 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlexDoc: Parameterized Sampling for Diverse Multilingual Synthetic Documents for Training Document Understanding Models
Oct 02, 2025



Developing document understanding models at enterprise scale requires large, diverse, and well-annotated datasets spanning a wide range of document types. However, collecting such data is prohibitively expensive due to privacy constraints, legal restrictions, and the sheer volume of manual annotation needed - costs that can scale into millions of dollars. We introduce FlexDoc, a scalable synthetic data generation framework that combines Stochastic Schemas and Parameterized Sampling to produce realistic, multilingual semi-structured documents with rich annotations. By probabilistically modeling layout patterns, visual structure, and content variability, FlexDoc enables the controlled generation of diverse document variants at scale. Experiments on Key Information Extraction (KIE) tasks demonstrate that FlexDoc-generated data improves the absolute F1 Score by up to 11% when used to augment real datasets, while reducing annotation effort by over 90% compared to traditional hard-template methods. The solution is in active deployment, where it has accelerated the development of enterprise-grade document understanding models while significantly reducing data acquisition and annotation costs.
MetaSynth: Meta-Prompting-Driven Agentic Scaffolds for Diverse Synthetic Data Generation
Apr 17, 2025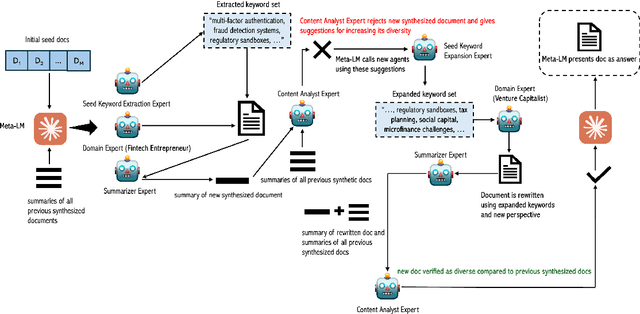



Recent smaller language models such Phi-3.5 and Phi-4 rely on synthetic data generated using larger Language models. Questions remain about leveraging synthetic data for other use cases, such as adapting LLMs to specific domains. A key limitation of synthetic data is low diversity, which negatively impacts its downstream applicability for improving other models. To address this, we propose MetaSynth, a method for generating synthetic data that enhances diversity through meta-prompting, where a language model orchestrates multiple "expert" LLM agents to collaboratively generate data. Using only 25 million tokens of synthetic data generated with MetaSynth, we successfully adapt a well-trained LLM (Mistral-7B-v0.3) to two specialized domains-Finance and Biomedicine-without compromising the capabilities of the resulting model in general tasks. In addition, we evaluate the diversity of our synthetic data using seven automated metrics, and find that it approaches the diversity of LLM pre-training corpora. Continually pre-training Mistral-7B-v0.3 with MetaSynth notably outperforms the base LLM, showing improvements of up to 4.08% in Finance and 13.75% in Biomedicine. The same model shows degraded performance when trained on data generated using a template prompt, even when the template includes prior generations and varying In-Context exemplars of real data. Our findings suggest that a few million tokens of diverse synthetic data without mixing any real data, is sufficient for effective domain adaptation when using MetaSynth.
Active Evaluation Acquisition for Efficient LLM Benchmarking
Oct 08, 2024



As large language models (LLMs) become increasingly versatile, numerous large scale benchmarks have been developed to thoroughly assess their capabilities. These benchmarks typically consist of diverse datasets and prompts to evaluate different aspects of LLM performance. However, comprehensive evaluations on hundreds or thousands of prompts incur tremendous costs in terms of computation, money, and time. In this work, we investigate strategies to improve evaluation efficiency by selecting a subset of examples from each benchmark using a learned policy. Our approach models the dependencies across test examples, allowing accurate prediction of the evaluation outcomes for the remaining examples based on the outcomes of the selected ones. Consequently, we only need to acquire the actual evaluation outcomes for the selected subset. We rigorously explore various subset selection policies and introduce a novel RL-based policy that leverages the captured dependencies. Empirical results demonstrate that our approach significantly reduces the number of evaluation prompts required while maintaining accurate performance estimates compared to previous methods.
Contrastive Training Improves Zero-Shot Classification of Semi-structured Documents
Oct 11, 2022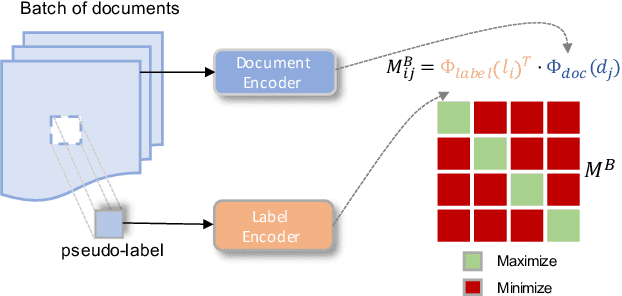


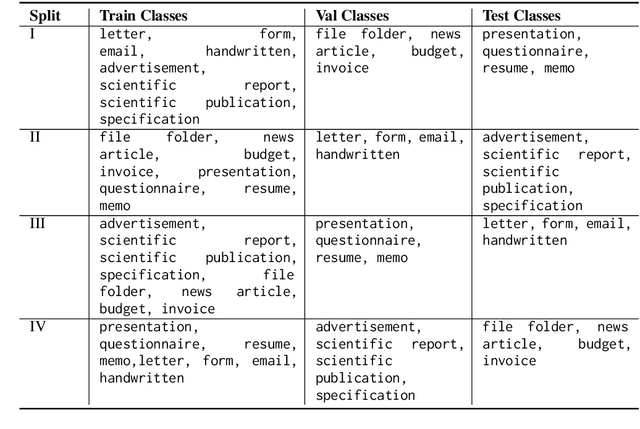
We investigate semi-structured document classification in a zero-shot setting. Classification of semi-structured documents is more challenging than that of standard unstructured documents, as positional, layout, and style information play a vital role in interpreting such documents. The standard classification setting where categories are fixed during both training and testing falls short in dynamic environments where new document categories could potentially emerge. We focus exclusively on the zero-shot setting where inference is done on new unseen classes. To address this task, we propose a matching-based approach that relies on a pairwise contrastive objective for both pretraining and fine-tuning. Our results show a significant boost in Macro F$_1$ from the proposed pretraining step in both supervised and unsupervised zero-shot settings.
Contrastive Representation Learning for Cross-Document Coreference Resolution of Events and Entities
May 23, 2022
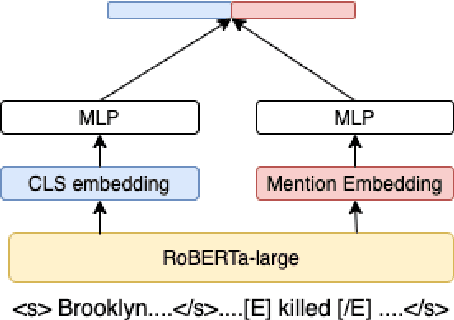
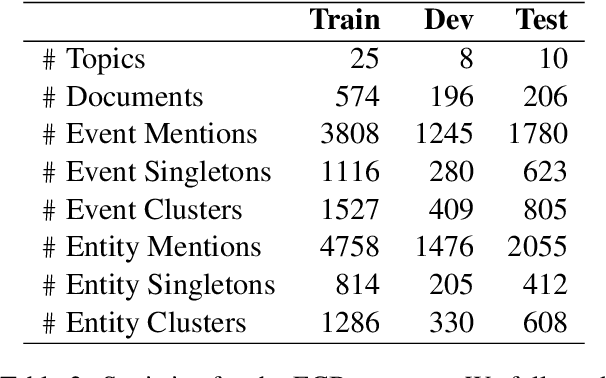
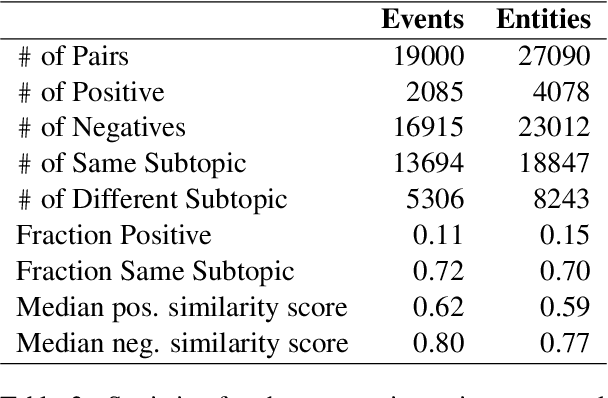
Identifying related entities and events within and across documents is fundamental to natural language understanding. We present an approach to entity and event coreference resolution utilizing contrastive representation learning. Earlier state-of-the-art methods have formulated this problem as a binary classification problem and leveraged large transformers in a cross-encoder architecture to achieve their results. For large collections of documents and corresponding set of $n$ mentions, the necessity of performing $n^{2}$ transformer computations in these earlier approaches can be computationally intensive. We show that it is possible to reduce this burden by applying contrastive learning techniques that only require $n$ transformer computations at inference time. Our method achieves state-of-the-art results on a number of key metrics on the ECB+ corpus and is competitive on others.