 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Best of Both Worlds: a Framework for Combining Degradation Prediction with High Performance Super-Resolution Networks
Nov 09, 2022



To date, the best-performing blind super-resolution (SR) techniques follow one of two paradigms: A) generate and train a standard SR network on synthetic low-resolution - high-resolution (LR - HR) pairs or B) attempt to predict the degradations an LR image has suffered and use these to inform a customised SR network. Despite significant progress, subscribers to the former miss out on useful degradation information that could be used to improve the SR process. On the other hand, followers of the latter rely on weaker SR networks, which are significantly outperformed by the latest architectural advancements. In this work, we present a framework for combining any blind SR prediction mechanism with any deep SR network, using a metadata insertion block to insert prediction vectors into SR network feature maps. Through comprehensive testing, we prove that state-of-the-art contrastive and iterative prediction schemes can be successfully combined with high-performance SR networks such as RCAN and HAN within our framework. We show that our hybrid models consistently achieve stronger SR performance than both their non-blind and blind counterparts. Furthermore, we demonstrate our framework's robustness by predicting degradations and super-resolving images from a complex pipeline of blurring, noise and compression.
Improving Super-Resolution Performance using Meta-Attention Layers
Oct 27, 2021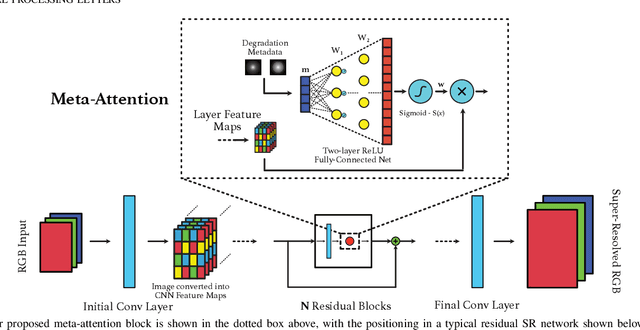
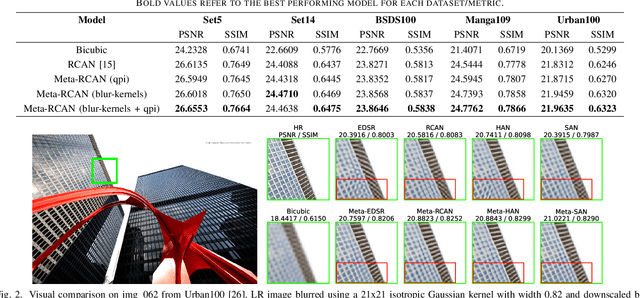
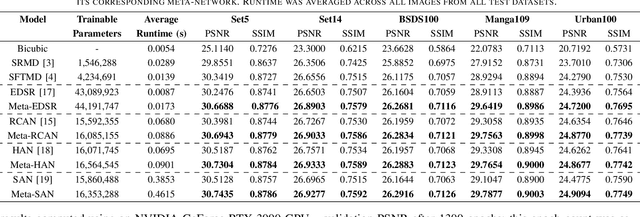
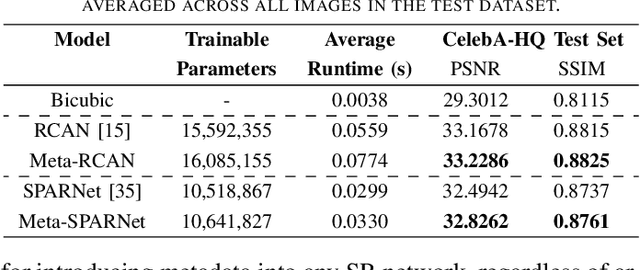
Convolutional Neural Networks (CNNs) have achieved impressive results across many super-resolution (SR) and image restoration tasks. While many such networks can upscale low-resolution (LR) images using just the raw pixel-level information, the ill-posed nature of SR can make it difficult to accurately super-resolve an image which has undergone multiple different degradations. Additional information (metadata) describing the degradation process (such as the blur kernel applied, compression level, etc.) can guide networks to super-resolve LR images with higher fidelity to the original source. Previous attempts at informing SR networks with degradation parameters have indeed been able to improve performance in a number of scenarios. However, due to the fully-convolutional nature of many SR networks, most of these metadata fusion methods either require a complete architectural change, or necessitate the addition of significant extra complexity. Thus, these approaches are difficult to introduce into arbitrary SR networks without considerable design alterations. In this paper, we introduce meta-attention, a simple mechanism which allows any SR CNN to exploit the information available in relevant degradation parameters. The mechanism functions by translating the metadata into a channel attention vector, which in turn selectively modulates the network's feature maps. Incorporating meta-attention into SR networks is straightforward, as it requires no specific type of architecture to function correctly. Extensive testing has shown that meta-attention can consistently improve the pixel-level accuracy of state-of-the-art (SOTA) networks when provided with relevant degradation metadata. For PSNR, the gain on blurred/downsampled (X4) images is of 0.2969 dB (on average) and 0.3320 dB for SOTA general and face SR models, respectively.