using NLP embeddings and solve items in \emph{joint pairs of similar questions} rather than in isolation. The prompt enforces a global decision protocol: extract decisive clinical features, map each \((\text{question}, \text{option})\) to a score $f(x)$ that acts as confidence, and impose a Lipschitz-style constraint so that similar inputs receive similar scores and, hence, consistent outputs. Evaluated on the {MedQA (US)} benchmark, Metric-Fair Prompting is shown to improve performance over standard single-item prompting, demonstrating that fairness-guided, confidence-oriented reasoning can enhance LLM accuracy on high-stakes clinical multiple-choice questions.
MIMIC-\RNum{4}-Ext-22MCTS: A 22 Millions-Event Temporal Clinical Time-Series Dataset with Relative Timestamp for Risk Prediction
May 01, 2025



Clinical risk prediction based on machine learning algorithms plays a vital role in modern healthcare. A crucial component in developing a reliable prediction model is collecting high-quality time series clinical events. In this work, we release such a dataset that consists of 22,588,586 Clinical Time Series events, which we term MIMIC-\RNum{4}-Ext-22MCTS. Our source data are discharge summaries selected from the well-known yet unstructured MIMIC-IV-Note \cite{Johnson2023-pg}. We then extract clinical events as short text span from the discharge summaries, along with the timestamps of these events as temporal information. The general-purpose MIMIC-IV-Note pose specific challenges for our work: it turns out that the discharge summaries are too lengthy for typical natural language models to process, and the clinical events of interest often are not accompanied with explicit timestamps. Therefore, we propose a new framework that works as follows: 1) we break each discharge summary into manageably small text chunks; 2) we apply contextual BM25 and contextual semantic search to retrieve chunks that have a high potential of containing clinical events; and 3) we carefully design prompts to teach the recently released Llama-3.1-8B \cite{touvron2023llama} model to identify or infer temporal information of the chunks. We show that the obtained dataset is so informative and transparent that standard models fine-tuned on our dataset are achieving significant improvements in healthcare applications. In particular, the BERT model fine-tuned based on our dataset achieves 10\% improvement in accuracy on medical question answering task, and 3\% improvement in clinical trial matching task compared with the classic BERT. The GPT-2 model, fine-tuned on our dataset, produces more clinically reliable results for clinical questions.
Zero-resource Speech Translation and Recognition with LLMs
Dec 24, 2024


Despite recent advancements in speech processing, zero-resource speech translation (ST) and automatic speech recognition (ASR) remain challenging problems. In this work, we propose to leverage a multilingual Large Language Model (LLM) to perform ST and ASR in languages for which the model has never seen paired audio-text data. We achieve this by using a pre-trained multilingual speech encoder, a multilingual LLM, and a lightweight adaptation module that maps the audio representations to the token embedding space of the LLM. We perform several experiments both in ST and ASR to understand how to best train the model and what data has the most impact on performance in previously unseen languages. In ST, our best model is capable to achieve BLEU scores over 23 in CoVoST2 for two previously unseen languages, while in ASR, we achieve WERs of up to 28.2\%. We finally show that the performance of our system is bounded by the ability of the LLM to output text in the desired language.
Improving Lip-synchrony in Direct Audio-Visual Speech-to-Speech Translation
Dec 21, 2024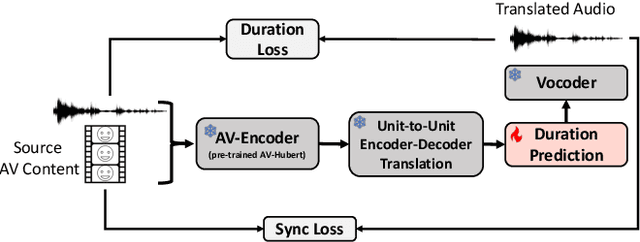



Audio-Visual Speech-to-Speech Translation typically prioritizes improving translation quality and naturalness. However, an equally critical aspect in audio-visual content is lip-synchrony-ensuring that the movements of the lips match the spoken content-essential for maintaining realism in dubbed videos. Despite its importance, the inclusion of lip-synchrony constraints in AVS2S models has been largely overlooked. This study addresses this gap by integrating a lip-synchrony loss into the training process of AVS2S models. Our proposed method significantly enhances lip-synchrony in direct audio-visual speech-to-speech translation, achieving an average LSE-D score of 10.67, representing a 9.2% reduction in LSE-D over a strong baseline across four language pairs. Additionally, it maintains the naturalness and high quality of the translated speech when overlaid onto the original video, without any degradation in translation quality.
Findings of the IWSLT 2024 Evaluation Campaign
Nov 07, 2024This paper reports on the shared tasks organized by the 21st IWSLT Conference. The shared tasks address 7 scientific challenges in spoken language translation: simultaneous and offline translation, automatic subtitling and dubbing, speech-to-speech translation, dialect and low-resource speech translation, and Indic languages. The shared tasks attracted 18 teams whose submissions are documented in 26 system papers. The growing interest towards spoken language translation is also witnessed by the constantly increasing number of shared task organizers and contributors to the overview paper, almost evenly distributed across industry and academia.
M3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Jun 12, 2024
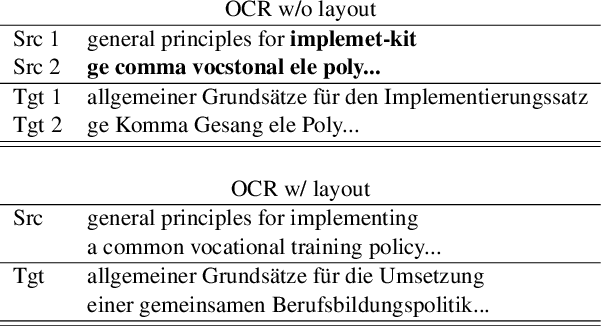

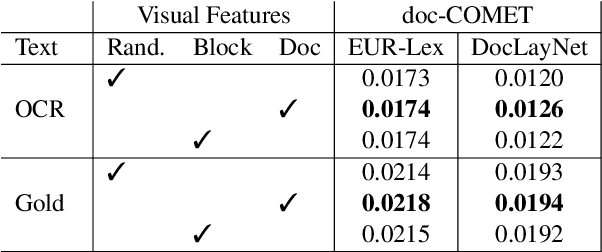
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.
SpeechVerse: A Large-scale Generalizable Audio Language Model
May 14, 2024



Large language models (LLMs) have shown incredible proficiency in performing tasks that require semantic understanding of natural language instructions. Recently, many works have further expanded this capability to perceive multimodal audio and text inputs, but their capabilities are often limited to specific fine-tuned tasks such as automatic speech recognition and translation. We therefore develop SpeechVerse, a robust multi-task training and curriculum learning framework that combines pre-trained speech and text foundation models via a small set of learnable parameters, while keeping the pre-trained models frozen during training. The models are instruction finetuned using continuous latent representations extracted from the speech foundation model to achieve optimal zero-shot performance on a diverse range of speech processing tasks using natural language instructions. We perform extensive benchmarking that includes comparing our model performance against traditional baselines across several datasets and tasks. Furthermore, we evaluate the model's capability for generalized instruction following by testing on out-of-domain datasets, novel prompts, and unseen tasks. Our empirical experiments reveal that our multi-task SpeechVerse model is even superior to conventional task-specific baselines on 9 out of the 11 tasks.
End-to-End Single-Channel Speaker-Turn Aware Conversational Speech Translation
Nov 01, 2023



Conventional speech-to-text translation (ST) systems are trained on single-speaker utterances, and they may not generalize to real-life scenarios where the audio contains conversations by multiple speakers. In this paper, we tackle single-channel multi-speaker conversational ST with an end-to-end and multi-task training model, named Speaker-Turn Aware Conversational Speech Translation, that combines automatic speech recognition, speech translation and speaker turn detection using special tokens in a serialized labeling format. We run experiments on the Fisher-CALLHOME corpus, which we adapted by merging the two single-speaker channels into one multi-speaker channel, thus representing the more realistic and challenging scenario with multi-speaker turns and cross-talk. Experimental results across single- and multi-speaker conditions and against conventional ST systems, show that our model outperforms the reference systems on the multi-speaker condition, while attaining comparable performance on the single-speaker condition. We release scripts for data processing and model training.
RAMP: Retrieval and Attribute-Marking Enhanced Prompting for Attribute-Controlled Translation
May 26, 2023
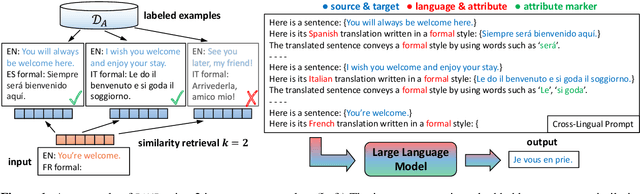
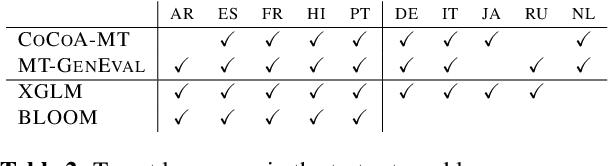
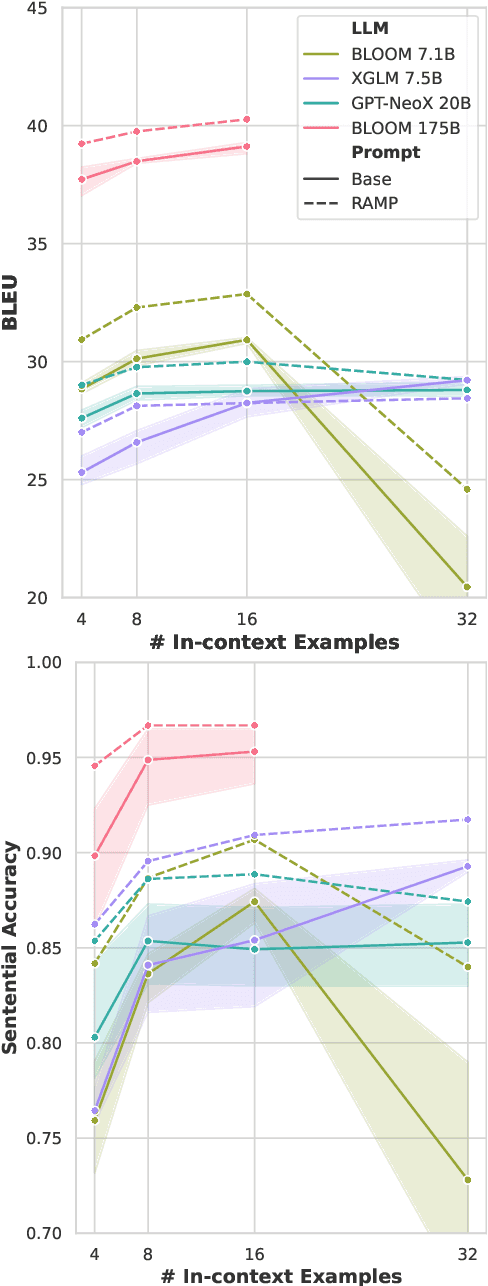
Attribute-controlled translation (ACT) is a subtask of machine translation that involves controlling stylistic or linguistic attributes (like formality and gender) of translation outputs. While ACT has garnered attention in recent years due to its usefulness in real-world applications, progress in the task is currently limited by dataset availability, since most prior approaches rely on supervised methods. To address this limitation, we propose Retrieval and Attribute-Marking enhanced Prompting (RAMP), which leverages large multilingual language models to perform ACT in few-shot and zero-shot settings. RAMP improves generation accuracy over the standard prompting approach by (1) incorporating a semantic similarity retrieval component for selecting similar in-context examples, and (2) marking in-context examples with attribute annotations. Our comprehensive experiments show that RAMP is a viable approach in both zero-shot and few-shot settings.