 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAMP: Retrieval and Attribute-Marking Enhanced Prompting for Attribute-Controlled Translation
May 26, 2023
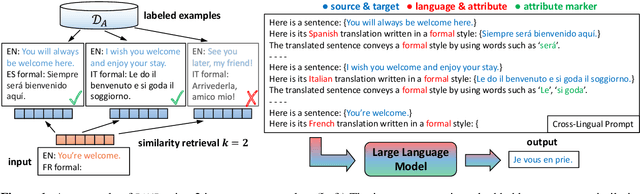
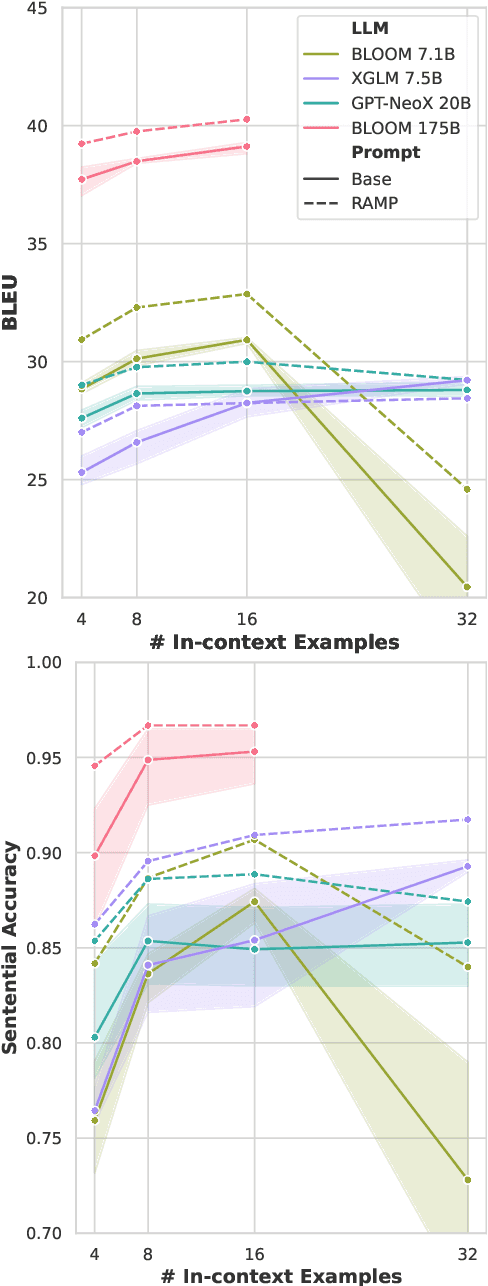
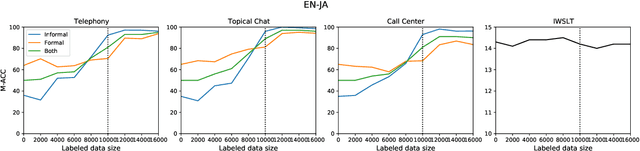
Attribute-controlled translation (ACT) is a subtask of machine translation that involves controlling stylistic or linguistic attributes (like formality and gender) of translation outputs. While ACT has garnered attention in recent years due to its usefulness in real-world applications, progress in the task is currently limited by dataset availability, since most prior approaches rely on supervised methods. To address this limitation, we propose Retrieval and Attribute-Marking enhanced Prompting (RAMP), which leverages large multilingual language models to perform ACT in few-shot and zero-shot settings. RAMP improves generation accuracy over the standard prompting approach by (1) incorporating a semantic similarity retrieval component for selecting similar in-context examples, and (2) marking in-context examples with attribute annotations. Our comprehensive experiments show that RAMP is a viable approach in both zero-shot and few-shot settings.
Pseudo-Label Training and Model Inertia in Neural Machine Translation
May 19, 2023Like many other machine learning applications, neural machine translation (NMT) benefits from over-parameterized deep neural models. However, these models have been observed to be brittle: NMT model predictions are sensitive to small input changes and can show significant variation across re-training or incremental model updates. This work studies a frequently used method in NMT, pseudo-label training (PLT), which is common to the related techniques of forward-translation (or self-training) and sequence-level knowledge distillation. While the effect of PLT on quality is well-documented, we highlight a lesser-known effect: PLT can enhance a model's stability to model updates and input perturbations, a set of properties we call model inertia. We study inertia effects under different training settings and we identify distribution simplification as a mechanism behind the observed results.
MT-GenEval: A Counterfactual and Contextual Dataset for Evaluating Gender Accuracy in Machine Translation
Nov 02, 2022



As generic machine translation (MT) quality has improved, the need for targeted benchmarks that explore fine-grained aspects of quality has increased. In particular, gender accuracy in translation can have implications in terms of output fluency, translation accuracy, and ethics. In this paper, we introduce MT-GenEval, a benchmark for evaluating gender accuracy in translation from English into eight widely-spoken languages. MT-GenEval complements existing benchmarks by providing realistic, gender-balanced, counterfactual data in eight language pairs where the gender of individuals is unambiguous in the input segment, including multi-sentence segments requiring inter-sentential gender agreement. Our data and code is publicly available under a CC BY SA 3.0 license.
CoCoA-MT: A Dataset and Benchmark for Contrastive Controlled MT with Application to Formality
May 09, 2022
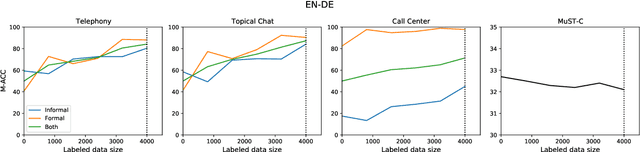

The machine translation (MT) task is typically formulated as that of returning a single translation for an input segment. However, in many cases, multiple different translations are valid and the appropriate translation may depend on the intended target audience, characteristics of the speaker, or even the relationship between speakers. Specific problems arise when dealing with honorifics, particularly translating from English into languages with formality markers. For example, the sentence "Are you sure?" can be translated in German as "Sind Sie sich sicher?" (formal register) or "Bist du dir sicher?" (informal). Using wrong or inconsistent tone may be perceived as inappropriate or jarring for users of certain cultures and demographics. This work addresses the problem of learning to control target language attributes, in this case formality, from a small amount of labeled contrastive data. We introduce an annotated dataset (CoCoA-MT) and an associated evaluation metric for training and evaluating formality-controlled MT models for six diverse target languages. We show that we can train formality-controlled models by fine-tuning on labeled contrastive data, achieving high accuracy (82% in-domain and 73% out-of-domain) while maintaining overall quality.
Faithful Target Attribute Prediction in Neural Machine Translation
Sep 24, 2021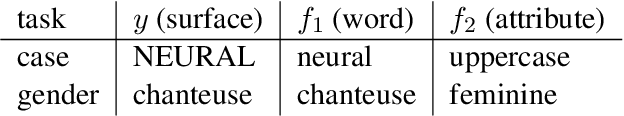
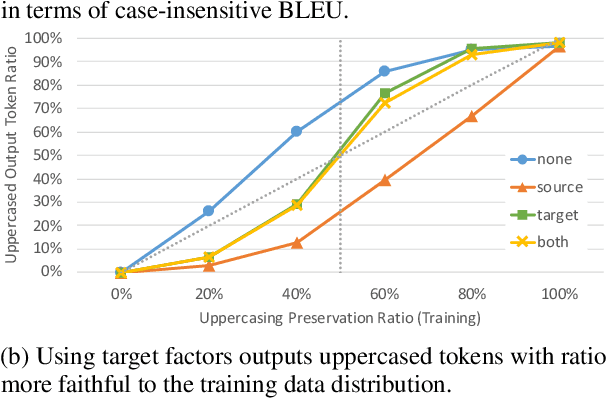
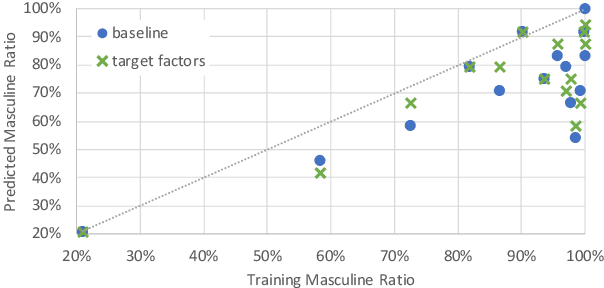
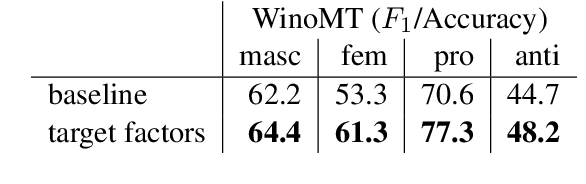
The training data used in NMT is rarely controlled with respect to specific attributes, such as word casing or gender, which can cause errors in translations. We argue that predicting the target word and attributes simultaneously is an effective way to ensure that translations are more faithful to the training data distribution with respect to these attributes. Experimental results on two tasks, uppercased input translation and gender prediction, show that this strategy helps mirror the training data distribution in testing. It also facilitates data augmentation on the task of uppercased input translation.
Improving Gender Translation Accuracy with Filtered Self-Training
Apr 15, 2021
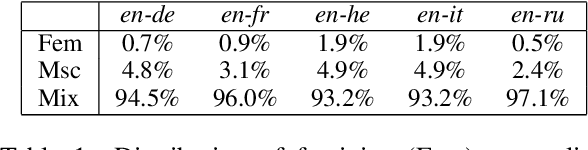


Targeted evaluations have found that machine translation systems often output incorrect gender, even when the gender is clear from context. Furthermore, these incorrectly gendered translations have the potential to reflect or amplify social biases. We propose a gender-filtered self-training technique to improve gender translation accuracy on unambiguously gendered inputs. This approach uses a source monolingual corpus and an initial model to generate gender-specific pseudo-parallel corpora which are then added to the training data. We filter the gender-specific corpora on the source and target sides to ensure that sentence pairs contain and correctly translate the specified gender. We evaluate our approach on translation from English into five languages, finding that our models improve gender translation accuracy without any cost to generic translation quality. In addition, we show the viability of our approach on several settings, including re-training from scratch, fine-tuning, controlling the balance of the training data, forward translation, and back-translation.
Evaluating Robustness to Input Perturbations for Neural Machine Translation
May 01, 2020
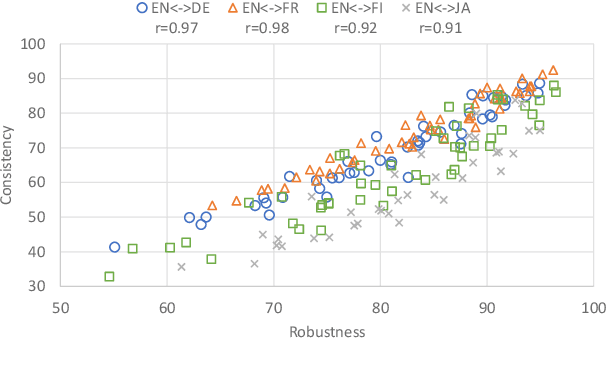


Neural Machine Translation (NMT) models are sensitive to small perturbations in the input. Robustness to such perturbations is typically measured using translation quality metrics such as BLEU on the noisy input. This paper proposes additional metrics which measure the relative degradation and changes in translation when small perturbations are added to the input. We focus on a class of models employing subword regularization to address robustness and perform extensive evaluations of these models using the robustness measures proposed. Results show that our proposed metrics reveal a clear trend of improved robustness to perturbations when subword regularization methods are used.
Joint translation and unit conversion for end-to-end localization
Apr 10, 2020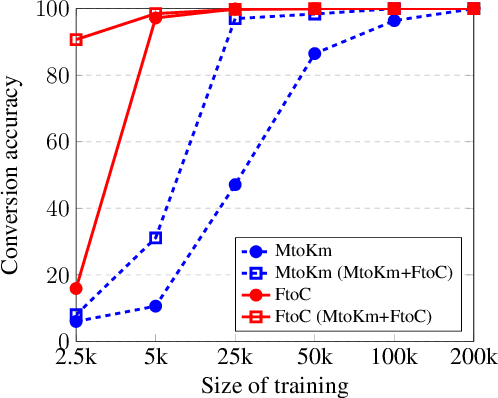

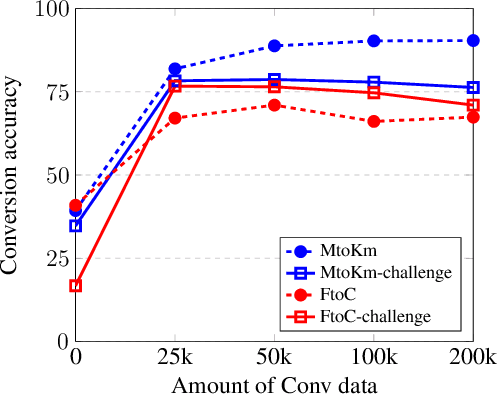
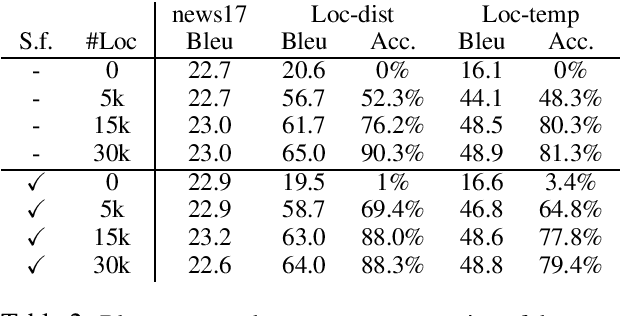
A variety of natural language tasks require processing of textual data which contains a mix of natural language and formal languages such as mathematical expressions. In this paper, we take unit conversions as an example and propose a data augmentation technique which leads to models learning both translation and conversion tasks as well as how to adequately switch between them for end-to-end localization.
Training Neural Machine Translation To Apply Terminology Constraints
Jun 03, 2019
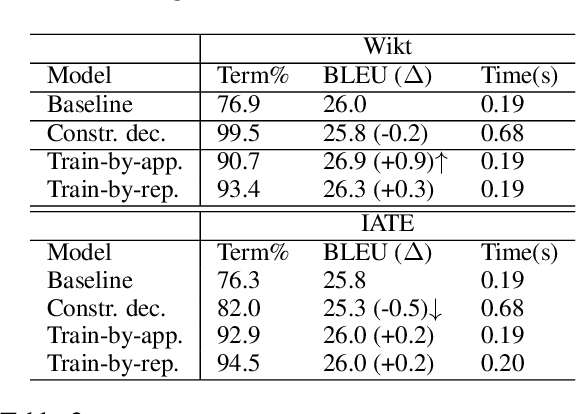

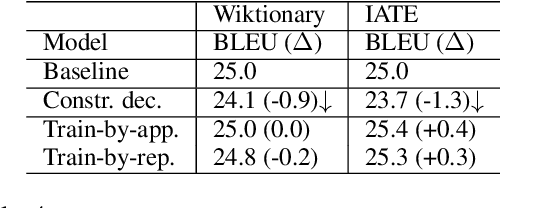
This paper proposes a novel method to inject custom terminology into neural machine translation at run time. Previous works have mainly proposed modifications to the decoding algorithm in order to constrain the output to include run-time-provided target terms. While being effective, these constrained decoding methods add, however, significant computational overhead to the inference step, and, as we show in this paper, can be brittle when tested in realistic conditions. In this paper we approach the problem by training a neural MT system to learn how to use custom terminology when provided with the input. Comparative experiments show that our method is not only more effective than a state-of-the-art implementation of constrained decoding, but is also as fast as constraint-free decoding.
Weakly Supervised Cross-Lingual Named Entity Recognition via Effective Annotation and Representation Projection
Jul 08, 2017



The state-of-the-art named entity recognition (NER) systems are supervised machine learning models that require large amounts of manually annotated data to achieve high accuracy. However, annotating NER data by human is expensive and time-consuming, and can be quite difficult for a new language. In this paper, we present two weakly supervised approaches for cross-lingual NER with no human annotation in a target language. The first approach is to create automatically labeled NER data for a target language via annotation projection on comparable corpora, where we develop a heuristic scheme that effectively selects good-quality projection-labeled data from noisy data. The second approach is to project distributed representations of words (word embeddings) from a target language to a source language, so that the source-language NER system can be applied to the target language without re-training. We also design two co-decoding schemes that effectively combine the outputs of the two projection-based approaches. We evaluate the performance of the proposed approaches on both in-house and open NER data for several target languages. The results show that the combined systems outperform three other weakly supervised approaches on the CoNLL data.