 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePolish Read Speech Corpus for Speech Tools and Services
Jun 01, 2017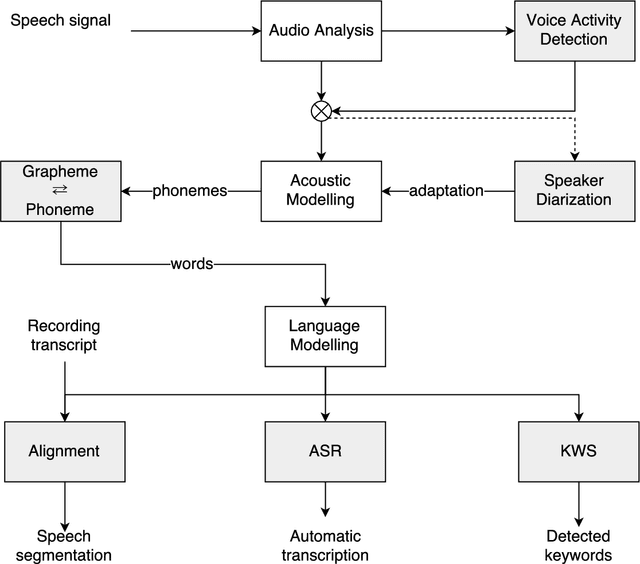


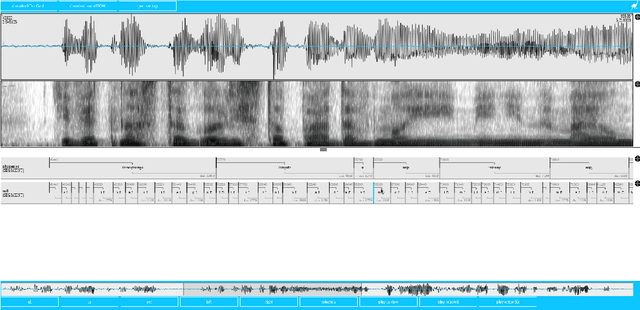
This paper describes the speech processing activities conducted at the Polish consortium of the CLARIN project. The purpose of this segment of the project was to develop specific tools that would allow for automatic and semi-automatic processing of large quantities of acoustic speech data. The tools include the following: grapheme-to-phoneme conversion, speech-to-text alignment, voice activity detection, speaker diarization, keyword spotting and automatic speech transcription. Furthermore, in order to develop these tools, a large high-quality studio speech corpus was recorded and released under an open license, to encourage development in the area of Polish speech research. Another purpose of the corpus was to serve as a reference for studies in phonetics and pronunciation. All the tools and resources were released on the the Polish CLARIN website. This paper discusses the current status and future plans for the project.
Comparison and Adaptation of Automatic Evaluation Metrics for Quality Assessment of Re-Speaking
Jan 12, 2016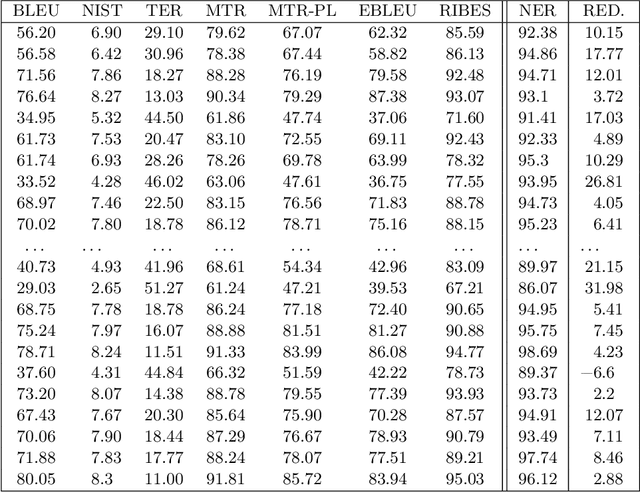
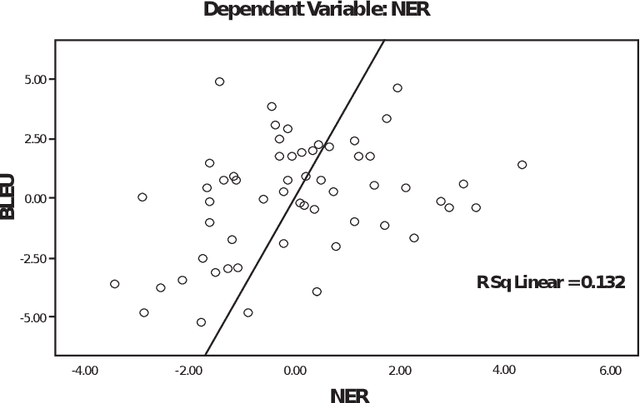
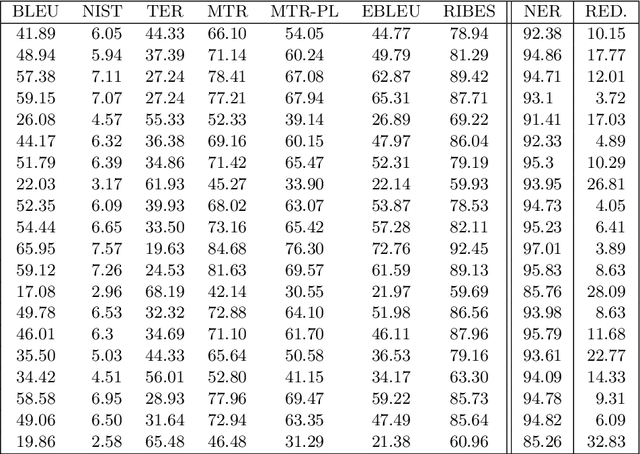
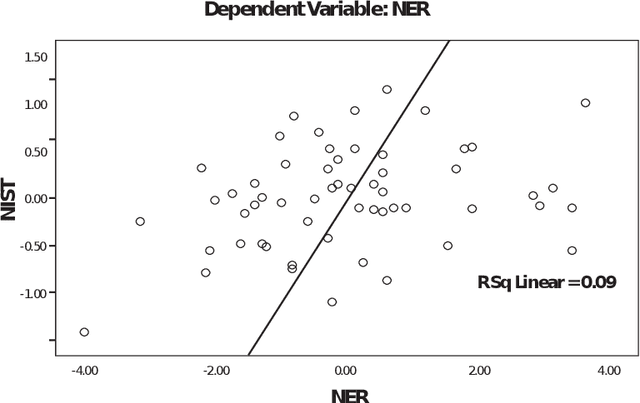
Re-speaking is a mechanism for obtaining high quality subtitles for use in live broadcast and other public events. Because it relies on humans performing the actual re-speaking, the task of estimating the quality of the results is non-trivial. Most organisations rely on humans to perform the actual quality assessment, but purely automatic methods have been developed for other similar problems, like Machine Translation. This paper will try to compare several of these methods: BLEU, EBLEU, NIST, METEOR, METEOR-PL, TER and RIBES. These will then be matched to the human-derived NER metric, commonly used in re-speaking.