 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTask-driven real-world super-resolution of document scans
Jun 08, 2025Single-image super-resolution refers to the reconstruction of a high-resolution image from a single low-resolution observation. Although recent deep learning-based methods have demonstrated notable success on simulated datasets -- with low-resolution images obtained by degrading and downsampling high-resolution ones -- they frequently fail to generalize to real-world settings, such as document scans, which are affected by complex degradations and semantic variability. In this study, we introduce a task-driven, multi-task learning framework for training a super-resolution network specifically optimized for optical character recognition tasks. We propose to incorporate auxiliary loss functions derived from high-level vision tasks, including text detection using the connectionist text proposal network, text recognition via a convolutional recurrent neural network, keypoints localization using Key.Net, and hue consistency. To balance these diverse objectives, we employ dynamic weight averaging mechanism, which adaptively adjusts the relative importance of each loss term based on its convergence behavior. We validate our approach upon the SRResNet architecture, which is a well-established technique for single-image super-resolution. Experimental evaluations on both simulated and real-world scanned document datasets demonstrate that the proposed approach improves text detection, measured with intersection over union, while preserving overall image fidelity. These findings underscore the value of multi-objective optimization in super-resolution models for bridging the gap between simulated training regimes and practical deployment in real-world scenarios.
Coupling deep and handcrafted features to assess smile genuineness
Mar 20, 2025Assessing smile genuineness from video sequences is a vital topic concerned with recognizing facial expression and linking them with the underlying emotional states. There have been a number of techniques proposed underpinned with handcrafted features, as well as those that rely on deep learning to elaborate the useful features. As both of these approaches have certain benefits and limitations, in this work we propose to combine the features learned by a long short-term memory network with the features handcrafted to capture the dynamics of facial action units. The results of our experiments indicate that the proposed solution is more effective than the baseline techniques and it allows for assessing the smile genuineness from video sequences in real-time.
* Submitted to SPIE Defense + Commercial Sensing 2024
Toward task-driven satellite image super-resolution
Mar 19, 2025Super-resolution is aimed at reconstructing high-resolution images from low-resolution observations. State-of-the-art approaches underpinned with deep learning allow for obtaining outstanding results, generating images of high perceptual quality. However, it often remains unclear whether the reconstructed details are close to the actual ground-truth information and whether they constitute a more valuable source for image analysis algorithms. In the reported work, we address the latter problem, and we present our efforts toward learning super-resolution algorithms in a task-driven way to make them suitable for generating high-resolution images that can be exploited for automated image analysis. In the reported initial research, we propose a methodological approach for assessing the existing models that perform computer vision tasks in terms of whether they can be used for evaluating super-resolution reconstruction algorithms, as well as training them in a task-driven way. We support our analysis with experimental study and we expect it to establish a solid foundation for selecting appropriate computer vision tasks that will advance the capabilities of real-world super-resolution.
* Submitted to IEEE IGARSS 2024
Ensembling convolutional neural networks for human skin segmentation
Jul 27, 2024Detecting and segmenting human skin regions in digital images is an intensively explored topic of computer vision with a variety of approaches proposed over the years that have been found useful in numerous practical applications. The first methods were based on pixel-wise skin color modeling and they were later enhanced with context-based analysis to include the textural and geometrical features, recently extracted using deep convolutional neural networks. It has been also demonstrated that skin regions can be segmented from grayscale images without using color information at all. However, the possibility to combine these two sources of information has not been explored so far and we address this research gap with the contribution reported in this paper. We propose to train a convolutional network using the datasets focused on different features to create an ensemble whose individual outcomes are effectively combined using yet another convolutional network trained to produce the final segmentation map. The experimental results clearly indicate that the proposed approach outperforms the basic classifiers, as well as an ensemble based on the voting scheme. We expect that this study will help in developing new ensemble-based techniques that will improve the performance of semantic segmentation systems, reaching beyond the problem of detecting human skin.
Task-driven single-image super-resolution reconstruction of document scans
Jul 12, 2024


Super-resolution reconstruction is aimed at generating images of high spatial resolution from low-resolution observations. State-of-the-art super-resolution techniques underpinned with deep learning allow for obtaining results of outstanding visual quality, but it is seldom verified whether they constitute a valuable source for specific computer vision applications. In this paper, we investigate the possibility of employing super-resolution as a preprocessing step to improve optical character recognition from document scans. To achieve that, we propose to train deep networks for single-image super-resolution in a task-driven way to make them better adapted for the purpose of text detection. As problems limited to a specific task are heavily ill-posed, we introduce a multi-task loss function that embraces components related with text detection coupled with those guided by image similarity. The obtained results reported in this paper are encouraging and they constitute an important step towards real-world super-resolution of document images.
Squeezing nnU-Nets with Knowledge Distillation for On-Board Cloud Detection
Jun 16, 2023

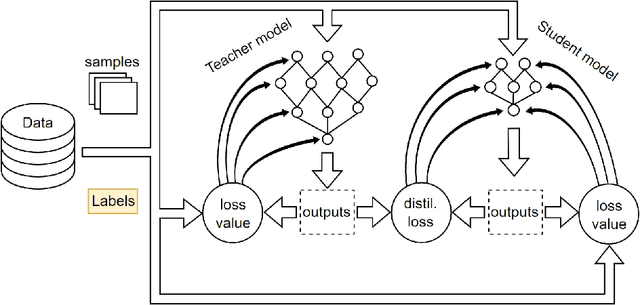

Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling. We approach this task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Unfortunately, such models are commonly memory-inefficient due to their (very) large architectures. To benefit from them in on-board processing, we compress nnU-Nets with knowledge distillation into much smaller and compact U-Nets. Our experiments, performed over Sentinel-2 and Landsat-8 images revealed that nnU-Nets deliver state-of-the-art performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 images (the winners obtained 0.897, the baseline U-Net with the ResNet-34 backbone: 0.817, and the classic Sentinel-2 image thresholding: 0.652). Finally, we showed that knowledge distillation enables to elaborate dramatically smaller (almost 280x) U-Nets when compared to nnU-Nets while still maintaining their segmentation capabilities.
Multitemporal and multispectral data fusion for super-resolution of Sentinel-2 images
Jan 26, 2023

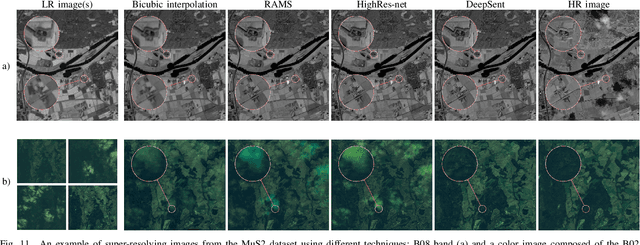

Multispectral Sentinel-2 images are a valuable source of Earth observation data, however spatial resolution of their spectral bands limited to 10 m, 20 m, and 60 m ground sampling distance remains insufficient in many cases. This problem can be addressed with super-resolution, aimed at reconstructing a high-resolution image from a low-resolution observation. For Sentinel-2, spectral information fusion allows for enhancing the 20 m and 60 m bands to the 10 m resolution. Also, there were attempts to combine multitemporal stacks of individual Sentinel-2 bands, however these two approaches have not been combined so far. In this paper, we introduce DeepSent -- a new deep network for super-resolving multitemporal series of multispectral Sentinel-2 images. It is underpinned with information fusion performed simultaneously in the spectral and temporal dimensions to generate an enlarged multispectral image. In our extensive experimental study, we demonstrate that our solution outperforms other state-of-the-art techniques that realize either multitemporal or multispectral data fusion. Furthermore, we show that the advantage of DeepSent results from how these two fusion types are combined in a single architecture, which is superior to performing such fusion in a sequential manner. Importantly, we have applied our method to super-resolve real-world Sentinel-2 images, enhancing the spatial resolution of all the spectral bands to 3.3 m nominal ground sampling distance, and we compare the outcome with very high-resolution WorldView-2 images. We will publish our implementation upon paper acceptance, and we expect it will increase the possibilities of exploiting super-resolved Sentinel-2 images in real-life applications.
Self-Configuring nnU-Nets Detect Clouds in Satellite Images
Oct 24, 2022



Cloud detection is a pivotal satellite image pre-processing step that can be performed both on the ground and on board a satellite to tag useful images. In the latter case, it can help to reduce the amount of data to downlink by pruning the cloudy areas, or to make a satellite more autonomous through data-driven acquisition re-scheduling of the cloudy areas. We approach this important task with nnU-Nets, a self-reconfigurable framework able to perform meta-learning of a segmentation network over various datasets. Our experiments, performed over Sentinel-2 and Landsat-8 multispectral images revealed that nnU-Nets deliver state-of-the-art cloud segmentation performance without any manual design. Our approach was ranked within the top 7% best solutions (across 847 participating teams) in the On Cloud N: Cloud Cover Detection Challenge, where we reached the Jaccard index of 0.882 over more than 10k unseen Sentinel-2 image patches (the winners obtained 0.897, whereas the baseline U-Net with the ResNet-34 backbone used as an encoder: 0.817, and the classic Sentinel-2 image thresholding: 0.652).
MuS2: A Benchmark for Sentinel-2 Multi-Image Super-Resolution
Oct 06, 2022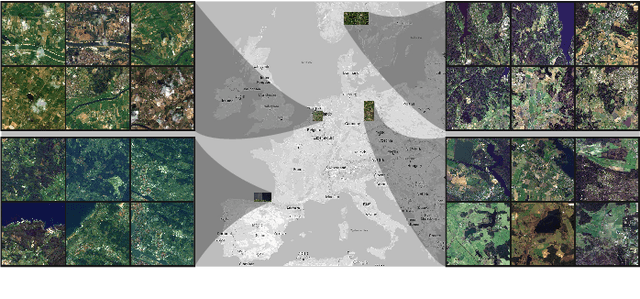
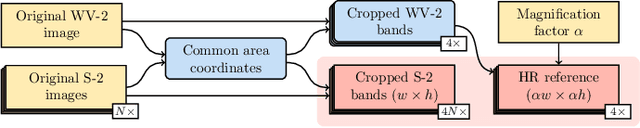


Insufficient spatial resolution of satellite imagery, including Sentinel-2 data, is a serious limitation in many practical use cases. To mitigate this problem, super-resolution reconstruction is receiving considerable attention from the remote sensing community. When it is performed from multiple images captured at subsequent revisits, it may benefit from information fusion, leading to enhanced reconstruction accuracy. One of the obstacles in multi-image super-resolution consists in the scarcity of real-life benchmark datasets -- most of the research was performed for simulated data which do not fully reflect the operating conditions. In this letter, we introduce a new MuS2 benchmark for multi-image super-resolution reconstruction of Sentinel-2 images, with WorldView-2 imagery used as the high-resolution reference. Within MuS2, we publish the first end-to-end evaluation procedure for this problem which we expect to help the researchers in advancing the state of the art in multi-image super-resolution for Sentinel-2 imagery.
A Multibranch Convolutional Neural Network for Hyperspectral Unmixing
Aug 03, 2022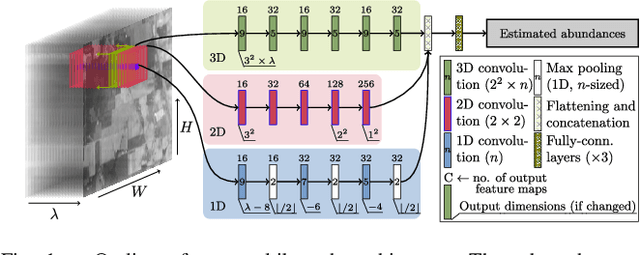
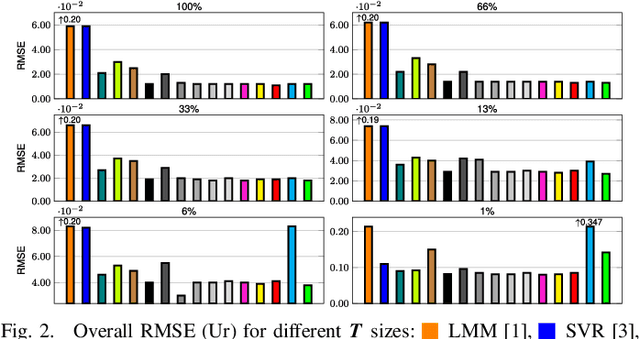
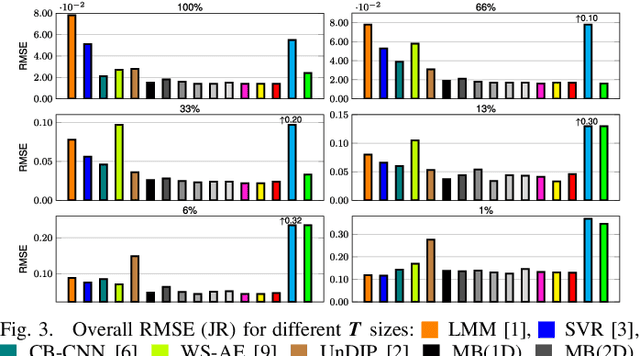
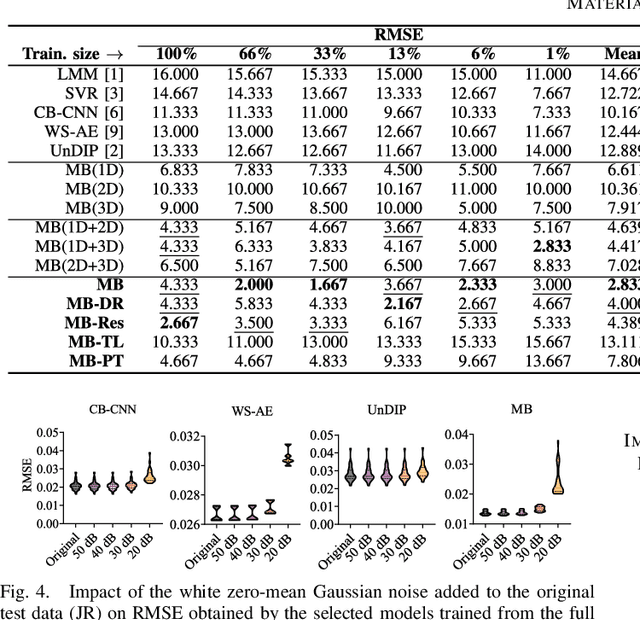
Hyperspectral unmixing remains one of the most challenging tasks in the analysis of such data. Deep learning has been blooming in the field and proved to outperform other classic unmixing techniques, and can be effectively deployed onboard Earth observation satellites equipped with hyperspectral imagers. In this letter, we follow this research pathway and propose a multi-branch convolutional neural network that benefits from fusing spectral, spatial, and spectral-spatial features in the unmixing process. The results of our experiments, backed up with the ablation study, revealed that our techniques outperform others from the literature and lead to higher-quality fractional abundance estimation. Also, we investigated the influence of reducing the training sets on the capabilities of all algorithms and their robustness against noise, as capturing large and representative ground-truth sets is time-consuming and costly in practice, especially in emerging Earth observation scenarios.
* 14 pages (including supplementary material), published in IEEE Geoscience and Remote Sensing Letters