 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward task-driven satellite image super-resolution
Mar 19, 2025Super-resolution is aimed at reconstructing high-resolution images from low-resolution observations. State-of-the-art approaches underpinned with deep learning allow for obtaining outstanding results, generating images of high perceptual quality. However, it often remains unclear whether the reconstructed details are close to the actual ground-truth information and whether they constitute a more valuable source for image analysis algorithms. In the reported work, we address the latter problem, and we present our efforts toward learning super-resolution algorithms in a task-driven way to make them suitable for generating high-resolution images that can be exploited for automated image analysis. In the reported initial research, we propose a methodological approach for assessing the existing models that perform computer vision tasks in terms of whether they can be used for evaluating super-resolution reconstruction algorithms, as well as training them in a task-driven way. We support our analysis with experimental study and we expect it to establish a solid foundation for selecting appropriate computer vision tasks that will advance the capabilities of real-world super-resolution.
* Submitted to IEEE IGARSS 2024
MuS2: A Benchmark for Sentinel-2 Multi-Image Super-Resolution
Oct 06, 2022
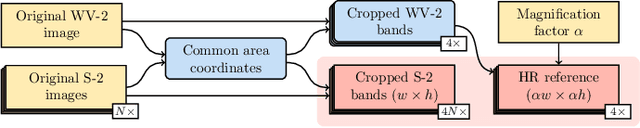


Insufficient spatial resolution of satellite imagery, including Sentinel-2 data, is a serious limitation in many practical use cases. To mitigate this problem, super-resolution reconstruction is receiving considerable attention from the remote sensing community. When it is performed from multiple images captured at subsequent revisits, it may benefit from information fusion, leading to enhanced reconstruction accuracy. One of the obstacles in multi-image super-resolution consists in the scarcity of real-life benchmark datasets -- most of the research was performed for simulated data which do not fully reflect the operating conditions. In this letter, we introduce a new MuS2 benchmark for multi-image super-resolution reconstruction of Sentinel-2 images, with WorldView-2 imagery used as the high-resolution reference. Within MuS2, we publish the first end-to-end evaluation procedure for this problem which we expect to help the researchers in advancing the state of the art in multi-image super-resolution for Sentinel-2 imagery.
On training deep networks for satellite image super-resolution
Jun 16, 2019


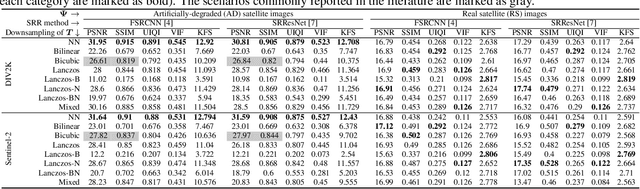
The capabilities of super-resolution reconstruction (SRR)---techniques for enhancing image spatial resolution---have been recently improved significantly by the use of deep convolutional neural networks. Commonly, such networks are learned using huge training sets composed of original images alongside their low-resolution counterparts, obtained with bicubic downsampling. In this paper, we investigate how the SRR performance is influenced by the way such low-resolution training data are obtained, which has not been explored up to date. Our extensive experimental study indicates that the training data characteristics have a large impact on the reconstruction accuracy, and the widely-adopted approach is not the most effective for dealing with satellite images. Overall, we argue that developing better training data preparation routines may be pivotal in making SRR suitable for real-world applications.
Deep Learning for Multiple-Image Super-Resolution
Mar 01, 2019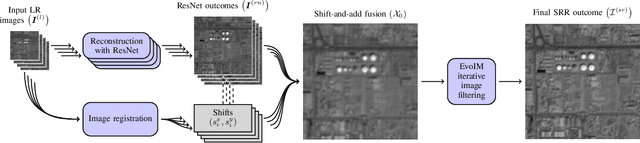



Super-resolution reconstruction (SRR) is a process aimed at enhancing spatial resolution of images, either from a single observation, based on the learned relation between low and high resolution, or from multiple images presenting the same scene. SRR is particularly valuable, if it is infeasible to acquire images at desired resolution, but many images of the same scene are available at lower resolution---this is inherent to a variety of remote sensing scenarios. Recently, we have witnessed substantial improvement in single-image SRR attributed to the use of deep neural networks for learning the relation between low and high resolution. Importantly, deep learning has not been exploited for multiple-image SRR, which benefits from information fusion and in general allows for achieving higher reconstruction accuracy. In this letter, we introduce a new method which combines the advantages of multiple-image fusion with learning the low-to-high resolution mapping using deep networks. The reported experimental results indicate that our algorithm outperforms the state-of-the-art SRR methods, including these that operate from a single image, as well as those that perform multiple-image fusion.