 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExploring Deep Learning Image Super-Resolution for Iris Recognition
Nov 02, 2023

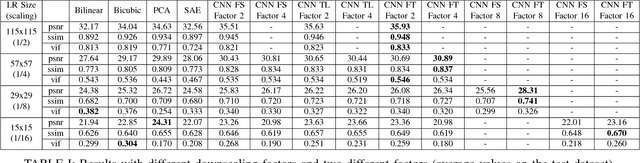
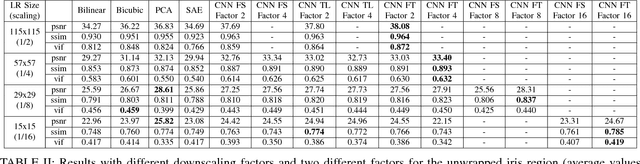
In this work we test the ability of deep learning methods to provide an end-to-end mapping between low and high resolution images applying it to the iris recognition problem. Here, we propose the use of two deep learning single-image super-resolution approaches: Stacked Auto-Encoders (SAE) and Convolutional Neural Networks (CNN) with the most possible lightweight structure to achieve fast speed, preserve local information and reduce artifacts at the same time. We validate the methods with a database of 1.872 near-infrared iris images with quality assessment and recognition experiments showing the superiority of deep learning approaches over the compared algorithms.
Multitemporal and multispectral data fusion for super-resolution of Sentinel-2 images
Jan 26, 2023

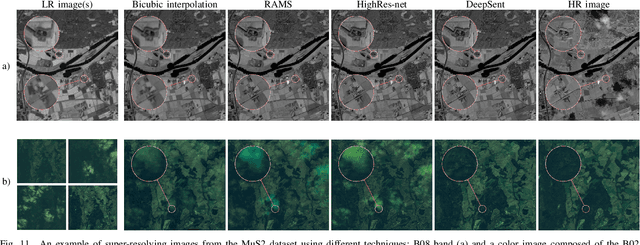

Multispectral Sentinel-2 images are a valuable source of Earth observation data, however spatial resolution of their spectral bands limited to 10 m, 20 m, and 60 m ground sampling distance remains insufficient in many cases. This problem can be addressed with super-resolution, aimed at reconstructing a high-resolution image from a low-resolution observation. For Sentinel-2, spectral information fusion allows for enhancing the 20 m and 60 m bands to the 10 m resolution. Also, there were attempts to combine multitemporal stacks of individual Sentinel-2 bands, however these two approaches have not been combined so far. In this paper, we introduce DeepSent -- a new deep network for super-resolving multitemporal series of multispectral Sentinel-2 images. It is underpinned with information fusion performed simultaneously in the spectral and temporal dimensions to generate an enlarged multispectral image. In our extensive experimental study, we demonstrate that our solution outperforms other state-of-the-art techniques that realize either multitemporal or multispectral data fusion. Furthermore, we show that the advantage of DeepSent results from how these two fusion types are combined in a single architecture, which is superior to performing such fusion in a sequential manner. Importantly, we have applied our method to super-resolve real-world Sentinel-2 images, enhancing the spatial resolution of all the spectral bands to 3.3 m nominal ground sampling distance, and we compare the outcome with very high-resolution WorldView-2 images. We will publish our implementation upon paper acceptance, and we expect it will increase the possibilities of exploiting super-resolved Sentinel-2 images in real-life applications.
The Best of Both Worlds: a Framework for Combining Degradation Prediction with High Performance Super-Resolution Networks
Nov 09, 2022



To date, the best-performing blind super-resolution (SR) techniques follow one of two paradigms: A) generate and train a standard SR network on synthetic low-resolution - high-resolution (LR - HR) pairs or B) attempt to predict the degradations an LR image has suffered and use these to inform a customised SR network. Despite significant progress, subscribers to the former miss out on useful degradation information that could be used to improve the SR process. On the other hand, followers of the latter rely on weaker SR networks, which are significantly outperformed by the latest architectural advancements. In this work, we present a framework for combining any blind SR prediction mechanism with any deep SR network, using a metadata insertion block to insert prediction vectors into SR network feature maps. Through comprehensive testing, we prove that state-of-the-art contrastive and iterative prediction schemes can be successfully combined with high-performance SR networks such as RCAN and HAN within our framework. We show that our hybrid models consistently achieve stronger SR performance than both their non-blind and blind counterparts. Furthermore, we demonstrate our framework's robustness by predicting degradations and super-resolving images from a complex pipeline of blurring, noise and compression.
Very Low-Resolution Iris Recognition Via Eigen-Patch Super-Resolution and Matcher Fusion
Oct 18, 2022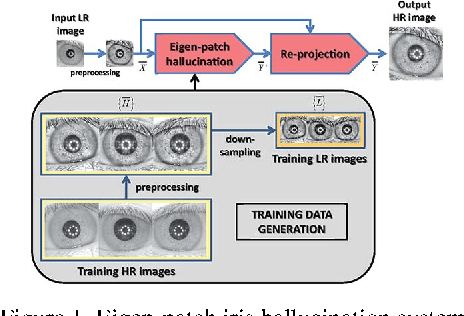
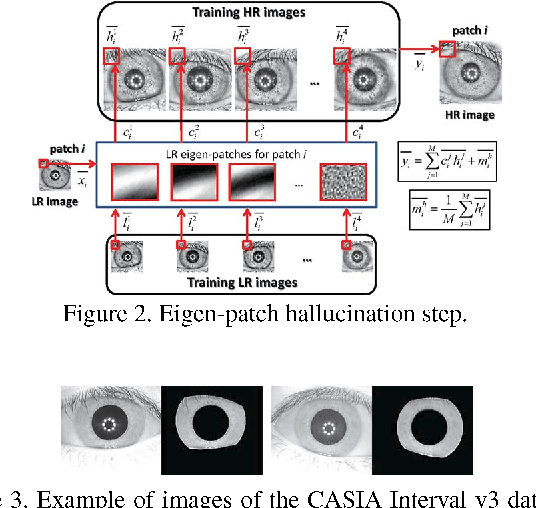
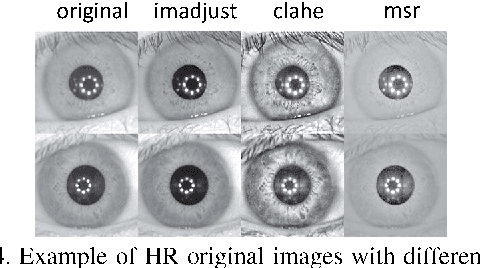
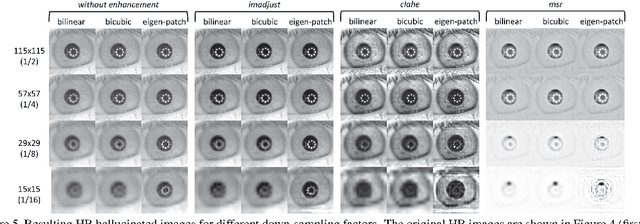
Current research in iris recognition is moving towards enabling more relaxed acquisition conditions. This has effects on the quality of acquired images, with low resolution being a predominant issue. Here, we evaluate a super-resolution algorithm used to reconstruct iris images based on Eigen-transformation of local image patches. Each patch is reconstructed separately, allowing better quality of enhanced images by preserving local information. Contrast enhancement is used to improve the reconstruction quality, while matcher fusion has been adopted to improve iris recognition performance. We validate the system using a database of 1,872 near-infrared iris images. The presented approach is superior to bilinear or bicubic interpolation, especially at lower resolutions, and the fusion of the two systems pushes the EER to below 5% for down-sampling factors up to a image size of only 13x13.
Face2Text revisited: Improved data set and baseline results
May 24, 2022
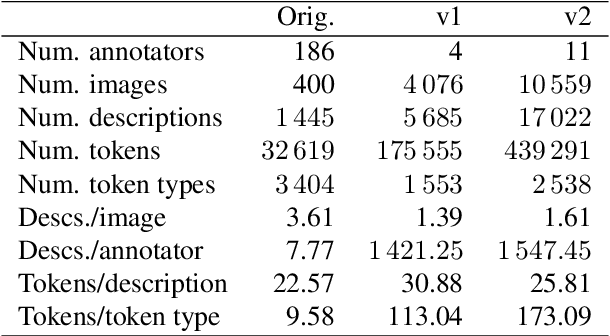

Current image description generation models do not transfer well to the task of describing human faces. To encourage the development of more human-focused descriptions, we developed a new data set of facial descriptions based on the CelebA image data set. We describe the properties of this data set, and present results from a face description generator trained on it, which explores the feasibility of using transfer learning from VGGFace/ResNet CNNs. Comparisons are drawn through both automated metrics and human evaluation by 76 English-speaking participants. The descriptions generated by the VGGFace-LSTM + Attention model are closest to the ground truth according to human evaluation whilst the ResNet-LSTM + Attention model obtained the highest CIDEr and CIDEr-D results (1.252 and 0.686 respectively). Together, the new data set and these experimental results provide data and baselines for future work in this area.
Super-Resolution for Selfie Biometrics: Introduction and Application to Face and Iris
Apr 12, 2022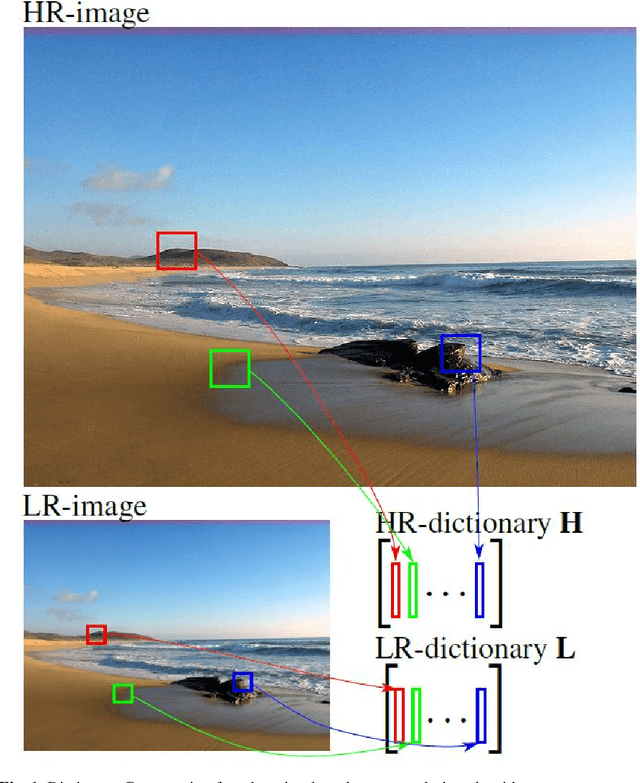
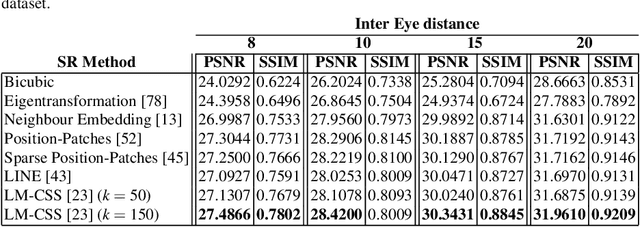
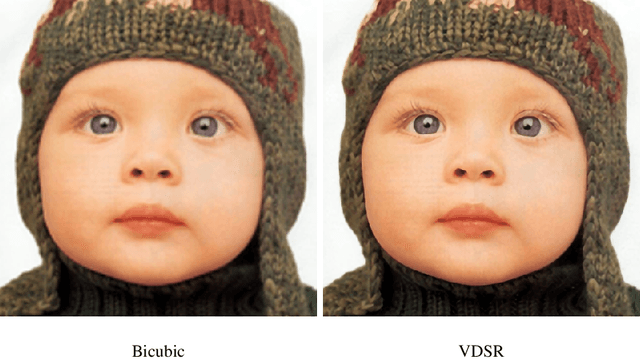
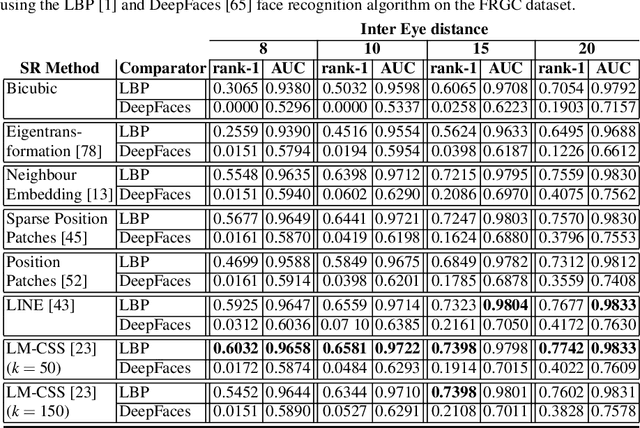
The lack of resolution has a negative impact on the performance of image-based biometrics. Many applications which are becoming ubiquitous in mobile devices do not operate in a controlled environment, and their performance significantly drops due to the lack of pixel resolution. While many generic super-resolution techniques have been studied to restore low-resolution images for biometrics, the results obtained are not always as desired. Those generic methods are usually aimed to enhance the visual appearance of the scene. However, producing an overall visual enhancement of biometric images does not necessarily correlate with a better recognition performance. Such techniques are designed to restore generic images and therefore do not exploit the specific structure found in biometric images (e.g. iris or faces), which causes the solution to be sub-optimal. For this reason, super-resolution techniques have to be adapted for the particularities of images from a specific biometric modality. In recent years, there has been an increased interest in the application of super-resolution to different biometric modalities, such as face iris, gait or fingerprint. This chapter presents an overview of recent advances in super-resolution reconstruction of face and iris images, which are the two prevalent modalities in selfie biometrics. We also provide experimental results using several state-of-the-art reconstruction algorithms, demonstrating the benefits of using super-resolution to improve the quality of face and iris images prior to classification. In the reported experiments, we study the application of super-resolution to face and iris images captured in the visible range, using experimental setups that represent well the selfie biometrics scenario.
Improving Super-Resolution Performance using Meta-Attention Layers
Oct 27, 2021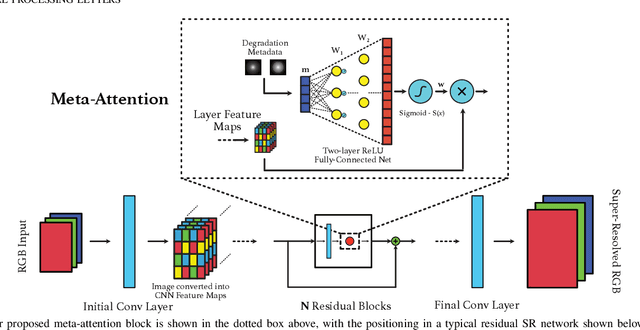
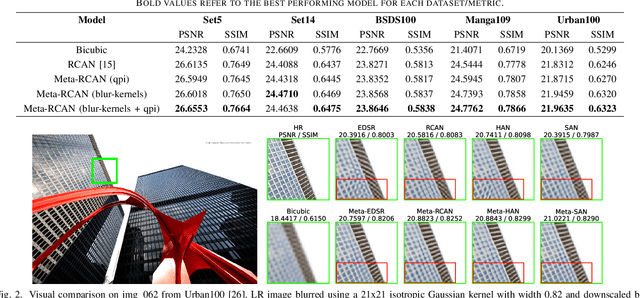
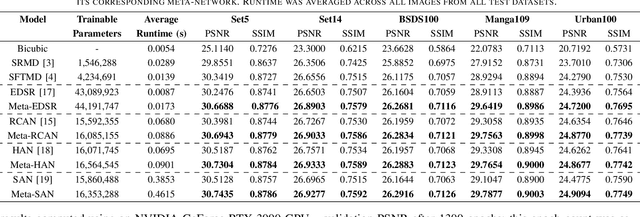
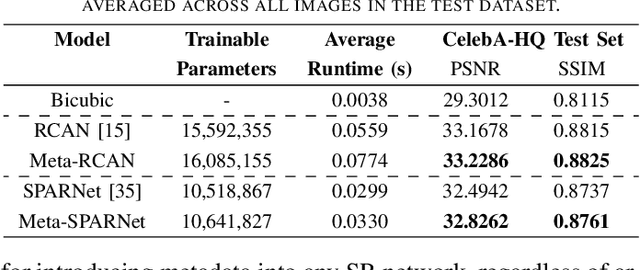
Convolutional Neural Networks (CNNs) have achieved impressive results across many super-resolution (SR) and image restoration tasks. While many such networks can upscale low-resolution (LR) images using just the raw pixel-level information, the ill-posed nature of SR can make it difficult to accurately super-resolve an image which has undergone multiple different degradations. Additional information (metadata) describing the degradation process (such as the blur kernel applied, compression level, etc.) can guide networks to super-resolve LR images with higher fidelity to the original source. Previous attempts at informing SR networks with degradation parameters have indeed been able to improve performance in a number of scenarios. However, due to the fully-convolutional nature of many SR networks, most of these metadata fusion methods either require a complete architectural change, or necessitate the addition of significant extra complexity. Thus, these approaches are difficult to introduce into arbitrary SR networks without considerable design alterations. In this paper, we introduce meta-attention, a simple mechanism which allows any SR CNN to exploit the information available in relevant degradation parameters. The mechanism functions by translating the metadata into a channel attention vector, which in turn selectively modulates the network's feature maps. Incorporating meta-attention into SR networks is straightforward, as it requires no specific type of architecture to function correctly. Extensive testing has shown that meta-attention can consistently improve the pixel-level accuracy of state-of-the-art (SOTA) networks when provided with relevant degradation metadata. For PSNR, the gain on blurred/downsampled (X4) images is of 0.2969 dB (on average) and 0.3320 dB for SOTA general and face SR models, respectively.
A Simple Framework to Leverage State-Of-The-Art Single-Image Super-Resolution Methods to Restore Light Fields
Sep 27, 2018

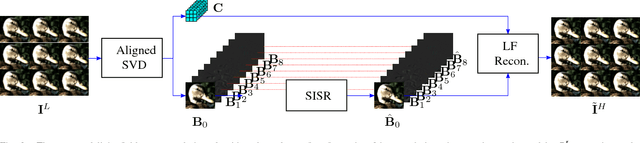
Plenoptic cameras offer a cost effective solution to capture light fields by multiplexing multiple views on a single image sensor. However, the high angular resolution is achieved at the expense of reducing the spatial resolution of each view by orders of magnitude compared to the raw sensor image. While light field super-resolution is still at an early stage, the field of single image super-resolution (SISR) has recently known significant advances with the use of deep learning techniques. This paper describes a simple framework allowing us to leverage state-of-the-art SISR techniques into light fields, while taking into account specific light field geometrical constraints. The idea is to first compute a representation compacting most of the light field energy into as few components as possible. This is achieved by aligning the light field using optical flows and then by decomposing the aligned light field using singular value decomposition (SVD). The principal basis captures the information that is coherent across all the views, while the other basis contain the high angular frequencies. Super-resolving this principal basis using an SISR method allows us to super-resolve all the information that is coherent across the entire light field. This framework allows the proposed light field super-resolution method to inherit the benefits of the SISR method used. Experimental results show that the proposed method is competitive, and most of the time superior, to recent light field super-resolution methods in terms of both PSNR and SSIM quality metrics, with a lower complexity.
Face2Text: Collecting an Annotated Image Description Corpus for the Generation of Rich Face Descriptions
Mar 10, 2018
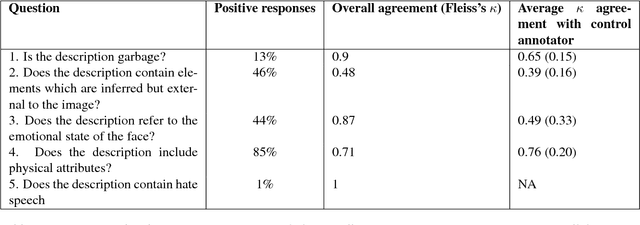
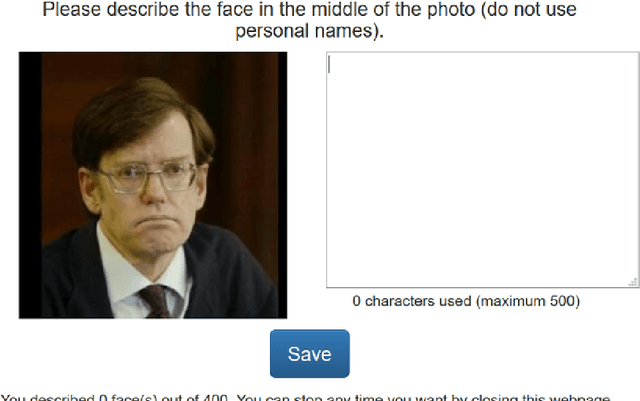
The past few years have witnessed renewed interest in NLP tasks at the interface between vision and language. One intensively-studied problem is that of automatically generating text from images. In this paper, we extend this problem to the more specific domain of face description. Unlike scene descriptions, face descriptions are more fine-grained and rely on attributes extracted from the image, rather than objects and relations. Given that no data exists for this task, we present an ongoing crowdsourcing study to collect a corpus of descriptions of face images taken `in the wild'. To gain a better understanding of the variation we find in face description and the possible issues that this may raise, we also conducted an annotation study on a subset of the corpus. Primarily, we found descriptions to refer to a mixture of attributes, not only physical, but also emotional and inferential, which is bound to create further challenges for current image-to-text methods.
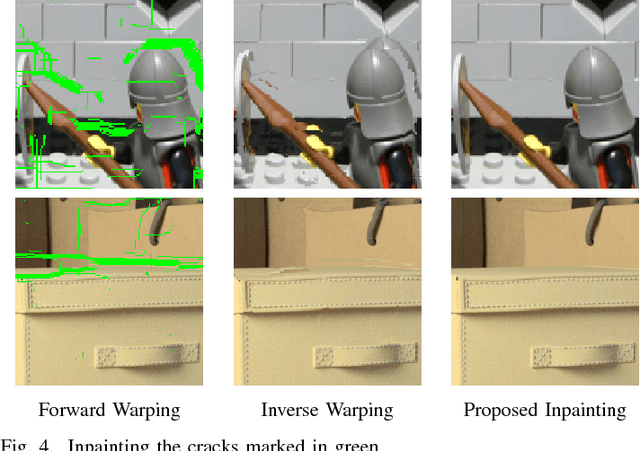
Light Field Super-Resolution using a Low-Rank Prior and Deep Convolutional Neural Networks
Jan 12, 2018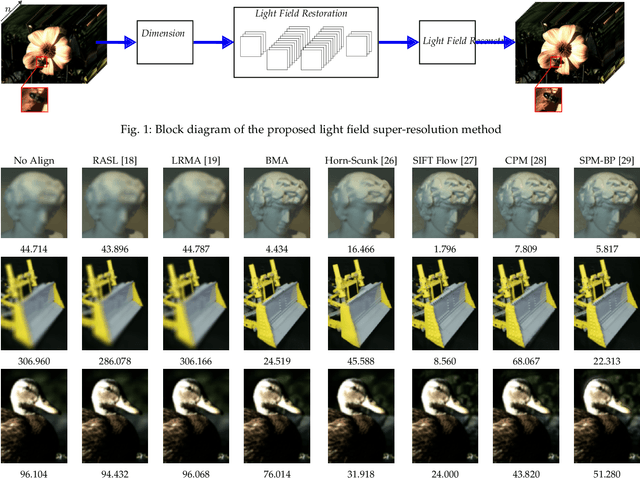
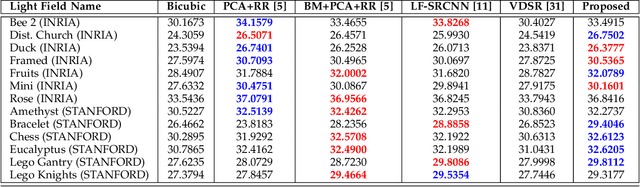
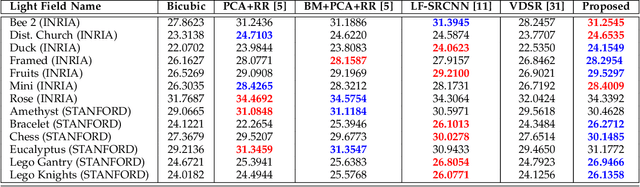

Light field imaging has recently known a regain of interest due to the availability of practical light field capturing systems that offer a wide range of applications in the field of computer vision. However, capturing high-resolution light fields remains technologically challenging since the increase in angular resolution is often accompanied by a significant reduction in spatial resolution. This paper describes a learning-based spatial light field super-resolution method that allows the restoration of the entire light field with consistency across all sub-aperture images. The algorithm first uses optical flow to align the light field and then reduces its angular dimension using low-rank approximation. We then consider the linearly independent columns of the resulting low-rank model as an embedding, which is restored using a deep convolutional neural network (DCNN). The super-resolved embedding is then used to reconstruct the remaining sub-aperture images. The original disparities are restored using inverse warping where missing pixels are approximated using a novel light field inpainting algorithm. Experimental results show that the proposed method outperforms existing light field super-resolution algorithms, achieving PSNR gains of 0.23 dB over the second best performing method. This performance can be further improved using iterative back-projection as a post-processing step.