 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeM3T: A New Benchmark Dataset for Multi-Modal Document-Level Machine Translation
Paper and Code

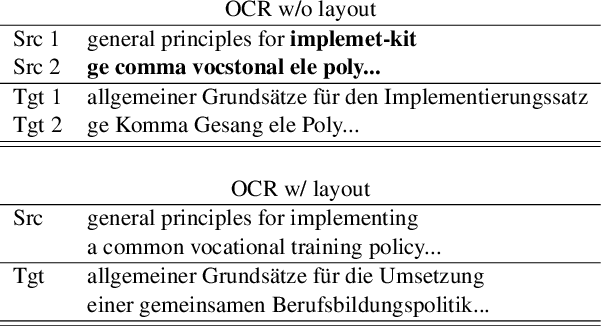

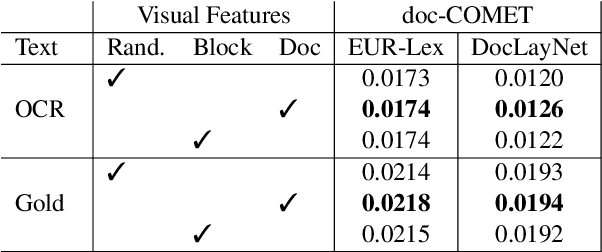
Document translation poses a challenge for Neural Machine Translation (NMT) systems. Most document-level NMT systems rely on meticulously curated sentence-level parallel data, assuming flawless extraction of text from documents along with their precise reading order. These systems also tend to disregard additional visual cues such as the document layout, deeming it irrelevant. However, real-world documents often possess intricate text layouts that defy these assumptions. Extracting information from Optical Character Recognition (OCR) or heuristic rules can result in errors, and the layout (e.g., paragraphs, headers) may convey relationships between distant sections of text. This complexity is particularly evident in widely used PDF documents, which represent information visually. This paper addresses this gap by introducing M3T, a novel benchmark dataset tailored to evaluate NMT systems on the comprehensive task of translating semi-structured documents. This dataset aims to bridge the evaluation gap in document-level NMT systems, acknowledging the challenges posed by rich text layouts in real-world applications.