 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMetaSynth: Meta-Prompting-Driven Agentic Scaffolds for Diverse Synthetic Data Generation
Apr 17, 2025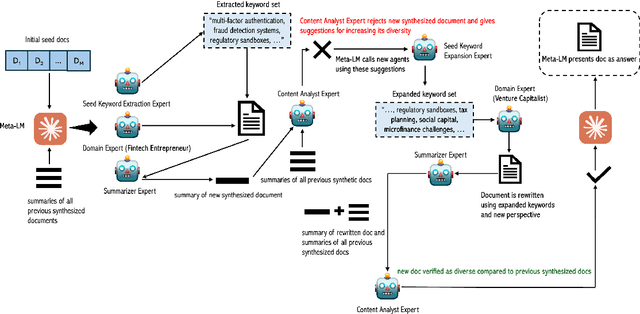



Recent smaller language models such Phi-3.5 and Phi-4 rely on synthetic data generated using larger Language models. Questions remain about leveraging synthetic data for other use cases, such as adapting LLMs to specific domains. A key limitation of synthetic data is low diversity, which negatively impacts its downstream applicability for improving other models. To address this, we propose MetaSynth, a method for generating synthetic data that enhances diversity through meta-prompting, where a language model orchestrates multiple "expert" LLM agents to collaboratively generate data. Using only 25 million tokens of synthetic data generated with MetaSynth, we successfully adapt a well-trained LLM (Mistral-7B-v0.3) to two specialized domains-Finance and Biomedicine-without compromising the capabilities of the resulting model in general tasks. In addition, we evaluate the diversity of our synthetic data using seven automated metrics, and find that it approaches the diversity of LLM pre-training corpora. Continually pre-training Mistral-7B-v0.3 with MetaSynth notably outperforms the base LLM, showing improvements of up to 4.08% in Finance and 13.75% in Biomedicine. The same model shows degraded performance when trained on data generated using a template prompt, even when the template includes prior generations and varying In-Context exemplars of real data. Our findings suggest that a few million tokens of diverse synthetic data without mixing any real data, is sufficient for effective domain adaptation when using MetaSynth.
Say Less, Mean More: Leveraging Pragmatics in Retrieval-Augmented Generation
Feb 25, 2025We propose a simple, unsupervised method that injects pragmatic principles in retrieval-augmented generation (RAG) frameworks such as Dense Passage Retrieval~\cite{karpukhin2020densepassageretrievalopendomain} to enhance the utility of retrieved contexts. Our approach first identifies which sentences in a pool of documents retrieved by RAG are most relevant to the question at hand, cover all the topics addressed in the input question and no more, and then highlights these sentences within their context, before they are provided to the LLM, without truncating or altering the context in any other way. We show that this simple idea brings consistent improvements in experiments on three question answering tasks (ARC-Challenge, PubHealth and PopQA) using five different LLMs. It notably enhances relative accuracy by up to 19.7\% on PubHealth and 10\% on ARC-Challenge compared to a conventional RAG system.
ELLEN: Extremely Lightly Supervised Learning For Efficient Named Entity Recognition
Mar 26, 2024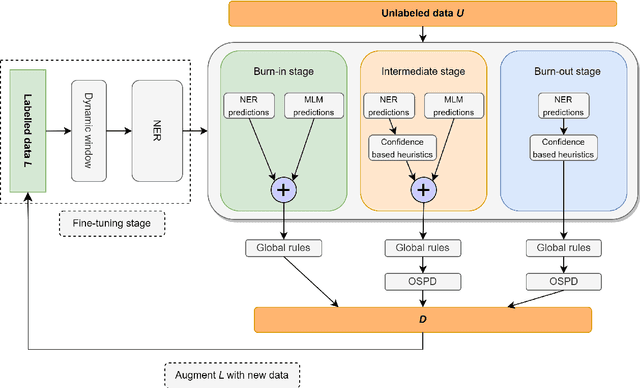
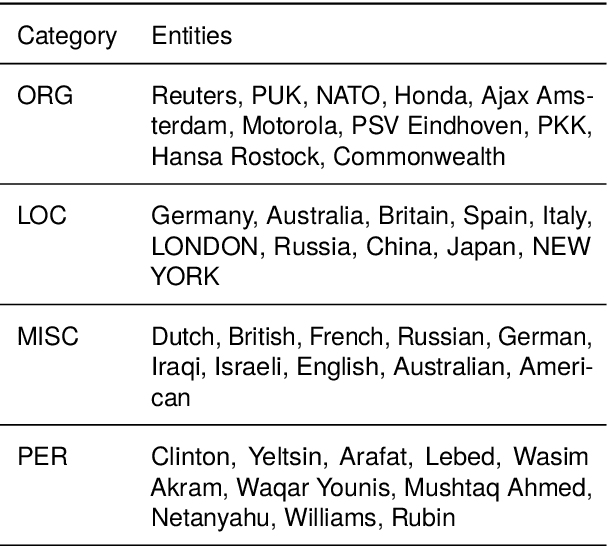
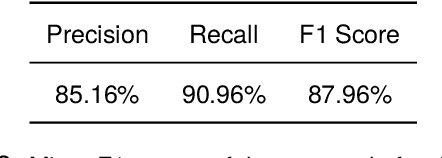
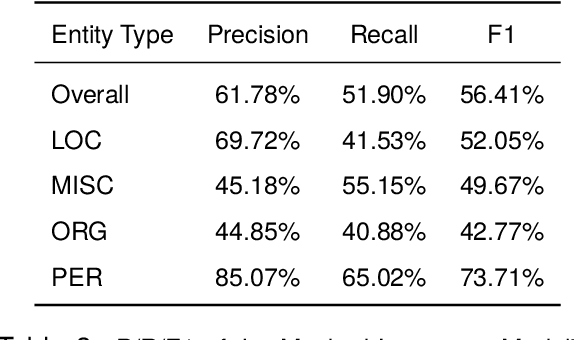
In this work, we revisit the problem of semi-supervised named entity recognition (NER) focusing on extremely light supervision, consisting of a lexicon containing only 10 examples per class. We introduce ELLEN, a simple, fully modular, neuro-symbolic method that blends fine-tuned language models with linguistic rules. These rules include insights such as ''One Sense Per Discourse'', using a Masked Language Model as an unsupervised NER, leveraging part-of-speech tags to identify and eliminate unlabeled entities as false negatives, and other intuitions about classifier confidence scores in local and global context. ELLEN achieves very strong performance on the CoNLL-2003 dataset when using the minimal supervision from the lexicon above. It also outperforms most existing (and considerably more complex) semi-supervised NER methods under the same supervision settings commonly used in the literature (i.e., 5% of the training data). Further, we evaluate our CoNLL-2003 model in a zero-shot scenario on WNUT-17 where we find that it outperforms GPT-3.5 and achieves comparable performance to GPT-4. In a zero-shot setting, ELLEN also achieves over 75% of the performance of a strong, fully supervised model trained on gold data. Our code is available at: https://github.com/hriaz17/ELLEN.
Best of Both Worlds: A Pliable and Generalizable Neuro-Symbolic Approach for Relation Classification
Mar 05, 2024



This paper introduces a novel neuro-symbolic architecture for relation classification (RC) that combines rule-based methods with contemporary deep learning techniques. This approach capitalizes on the strengths of both paradigms: the adaptability of rule-based systems and the generalization power of neural networks. Our architecture consists of two components: a declarative rule-based model for transparent classification and a neural component to enhance rule generalizability through semantic text matching. Notably, our semantic matcher is trained in an unsupervised domain-agnostic way, solely with synthetic data. Further, these components are loosely coupled, allowing for rule modifications without retraining the semantic matcher. In our evaluation, we focused on two few-shot relation classification datasets: Few-Shot TACRED and a Few-Shot version of NYT29. We show that our proposed method outperforms previous state-of-the-art models in three out of four settings, despite not seeing any human-annotated training data. Further, we show that our approach remains modular and pliable, i.e., the corresponding rules can be locally modified to improve the overall model. Human interventions to the rules for the TACRED relation \texttt{org:parents} boost the performance on that relation by as much as 26\% relative improvement, without negatively impacting the other relations, and without retraining the semantic matching component.
Synthetic Dataset for Evaluating Complex Compositional Knowledge for Natural Language Inference
Jul 12, 2023We introduce a synthetic dataset called Sentences Involving Complex Compositional Knowledge (SICCK) and a novel analysis that investigates the performance of Natural Language Inference (NLI) models to understand compositionality in logic. We produce 1,304 sentence pairs by modifying 15 examples from the SICK dataset (Marelli et al., 2014). To this end, we modify the original texts using a set of phrases - modifiers that correspond to universal quantifiers, existential quantifiers, negation, and other concept modifiers in Natural Logic (NL) (MacCartney, 2009). We use these phrases to modify the subject, verb, and object parts of the premise and hypothesis. Lastly, we annotate these modified texts with the corresponding entailment labels following NL rules. We conduct a preliminary verification of how well the change in the structural and semantic composition is captured by neural NLI models, in both zero-shot and fine-tuned scenarios. We found that the performance of NLI models under the zero-shot setting is poor, especially for modified sentences with negation and existential quantifiers. After fine-tuning this dataset, we observe that models continue to perform poorly over negation, existential and universal modifiers.