Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFaithful Target Attribute Prediction in Neural Machine Translation
Paper and Code
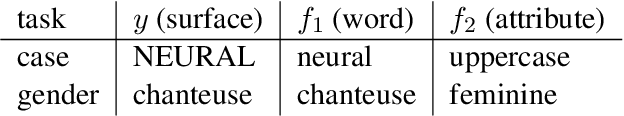
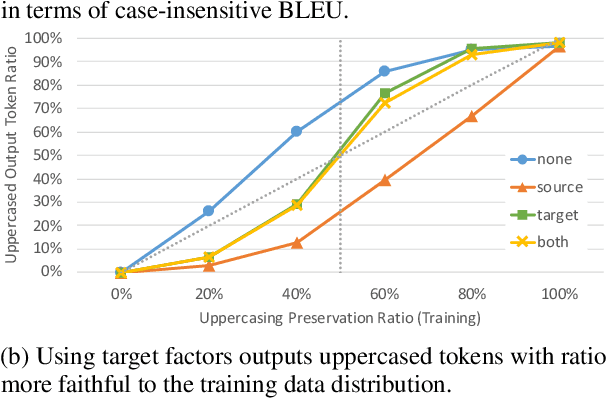
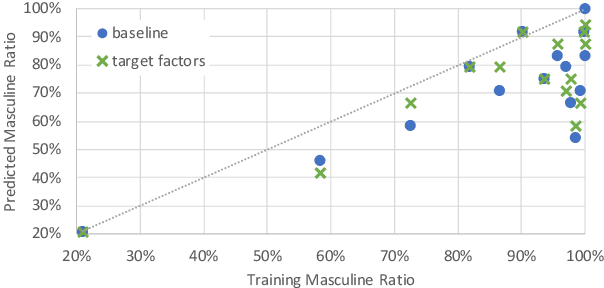
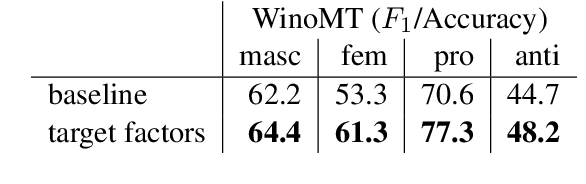
The training data used in NMT is rarely controlled with respect to specific attributes, such as word casing or gender, which can cause errors in translations. We argue that predicting the target word and attributes simultaneously is an effective way to ensure that translations are more faithful to the training data distribution with respect to these attributes. Experimental results on two tasks, uppercased input translation and gender prediction, show that this strategy helps mirror the training data distribution in testing. It also facilitates data augmentation on the task of uppercased input translation.
* Withdrawn from Findings of ACL 2021
View paper on