 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMuS2: A Benchmark for Sentinel-2 Multi-Image Super-Resolution
Oct 06, 2022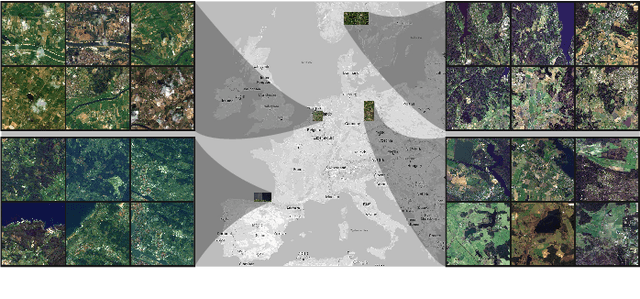
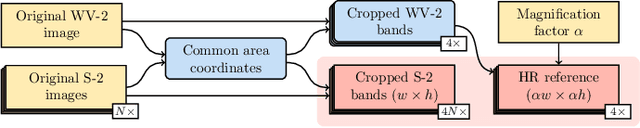


Insufficient spatial resolution of satellite imagery, including Sentinel-2 data, is a serious limitation in many practical use cases. To mitigate this problem, super-resolution reconstruction is receiving considerable attention from the remote sensing community. When it is performed from multiple images captured at subsequent revisits, it may benefit from information fusion, leading to enhanced reconstruction accuracy. One of the obstacles in multi-image super-resolution consists in the scarcity of real-life benchmark datasets -- most of the research was performed for simulated data which do not fully reflect the operating conditions. In this letter, we introduce a new MuS2 benchmark for multi-image super-resolution reconstruction of Sentinel-2 images, with WorldView-2 imagery used as the high-resolution reference. Within MuS2, we publish the first end-to-end evaluation procedure for this problem which we expect to help the researchers in advancing the state of the art in multi-image super-resolution for Sentinel-2 imagery.
Extrinsic camera calibration method and its performance evaluation
Sep 28, 2018

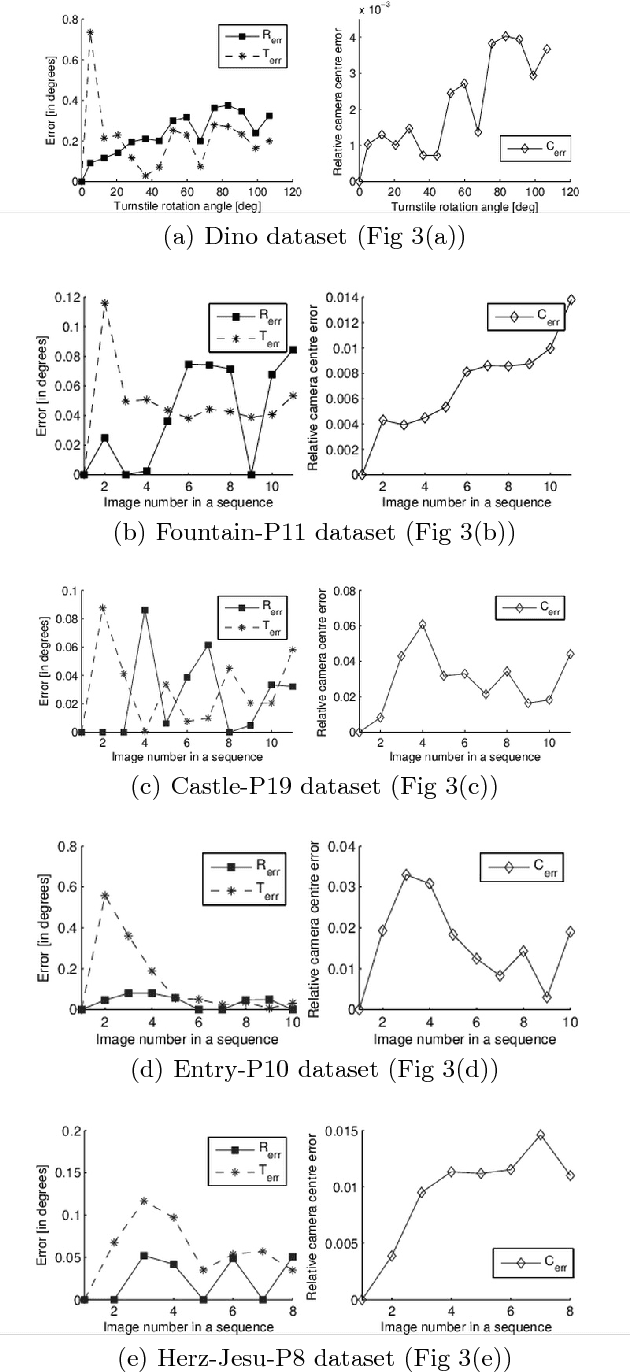
This paper presents a method for extrinsic camera calibration (estimation of camera rotation and translation matrices) from a sequence of images. It is assumed camera intrinsic matrix and distortion coefficients are known and fixed during the entire sequence. %This allows to decrease a number of pairs of corresponding keypoints between images needed to estimate epipolar geometry compared to uncalibrated case. Performance of the presented method is evaluated on a number of multi-view stereo test datasets. Presented algorithm can be used as a first stage in a dense stereo reconstruction system.
Face Recognition Based on Sequence of Images
Sep 28, 2018


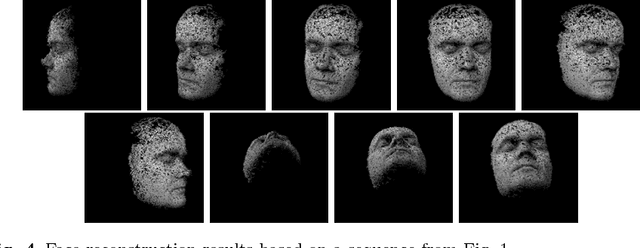
This paper presents a face recognition method based on a sequence of images. Face shape is reconstructed from images using a combination of structure-from-motion and multi-view stereo methods. The reconstructed 3D face model is compared against models held in a gallery. The novel element in the presented approach is the fact, that the reconstruction is based only on input images and doesn't require a generic, deformable face model. Experimental verification of the proposed method is also included.
Camera Pose Estimation from Sequence of Calibrated Images
Sep 28, 2018

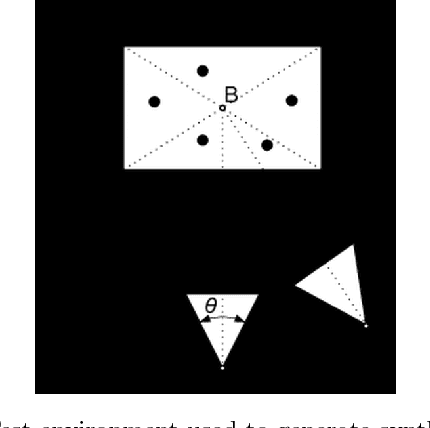
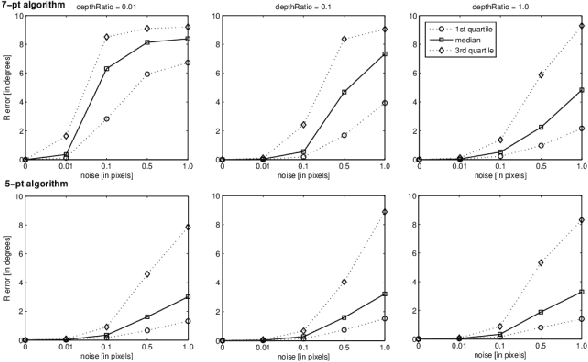
In this paper a method for camera pose estimation from a sequence of images is presented. The method assumes camera is calibrated (intrinsic parameters are known) which allows to decrease a number of required pairs of corresponding points compared to uncalibrated case. Our algorithm can be used as a first stage in a structure from motion stereo reconstruction system.
Recurrent Neural Networks for Online Video Popularity Prediction
Jul 21, 2017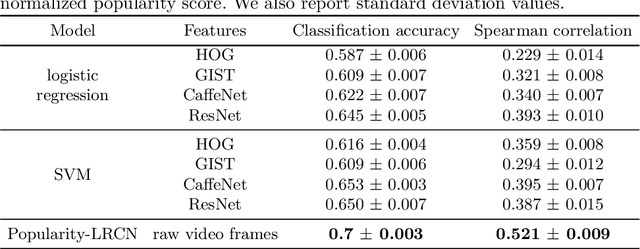

In this paper, we address the problem of popularity prediction of online videos shared in social media. We prove that this challenging task can be approached using recently proposed deep neural network architectures. We cast the popularity prediction problem as a classification task and we aim to solve it using only visual cues extracted from videos. To that end, we propose a new method based on a Long-term Recurrent Convolutional Network (LRCN) that incorporates the sequentiality of the information in the model. Results obtained on a dataset of over 37'000 videos published on Facebook show that using our method leads to over 30% improvement in prediction performance over the traditional shallow approaches and can provide valuable insights for content creators.
Shallow reading with Deep Learning: Predicting popularity of online content using only its title
Jul 21, 2017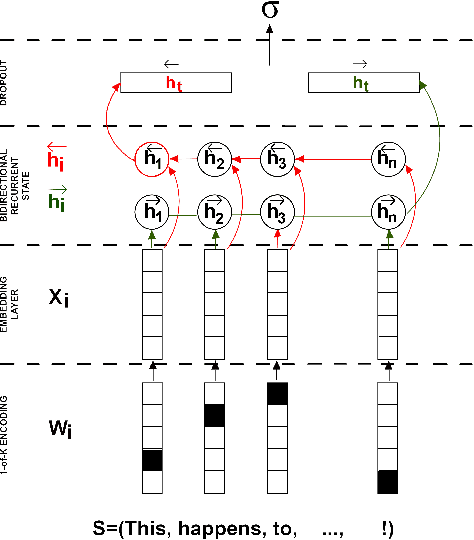
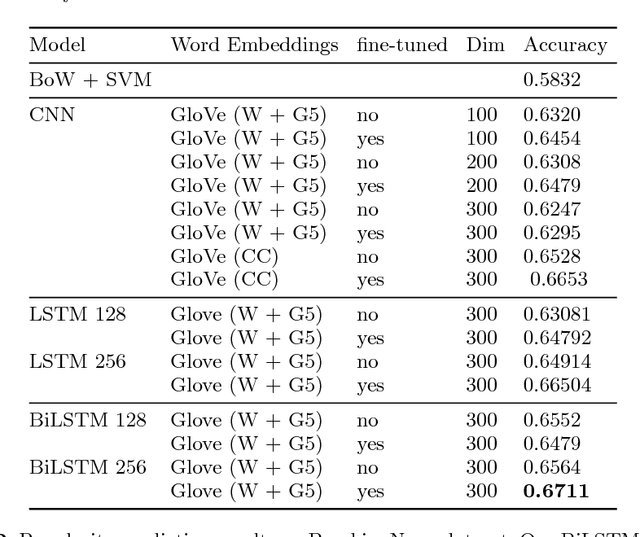
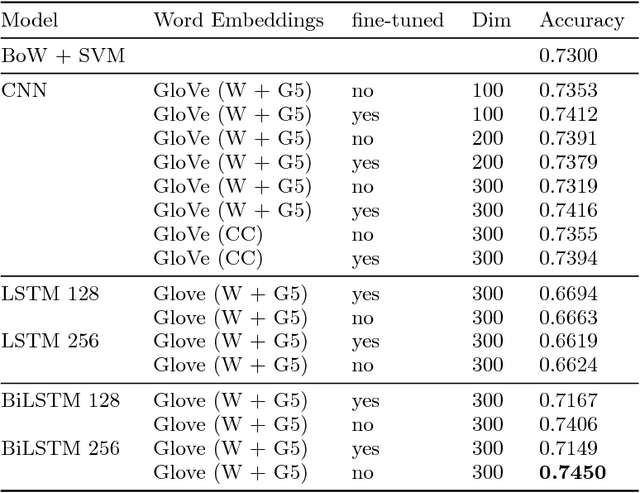

With the ever decreasing attention span of contemporary Internet users, the title of online content (such as a news article or video) can be a major factor in determining its popularity. To take advantage of this phenomenon, we propose a new method based on a bidirectional Long Short-Term Memory (LSTM) neural network designed to predict the popularity of online content using only its title. We evaluate the proposed architecture on two distinct datasets of news articles and news videos distributed in social media that contain over 40,000 samples in total. On those datasets, our approach improves the performance over traditional shallow approaches by a margin of 15%. Additionally, we show that using pre-trained word vectors in the embedding layer improves the results of LSTM models, especially when the training set is small. To our knowledge, this is the first attempt of applying popularity prediction using only textual information from the title.
Predicting popularity of online videos using Support Vector Regression
May 12, 2017

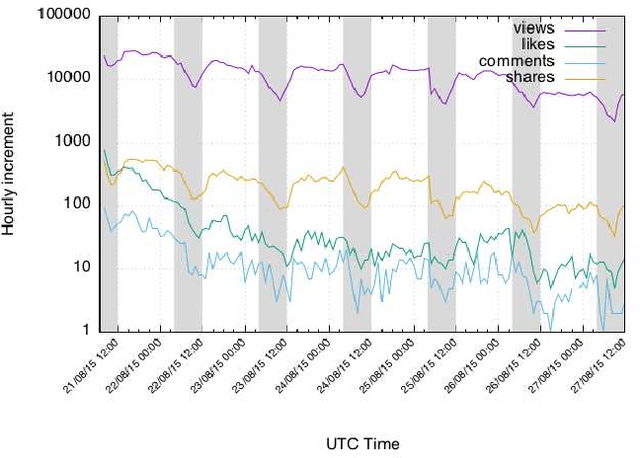
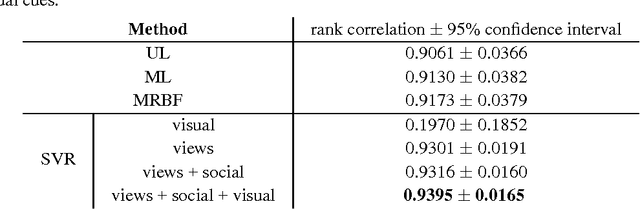
In this work, we propose a regression method to predict the popularity of an online video based on temporal and visual cues. Our method uses Support Vector Regression with Gaussian Radial Basis Functions. We show that modelling popularity patterns with this approach provides higher and more stable prediction results, mainly thanks to the non-linearity character of the proposed method as well as its resistance against overfitting. We compare our method with the state of the art on datasets containing over 14,000 videos from YouTube and Facebook. Furthermore, we show that results obtained relying only on the early distribution patterns, can be improved by adding social and visual metadata.