 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHybrid Approach to Automation, RPA and Machine Learning: a Method for the Human-centered Design of Software Robots
Nov 06, 2018One of the more prominent trends within Industry 4.0 is the drive to employ Robotic Process Automation (RPA), especially as one of the elements of the Lean approach. The full implementation of RPA is riddled with challenges relating both to the reality of everyday business operations, from SMEs to SSCs and beyond, and the social effects of the changing job market. To successfully address these points there is a need to develop a solution that would adjust to the existing business operations and at the same time lower the negative social impact of the automation process. To achieve these goals we propose a hybrid, human-centered approach to the development of software robots. This design and implementation method combines the Living Lab approach with empowerment through participatory design to kick-start the co-development and co-maintenance of hybrid software robots which, supported by variety of AI methods and tools, including interactive and collaborative ML in the cloud, transform menial job posts into higher-skilled positions, allowing former employees to stay on as robot co-designers and maintainers, i.e. as co-programmers who supervise the machine learning processes with the use of tailored high-level RPA Domain Specific Languages (DSLs) to adjust the functioning of the robots and maintain operational flexibility.
Impact of ultrasound image reconstruction method on breast lesion classification with neural transfer learning
Apr 06, 2018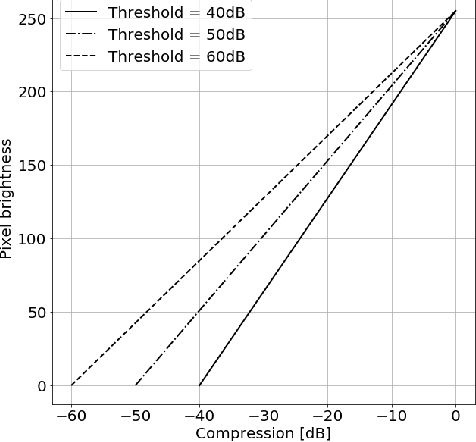

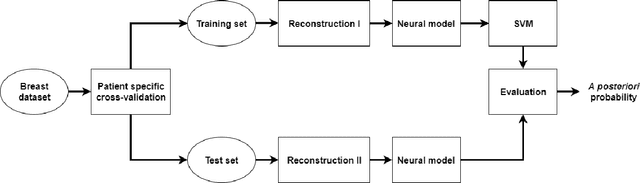
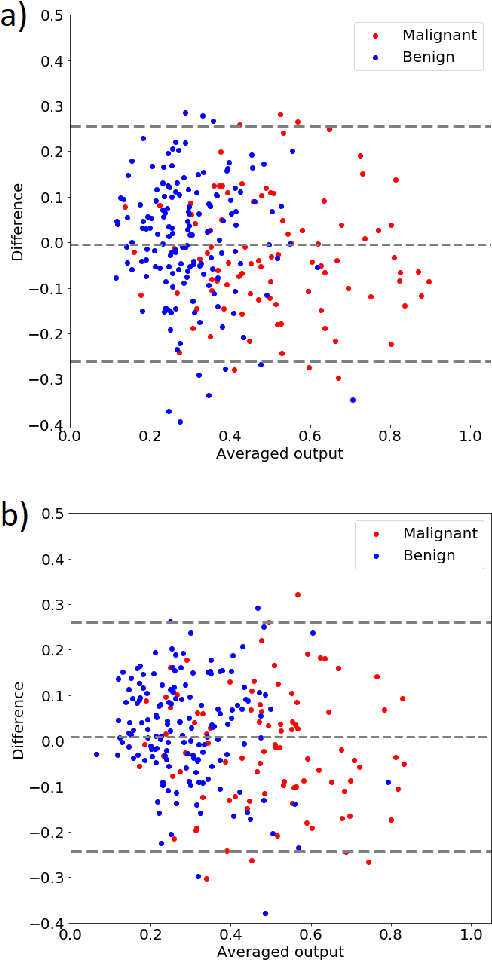
Deep learning algorithms, especially convolutional neural networks, have become a methodology of choice in medical image analysis. However, recent studies in computer vision show that even a small modification of input image intensities may cause a deep learning model to classify the image differently. In medical imaging, the distribution of image intensities is related to applied image reconstruction algorithm. In this paper we investigate the impact of ultrasound image reconstruction method on breast lesion classification with neural transfer learning. Due to high dynamic range raw ultrasonic signals are commonly compressed in order to reconstruct B-mode images. Based on raw data acquired from breast lesions, we reconstruct B-mode images using different compression levels. Next, transfer learning is applied for classification. Differently reconstructed images are employed for training and evaluation. We show that the modification of the reconstruction algorithm leads to decrease of classification performance. As a remedy, we propose a method of data augmentation. We show that the augmentation of the training set with differently reconstructed B-mode images leads to a more robust and efficient classification. Our study suggests that it is important to take into account image reconstruction algorithms implemented in medical scanners during development of computer aided diagnosis systems.
What Looks Good with my Sofa: Multimodal Search Engine for Interior Design
Jan 08, 2018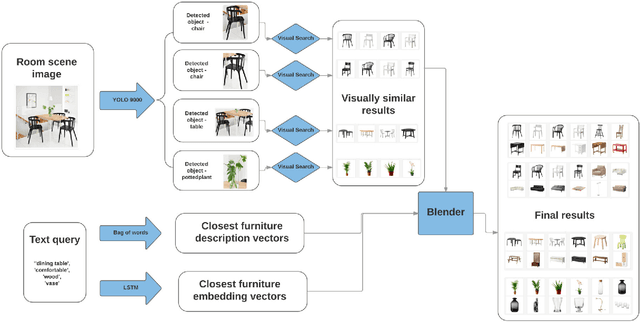
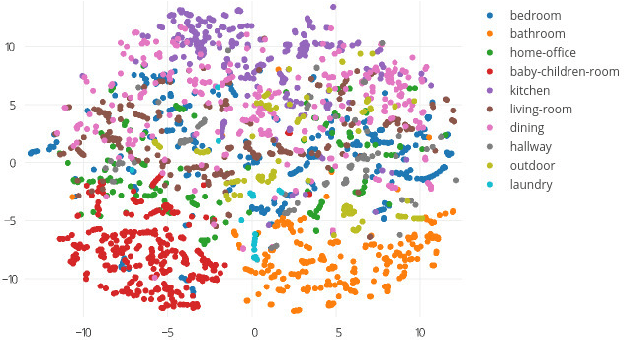

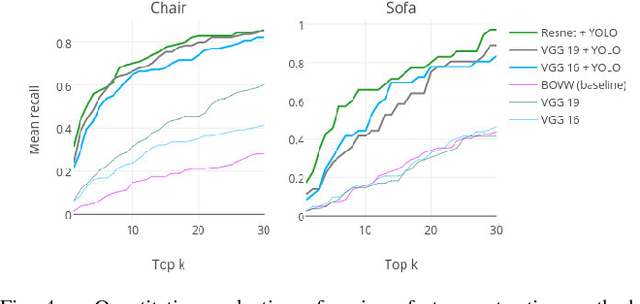
In this paper, we propose a multi-modal search engine for interior design that combines visual and textual queries. The goal of our engine is to retrieve interior objects, e.g. furniture or wall clocks, that share visual and aesthetic similarities with the query. Our search engine allows the user to take a photo of a room and retrieve with a high recall a list of items identical or visually similar to those present in the photo. Additionally, it allows to return other items that aesthetically and stylistically fit well together. To achieve this goal, our system blends the results obtained using textual and visual modalities. Thanks to this blending strategy, we increase the average style similarity score of the retrieved items by 11%. Our work is implemented as a Web-based application and it is planned to be opened to the public.
* FEDCSIS 5th Conference on Multimedia, Interaction, Design and Innovation (MIDI), 2017
DeepStyle: Multimodal Search Engine for Fashion and Interior Design
Jan 08, 2018
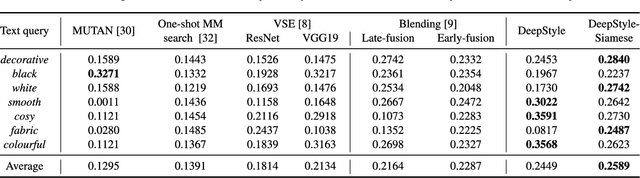
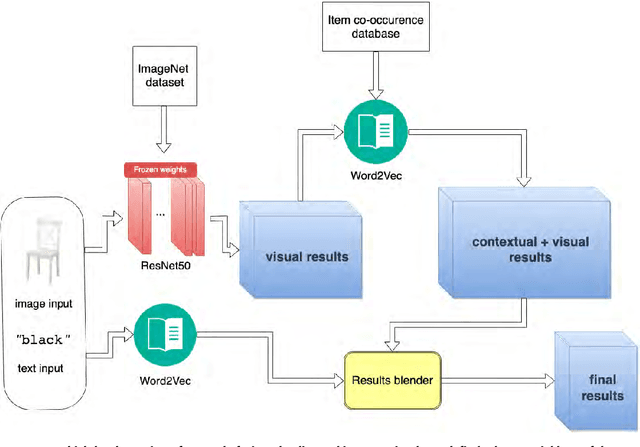
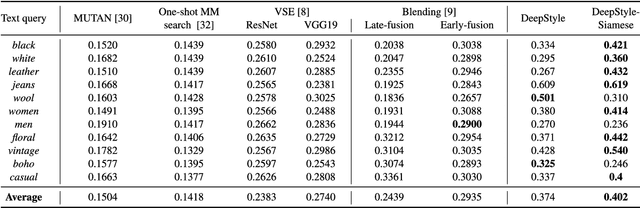
In this paper, we propose a multimodal search engine that combines visual and textual cues to retrieve items from a multimedia database aesthetically similar to the query. The goal of our engine is to enable intuitive retrieval of fashion merchandise such as clothes or furniture. Existing search engines treat textual input only as an additional source of information about the query image and do not correspond to the real-life scenario where the user looks for 'the same shirt but of denim'. Our novel method, dubbed DeepStyle, mitigates those shortcomings by using a joint neural network architecture to model contextual dependencies between features of different modalities. We prove the robustness of this approach on two different challenging datasets of fashion items and furniture where our DeepStyle engine outperforms baseline methods by 18-21% on the tested datasets. Our search engine is commercially deployed and available through a Web-based application.
Shallow reading with Deep Learning: Predicting popularity of online content using only its title
Jul 21, 2017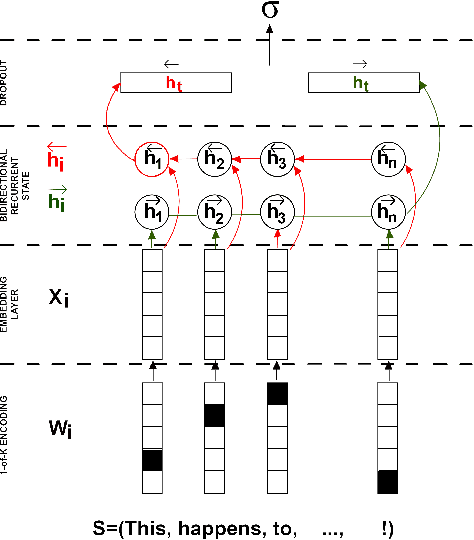
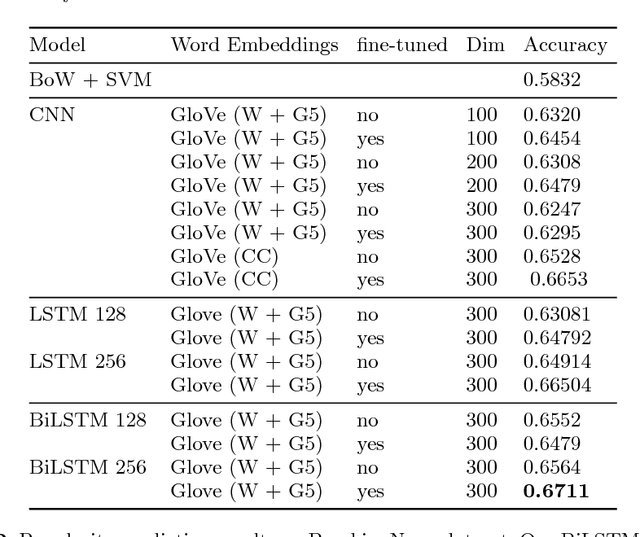
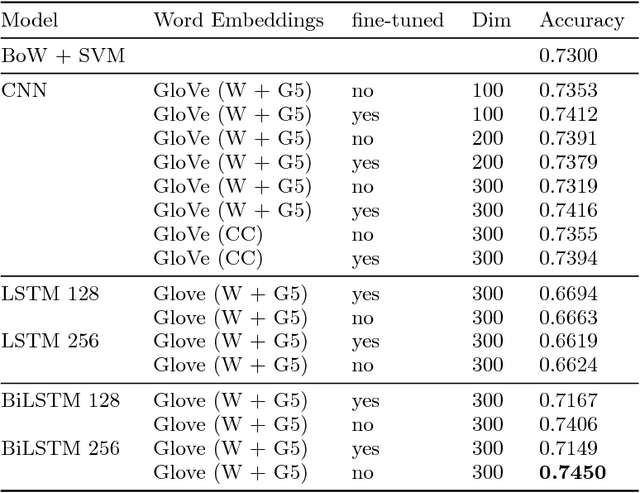

With the ever decreasing attention span of contemporary Internet users, the title of online content (such as a news article or video) can be a major factor in determining its popularity. To take advantage of this phenomenon, we propose a new method based on a bidirectional Long Short-Term Memory (LSTM) neural network designed to predict the popularity of online content using only its title. We evaluate the proposed architecture on two distinct datasets of news articles and news videos distributed in social media that contain over 40,000 samples in total. On those datasets, our approach improves the performance over traditional shallow approaches by a margin of 15%. Additionally, we show that using pre-trained word vectors in the embedding layer improves the results of LSTM models, especially when the training set is small. To our knowledge, this is the first attempt of applying popularity prediction using only textual information from the title.
Polish Read Speech Corpus for Speech Tools and Services
Jun 01, 2017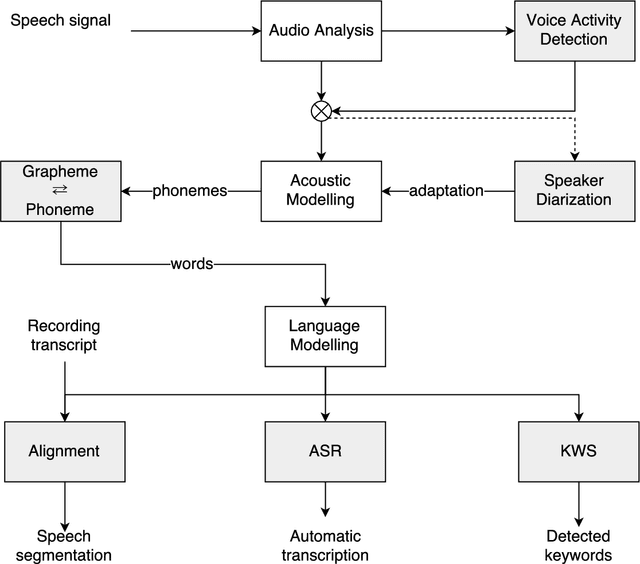


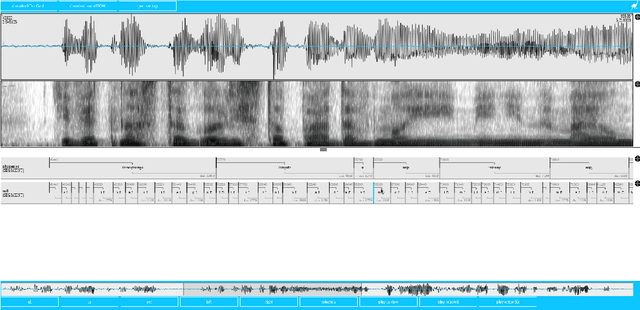
This paper describes the speech processing activities conducted at the Polish consortium of the CLARIN project. The purpose of this segment of the project was to develop specific tools that would allow for automatic and semi-automatic processing of large quantities of acoustic speech data. The tools include the following: grapheme-to-phoneme conversion, speech-to-text alignment, voice activity detection, speaker diarization, keyword spotting and automatic speech transcription. Furthermore, in order to develop these tools, a large high-quality studio speech corpus was recorded and released under an open license, to encourage development in the area of Polish speech research. Another purpose of the corpus was to serve as a reference for studies in phonetics and pronunciation. All the tools and resources were released on the the Polish CLARIN website. This paper discusses the current status and future plans for the project.
Multi-domain machine translation enhancements by parallel data extraction from comparable corpora
Mar 22, 2016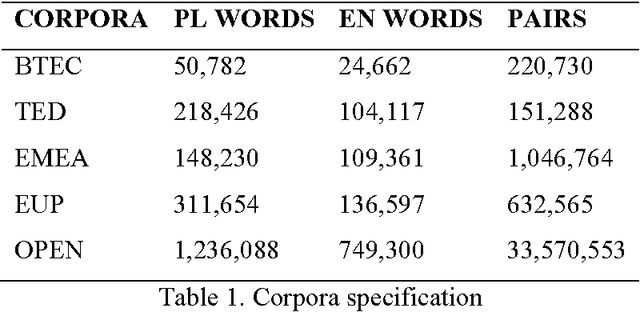

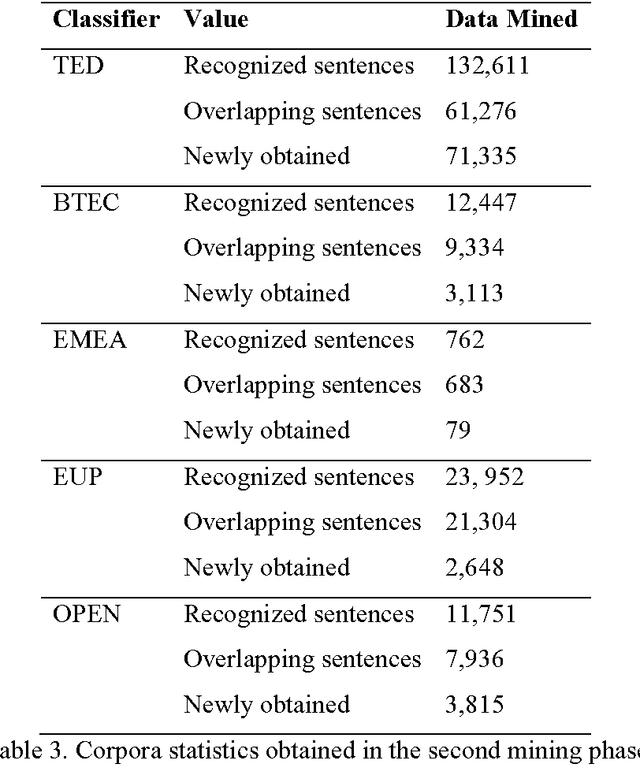
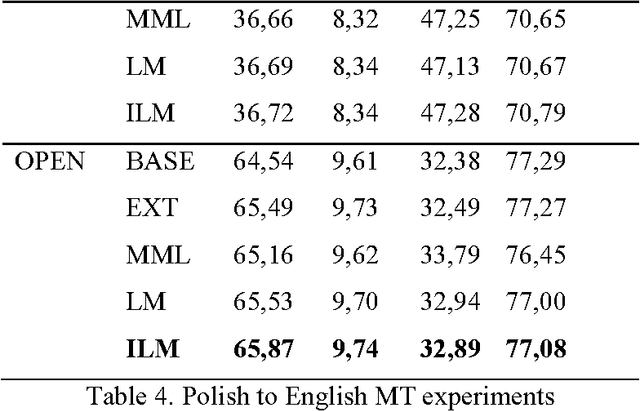
Parallel texts are a relatively rare language resource, however, they constitute a very useful research material with a wide range of applications. This study presents and analyses new methodologies we developed for obtaining such data from previously built comparable corpora. The methodologies are automatic and unsupervised which makes them good for large scale research. The task is highly practical as non-parallel multilingual data occur much more frequently than parallel corpora and accessing them is easy, although parallel sentences are a considerably more useful resource. In this study, we propose a method of automatic web crawling in order to build topic-aligned comparable corpora, e.g. based on the Wikipedia or Euronews.com. We also developed new methods of obtaining parallel sentences from comparable data and proposed methods of filtration of corpora capable of selecting inconsistent or only partially equivalent translations. Our methods are easily scalable to other languages. Evaluation of the quality of the created corpora was performed by analysing the impact of their use on statistical machine translation systems. Experiments were presented on the basis of the Polish-English language pair for texts from different domains, i.e. lectures, phrasebooks, film dialogues, European Parliament proceedings and texts contained medicines leaflets. We also tested a second method of creating parallel corpora based on data from comparable corpora which allows for automatically expanding the existing corpus of sentences about a given domain on the basis of analogies found between them. It does not require, therefore, having past parallel resources in order to train a classifier.
Unsupervised comparable corpora preparation and exploration for bi-lingual translation equivalents
Dec 05, 2015
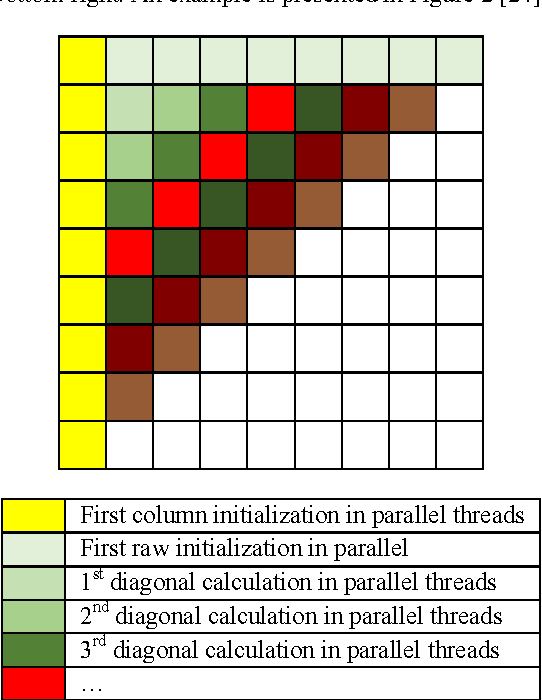
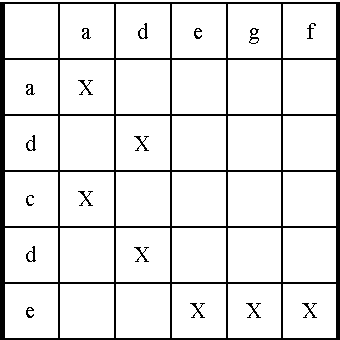

The multilingual nature of the world makes translation a crucial requirement today. Parallel dictionaries constructed by humans are a widely-available resource, but they are limited and do not provide enough coverage for good quality translation purposes, due to out-of-vocabulary words and neologisms. This motivates the use of statistical translation systems, which are unfortunately dependent on the quantity and quality of training data. Such systems have a very limited availability especially for some languages and very narrow text domains. In this research we present our improvements to current comparable corpora mining methodologies by re- implementation of the comparison algorithms (using Needleman-Wunch algorithm), introduction of a tuning script and computation time improvement by GPU acceleration. Experiments are carried out on bilingual data extracted from the Wikipedia, on various domains. For the Wikipedia itself, additional cross-lingual comparison heuristics were introduced. The modifications made a positive impact on the quality and quantity of mined data and on the translation quality.
* arXiv admin note: text overlap with arXiv:1509.08639
PJAIT Systems for the IWSLT 2015 Evaluation Campaign Enhanced by Comparable Corpora
Dec 05, 2015
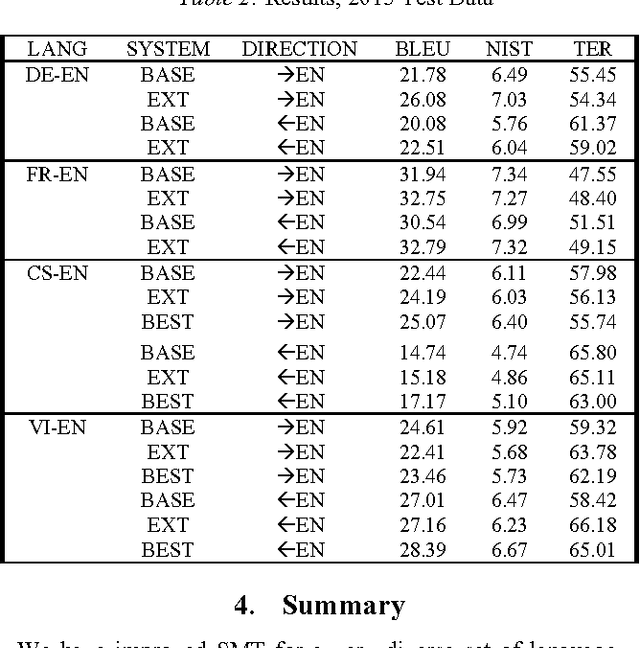

In this paper, we attempt to improve Statistical Machine Translation (SMT) systems on a very diverse set of language pairs (in both directions): Czech - English, Vietnamese - English, French - English and German - English. To accomplish this, we performed translation model training, created adaptations of training settings for each language pair, and obtained comparable corpora for our SMT systems. Innovative tools and data adaptation techniques were employed. The TED parallel text corpora for the IWSLT 2015 evaluation campaign were used to train language models, and to develop, tune, and test the system. In addition, we prepared Wikipedia-based comparable corpora for use with our SMT system. This data was specified as permissible for the IWSLT 2015 evaluation. We explored the use of domain adaptation techniques, symmetrized word alignment models, the unsupervised transliteration models and the KenLM language modeling tool. To evaluate the effects of different preparations on translation results, we conducted experiments and used the BLEU, NIST and TER metrics. Our results indicate that our approach produced a positive impact on SMT quality.
Spoken Language Translation for Polish
Nov 24, 2015Spoken language translation (SLT) is becoming more important in the increasingly globalized world, both from a social and economic point of view. It is one of the major challenges for automatic speech recognition (ASR) and machine translation (MT), driving intense research activities in these areas. While past research in SLT, due to technology limitations, dealt mostly with speech recorded under controlled conditions, today's major challenge is the translation of spoken language as it can be found in real life. Considered application scenarios range from portable translators for tourists, lectures and presentations translation, to broadcast news and shows with live captioning. We would like to present PJIIT's experiences in the SLT gained from the Eu-Bridge 7th framework project and the U-Star consortium activities for the Polish/English language pair. Presented research concentrates on ASR adaptation for Polish (state-of-the-art acoustic models: DBN-BLSTM training, Kaldi: LDA+MLLT+SAT+MMI), language modeling for ASR & MT (text normalization, RNN-based LMs, n-gram model domain interpolation) and statistical translation techniques (hierarchical models, factored translation models, automatic casing and punctuation, comparable and bilingual corpora preparation). While results for the well-defined domains (phrases for travelers, parliament speeches, medical documentation, movie subtitling) are very encouraging, less defined domains (presentation, lectures) still form a challenge. Our progress in the IWSLT TED task (MT only) will be presented, as well as current progress in the Polish ASR.