 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Looks Good with my Sofa: Multimodal Search Engine for Interior Design
Jan 08, 2018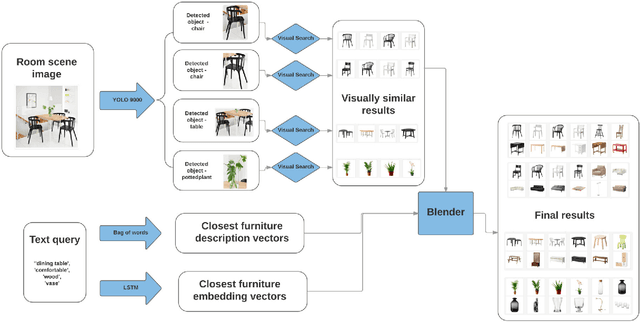
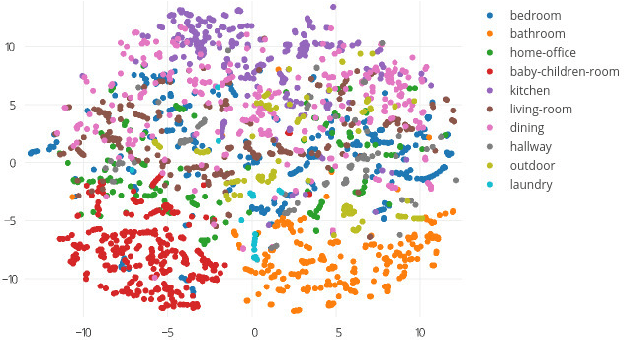

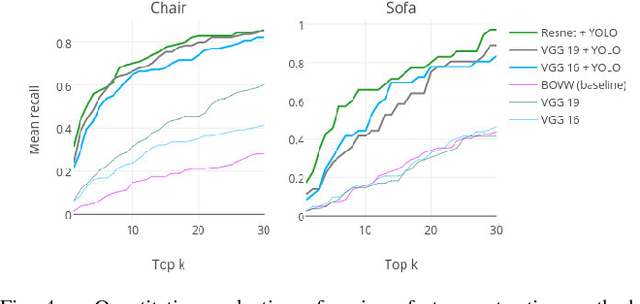
In this paper, we propose a multi-modal search engine for interior design that combines visual and textual queries. The goal of our engine is to retrieve interior objects, e.g. furniture or wall clocks, that share visual and aesthetic similarities with the query. Our search engine allows the user to take a photo of a room and retrieve with a high recall a list of items identical or visually similar to those present in the photo. Additionally, it allows to return other items that aesthetically and stylistically fit well together. To achieve this goal, our system blends the results obtained using textual and visual modalities. Thanks to this blending strategy, we increase the average style similarity score of the retrieved items by 11%. Our work is implemented as a Web-based application and it is planned to be opened to the public.
* FEDCSIS 5th Conference on Multimedia, Interaction, Design and Innovation (MIDI), 2017
Polish Read Speech Corpus for Speech Tools and Services
Jun 01, 2017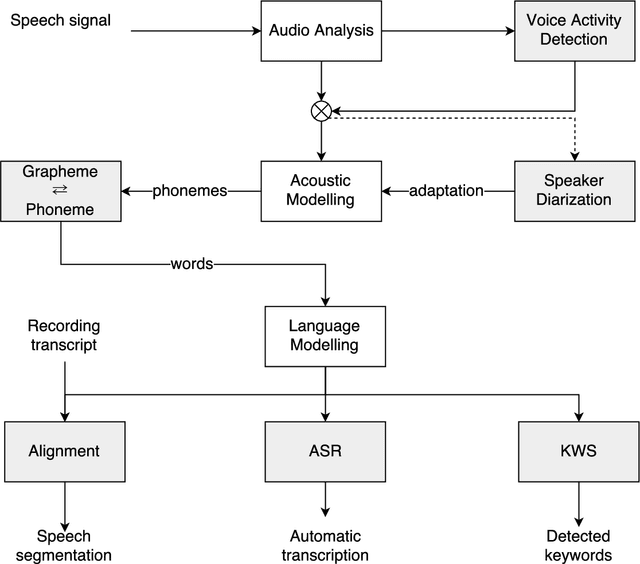


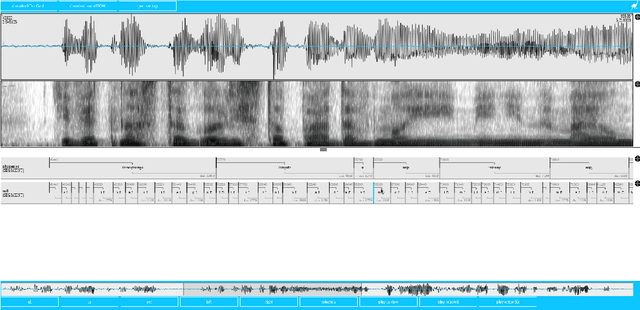
This paper describes the speech processing activities conducted at the Polish consortium of the CLARIN project. The purpose of this segment of the project was to develop specific tools that would allow for automatic and semi-automatic processing of large quantities of acoustic speech data. The tools include the following: grapheme-to-phoneme conversion, speech-to-text alignment, voice activity detection, speaker diarization, keyword spotting and automatic speech transcription. Furthermore, in order to develop these tools, a large high-quality studio speech corpus was recorded and released under an open license, to encourage development in the area of Polish speech research. Another purpose of the corpus was to serve as a reference for studies in phonetics and pronunciation. All the tools and resources were released on the the Polish CLARIN website. This paper discusses the current status and future plans for the project.
Spoken Language Translation for Polish
Nov 24, 2015Spoken language translation (SLT) is becoming more important in the increasingly globalized world, both from a social and economic point of view. It is one of the major challenges for automatic speech recognition (ASR) and machine translation (MT), driving intense research activities in these areas. While past research in SLT, due to technology limitations, dealt mostly with speech recorded under controlled conditions, today's major challenge is the translation of spoken language as it can be found in real life. Considered application scenarios range from portable translators for tourists, lectures and presentations translation, to broadcast news and shows with live captioning. We would like to present PJIIT's experiences in the SLT gained from the Eu-Bridge 7th framework project and the U-Star consortium activities for the Polish/English language pair. Presented research concentrates on ASR adaptation for Polish (state-of-the-art acoustic models: DBN-BLSTM training, Kaldi: LDA+MLLT+SAT+MMI), language modeling for ASR & MT (text normalization, RNN-based LMs, n-gram model domain interpolation) and statistical translation techniques (hierarchical models, factored translation models, automatic casing and punctuation, comparable and bilingual corpora preparation). While results for the well-defined domains (phrases for travelers, parliament speeches, medical documentation, movie subtitling) are very encouraging, less defined domains (presentation, lectures) still form a challenge. Our progress in the IWSLT TED task (MT only) will be presented, as well as current progress in the Polish ASR.