 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePILOT: Steering Synthetic Data Generation with Psychological & Linguistic Output Targeting
Sep 18, 2025Generative AI applications commonly leverage user personas as a steering mechanism for synthetic data generation, but reliance on natural language representations forces models to make unintended inferences about which attributes to emphasize, limiting precise control over outputs. We introduce PILOT (Psychological and Linguistic Output Targeting), a two-phase framework for steering large language models with structured psycholinguistic profiles. In Phase 1, PILOT translates natural language persona descriptions into multidimensional profiles with normalized scores across linguistic and psychological dimensions. In Phase 2, these profiles guide generation along measurable axes of variation. We evaluate PILOT across three state-of-the-art LLMs (Mistral Large 2, Deepseek-R1, LLaMA 3.3 70B) using 25 synthetic personas under three conditions: Natural-language Persona Steering (NPS), Schema-Based Steering (SBS), and Hybrid Persona-Schema Steering (HPS). Results demonstrate that schema-based approaches significantly reduce artificial-sounding persona repetition while improving output coherence, with silhouette scores increasing from 0.098 to 0.237 and topic purity from 0.773 to 0.957. Our analysis reveals a fundamental trade-off: SBS produces more concise outputs with higher topical consistency, while NPS offers greater lexical diversity but reduced predictability. HPS achieves a balance between these extremes, maintaining output variety while preserving structural consistency. Expert linguistic evaluation confirms that PILOT maintains high response quality across all conditions, with no statistically significant differences between steering approaches.
MetaSynth: Meta-Prompting-Driven Agentic Scaffolds for Diverse Synthetic Data Generation
Apr 17, 2025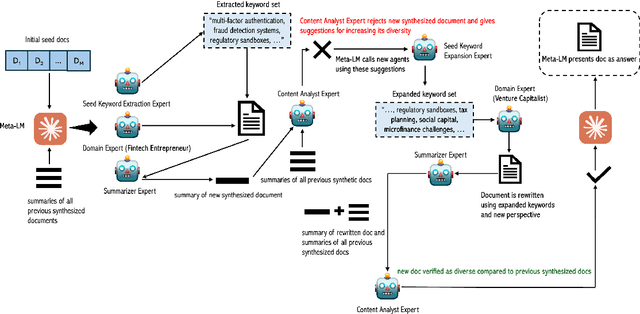



Recent smaller language models such Phi-3.5 and Phi-4 rely on synthetic data generated using larger Language models. Questions remain about leveraging synthetic data for other use cases, such as adapting LLMs to specific domains. A key limitation of synthetic data is low diversity, which negatively impacts its downstream applicability for improving other models. To address this, we propose MetaSynth, a method for generating synthetic data that enhances diversity through meta-prompting, where a language model orchestrates multiple "expert" LLM agents to collaboratively generate data. Using only 25 million tokens of synthetic data generated with MetaSynth, we successfully adapt a well-trained LLM (Mistral-7B-v0.3) to two specialized domains-Finance and Biomedicine-without compromising the capabilities of the resulting model in general tasks. In addition, we evaluate the diversity of our synthetic data using seven automated metrics, and find that it approaches the diversity of LLM pre-training corpora. Continually pre-training Mistral-7B-v0.3 with MetaSynth notably outperforms the base LLM, showing improvements of up to 4.08% in Finance and 13.75% in Biomedicine. The same model shows degraded performance when trained on data generated using a template prompt, even when the template includes prior generations and varying In-Context exemplars of real data. Our findings suggest that a few million tokens of diverse synthetic data without mixing any real data, is sufficient for effective domain adaptation when using MetaSynth.
ADEQA: A Question Answer based approach for joint ADE-Suspect Extraction using Sequence-To-Sequence Transformers
Dec 20, 2024Early identification of Adverse Drug Events (ADE) is critical for taking prompt actions while introducing new drugs into the market. These ADEs information are available through various unstructured data sources like clinical study reports, patient health records, social media posts, etc. Extracting ADEs and the related suspect drugs using machine learning is a challenging task due to the complex linguistic relations between drug ADE pairs in textual data and unavailability of large corpus of labelled datasets. This paper introduces ADEQA, a question-answer(QA) based approach using quasi supervised labelled data and sequence-to-sequence transformers to extract ADEs, drug suspects and the relationships between them. Unlike traditional QA models, natural language generation (NLG) based models don't require extensive token level labelling and thereby reduces the adoption barrier significantly. On a public ADE corpus, we were able to achieve state-of-the-art results with an F1 score of 94% on establishing the relationships between ADEs and the respective suspects.