Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeComparison and Adaptation of Automatic Evaluation Metrics for Quality Assessment of Re-Speaking
Paper and Code
Jan 12, 2016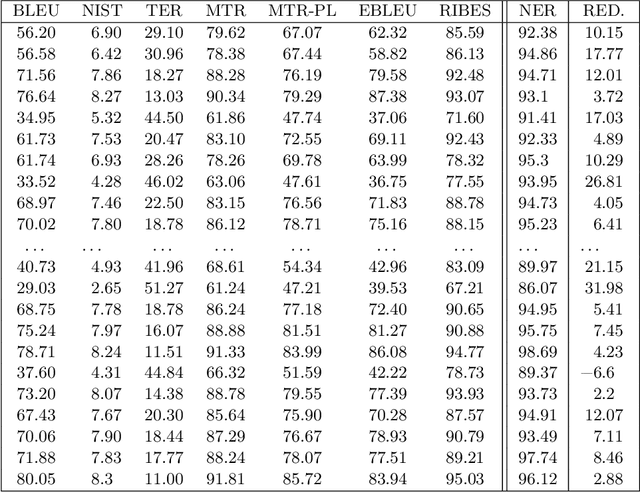
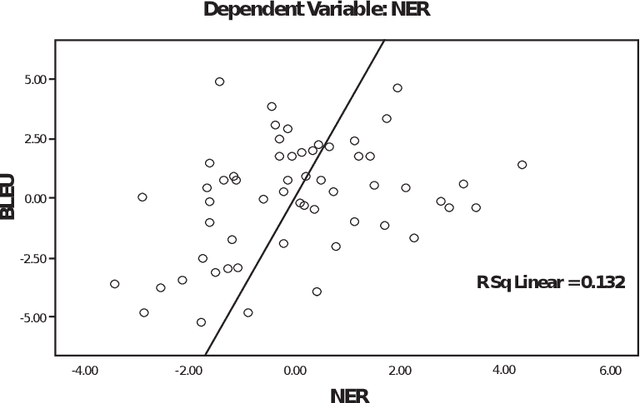
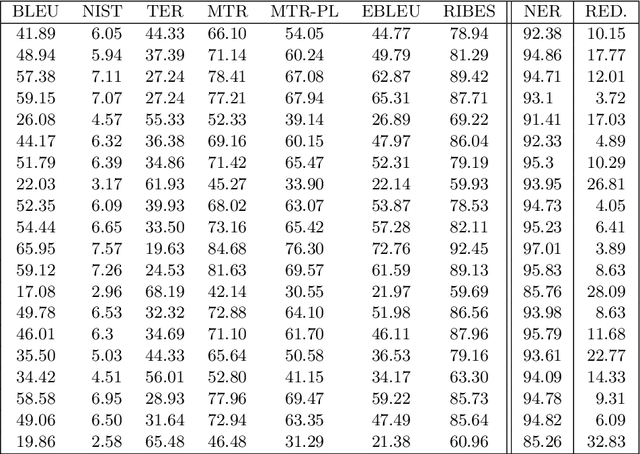
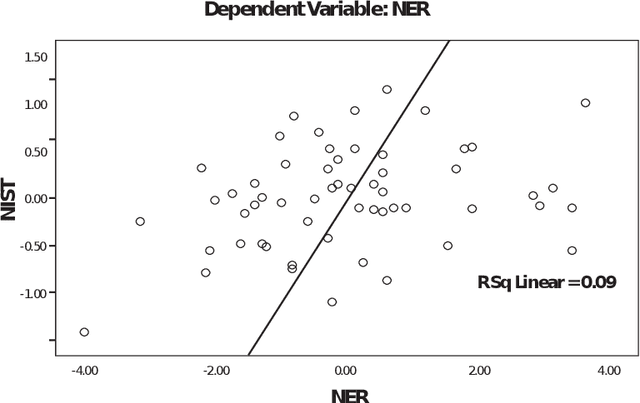
Re-speaking is a mechanism for obtaining high quality subtitles for use in live broadcast and other public events. Because it relies on humans performing the actual re-speaking, the task of estimating the quality of the results is non-trivial. Most organisations rely on humans to perform the actual quality assessment, but purely automatic methods have been developed for other similar problems, like Machine Translation. This paper will try to compare several of these methods: BLEU, EBLEU, NIST, METEOR, METEOR-PL, TER and RIBES. These will then be matched to the human-derived NER metric, commonly used in re-speaking.
* Comparison and Adaptation of Automatic Evaluation Metrics for Quality
Assessment of Re-Speaking. arXiv admin note: text overlap with
arXiv:1509.09088
View paper on