 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Jun 12, 2024
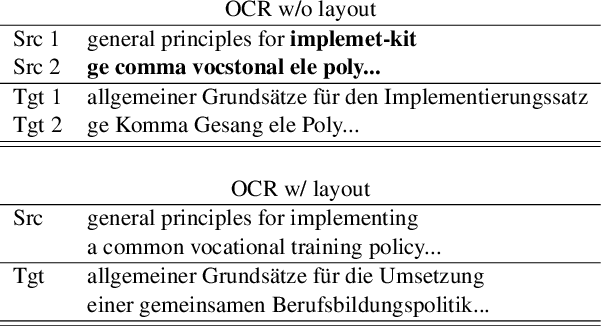

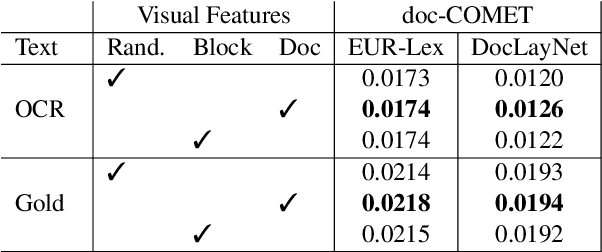
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.
RAMP: Retrieval and Attribute-Marking Enhanced Prompting for Attribute-Controlled Translation
May 26, 2023
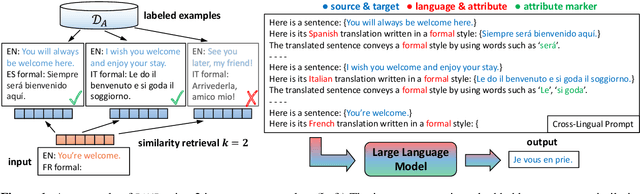
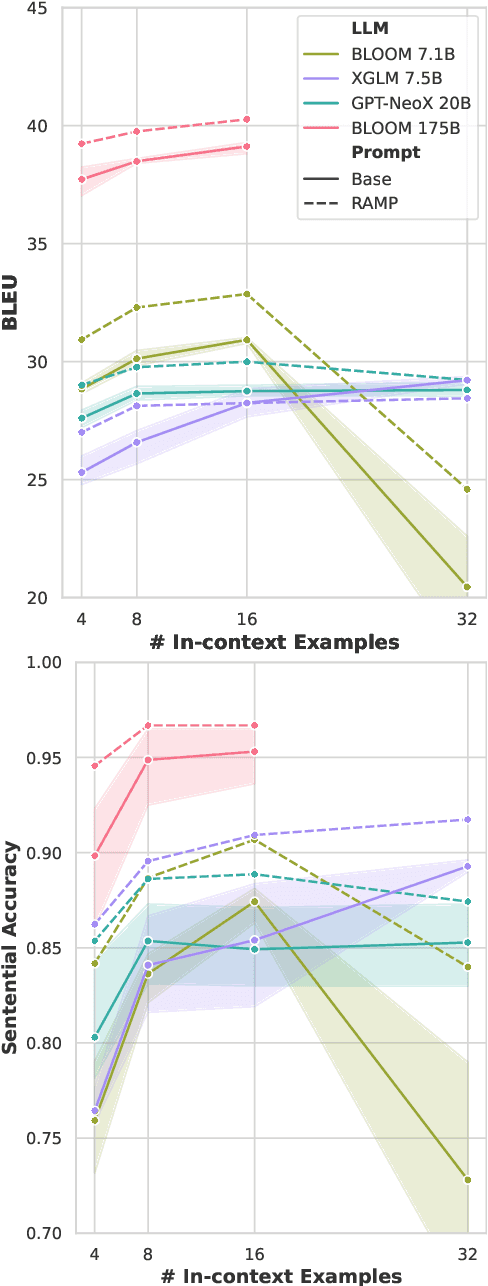
Attribute-controlled translation (ACT) is a subtask of machine translation that involves controlling stylistic or linguistic attributes (like formality and gender) of translation outputs. While ACT has garnered attention in recent years due to its usefulness in real-world applications, progress in the task is currently limited by dataset availability, since most prior approaches rely on supervised methods. To address this limitation, we propose Retrieval and Attribute-Marking enhanced Prompting (RAMP), which leverages large multilingual language models to perform ACT in few-shot and zero-shot settings. RAMP improves generation accuracy over the standard prompting approach by (1) incorporating a semantic similarity retrieval component for selecting similar in-context examples, and (2) marking in-context examples with attribute annotations. Our comprehensive experiments show that RAMP is a viable approach in both zero-shot and few-shot settings.
Pseudo-Label Training and Model Inertia in Neural Machine Translation
May 19, 2023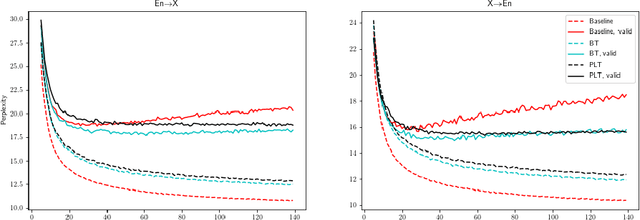


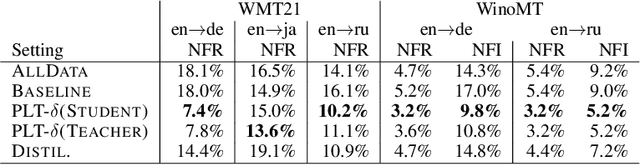
Like many other machine learning applications, neural machine translation (NMT) benefits from over-parameterized deep neural models. However, these models have been observed to be brittle: NMT model predictions are sensitive to small input changes and can show significant variation across re-training or incremental model updates. This work studies a frequently used method in NMT, pseudo-label training (PLT), which is common to the related techniques of forward-translation (or self-training) and sequence-level knowledge distillation. While the effect of PLT on quality is well-documented, we highlight a lesser-known effect: PLT can enhance a model's stability to model updates and input perturbations, a set of properties we call model inertia. We study inertia effects under different training settings and we identify distribution simplification as a mechanism behind the observed results.
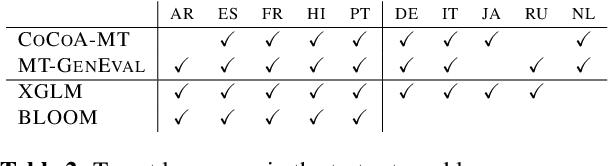
MT-GenEval: A Counterfactual and Contextual Dataset for Evaluating Gender Accuracy in Machine Translation
Nov 02, 2022



As generic machine translation (MT) quality has improved, the need for targeted benchmarks that explore fine-grained aspects of quality has increased. In particular, gender accuracy in translation can have implications in terms of output fluency, translation accuracy, and ethics. In this paper, we introduce MT-GenEval, a benchmark for evaluating gender accuracy in translation from English into eight widely-spoken languages. MT-GenEval complements existing benchmarks by providing realistic, gender-balanced, counterfactual data in eight language pairs where the gender of individuals is unambiguous in the input segment, including multi-sentence segments requiring inter-sentential gender agreement. Our data and code is publicly available under a CC BY SA 3.0 license.
Sockeye 3: Fast Neural Machine Translation with PyTorch
Jul 12, 2022
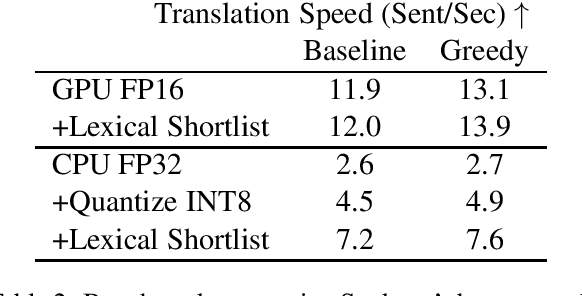
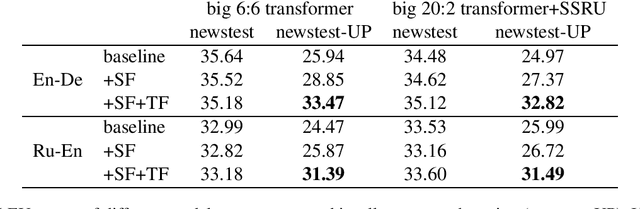

Sockeye 3 is the latest version of the Sockeye toolkit for Neural Machine Translation (NMT). Now based on PyTorch, Sockeye 3 provides faster model implementations and more advanced features with a further streamlined codebase. This enables broader experimentation with faster iteration, efficient training of stronger and faster models, and the flexibility to move new ideas quickly from research to production. When running comparable models, Sockeye 3 is up to 126% faster than other PyTorch implementations on GPUs and up to 292% faster on CPUs. Sockeye 3 is open source software released under the Apache 2.0 license.
Contrastive Representation Learning for Cross-Document Coreference Resolution of Events and Entities
May 23, 2022
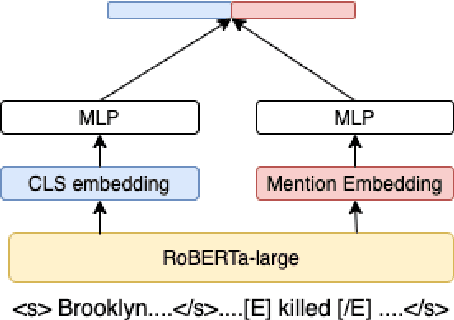
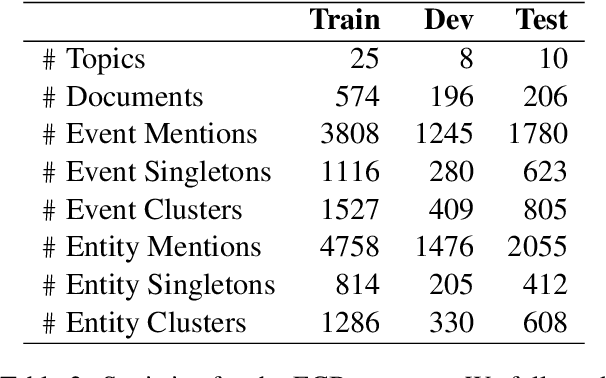
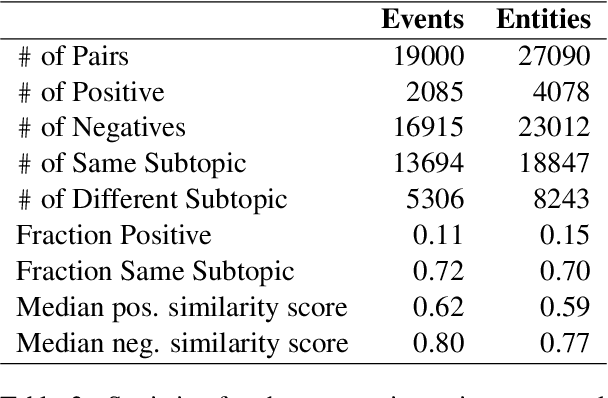
Identifying related entities and events within and across documents is fundamental to natural language understanding. We present an approach to entity and event coreference resolution utilizing contrastive representation learning. Earlier state-of-the-art methods have formulated this problem as a binary classification problem and leveraged large transformers in a cross-encoder architecture to achieve their results. For large collections of documents and corresponding set of $n$ mentions, the necessity of performing $n^{2}$ transformer computations in these earlier approaches can be computationally intensive. We show that it is possible to reduce this burden by applying contrastive learning techniques that only require $n$ transformer computations at inference time. Our method achieves state-of-the-art results on a number of key metrics on the ECB+ corpus and is competitive on others.
CoCoA-MT: A Dataset and Benchmark for Contrastive Controlled MT with Application to Formality
May 09, 2022
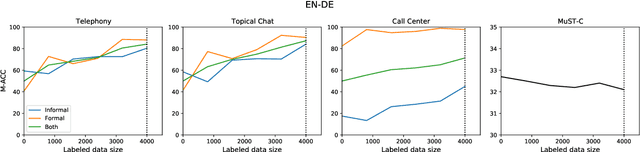

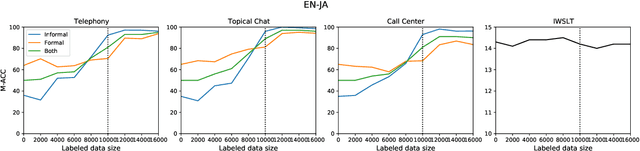
The machine translation (MT) task is typically formulated as that of returning a single translation for an input segment. However, in many cases, multiple different translations are valid and the appropriate translation may depend on the intended target audience, characteristics of the speaker, or even the relationship between speakers. Specific problems arise when dealing with honorifics, particularly translating from English into languages with formality markers. For example, the sentence "Are you sure?" can be translated in German as "Sind Sie sich sicher?" (formal register) or "Bist du dir sicher?" (informal). Using wrong or inconsistent tone may be perceived as inappropriate or jarring for users of certain cultures and demographics. This work addresses the problem of learning to control target language attributes, in this case formality, from a small amount of labeled contrastive data. We introduce an annotated dataset (CoCoA-MT) and an associated evaluation metric for training and evaluating formality-controlled MT models for six diverse target languages. We show that we can train formality-controlled models by fine-tuning on labeled contrastive data, achieving high accuracy (82% in-domain and 73% out-of-domain) while maintaining overall quality.