 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated segmentation of microtomography imaging of Egyptian mummies
May 14, 2021
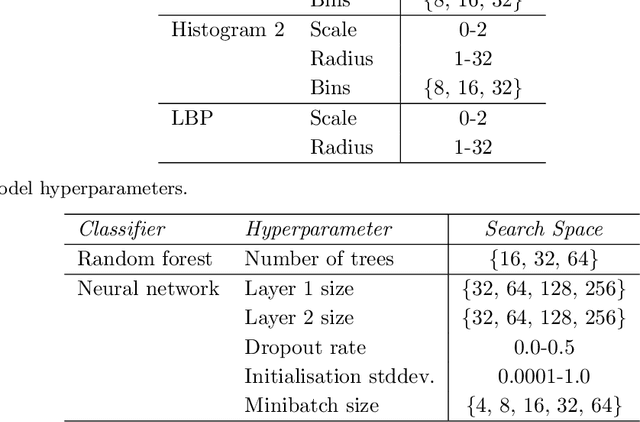

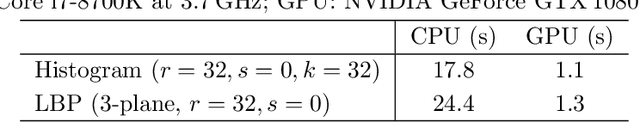
Propagation Phase Contrast Synchrotron Microtomography (PPC-SR${\mu}$CT) is the gold standard for non-invasive and non-destructive access to internal structures of archaeological remains. In this analysis, the virtual specimen needs to be segmented to separate different parts or materials, a process that normally requires considerable human effort. In the Automated SEgmentation of Microtomography Imaging (ASEMI) project, we developed a tool to automatically segment these volumetric images, using manually segmented samples to tune and train a machine learning model. For a set of four specimens of ancient Egyptian animal mummies we achieve an overall accuracy of 94-98% when compared with manually segmented slices, approaching the results of off-the-shelf commercial software using deep learning (97-99%) at much lower complexity. A qualitative analysis of the segmented output shows that our results are close in term of usability to those from deep learning, justifying the use of these techniques.
Face Hallucination using Linear Models of Coupled Sparse Support
Dec 18, 2015



Most face super-resolution methods assume that low-resolution and high-resolution manifolds have similar local geometrical structure, hence learn local models on the lowresolution manifolds (e.g. sparse or locally linear embedding models), which are then applied on the high-resolution manifold. However, the low-resolution manifold is distorted by the oneto-many relationship between low- and high- resolution patches. This paper presents a method which learns linear models based on the local geometrical structure on the high-resolution manifold rather than on the low-resolution manifold. For this, in a first step, the low-resolution patch is used to derive a globally optimal estimate of the high-resolution patch. The approximated solution is shown to be close in Euclidean space to the ground-truth but is generally smooth and lacks the texture details needed by state-ofthe-art face recognizers. This first estimate allows us to find the support of the high-resolution manifold using sparse coding (SC), which are then used as support for learning a local projection (or upscaling) model between the low-resolution and the highresolution manifolds using Multivariate Ridge Regression (MRR). Experimental results show that the proposed method outperforms six face super-resolution methods in terms of both recognition and quality. These results also reveal that the recognition and quality are significantly affected by the method used for stitching all super-resolved patches together, where quilting was found to better preserve the texture details which helps to achieve higher recognition rates.