 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Want This Product but Different : Multimodal Retrieval with Synthetic Query Expansion
Feb 17, 2021

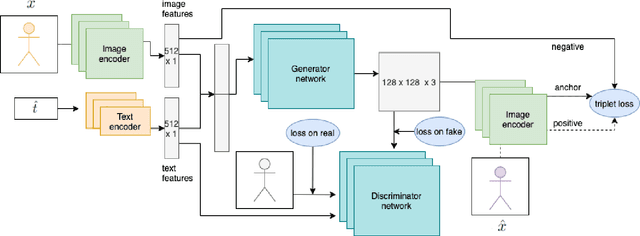
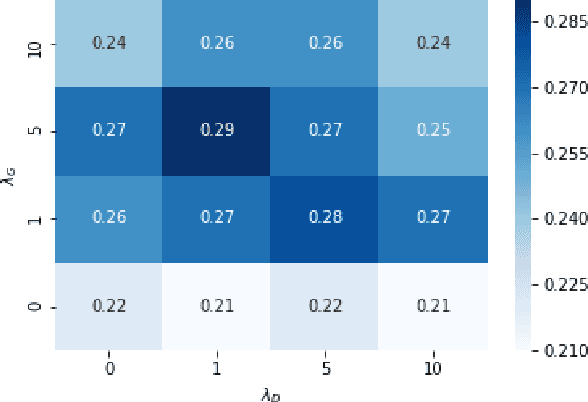
This paper addresses the problem of media retrieval using a multimodal query (a query which combines visual input with additional semantic information in natural language feedback). We propose a SynthTriplet GAN framework which resolves this task by expanding the multimodal query with a synthetically generated image that captures semantic information from both image and text input. We introduce a novel triplet mining method that uses a synthetic image as an anchor to directly optimize for embedding distances of generated and target images. We demonstrate that apart from the added value of retrieval illustration with synthetic image with the focus on customization and user feedback, the proposed method greatly surpasses other multimodal generation methods and achieves state of the art results in the multimodal retrieval task. We also show that in contrast to other retrieval methods, our method provides explainable embeddings.
Reducing catastrophic forgetting with learning on synthetic data
Apr 29, 2020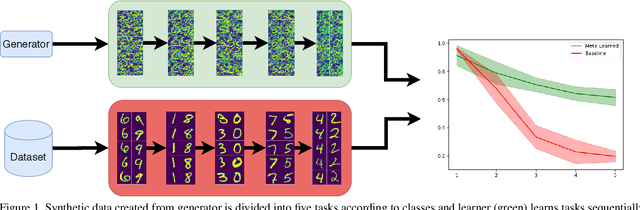
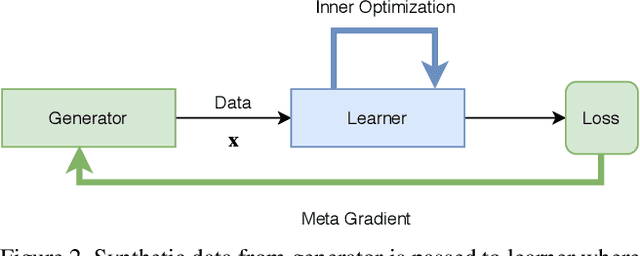
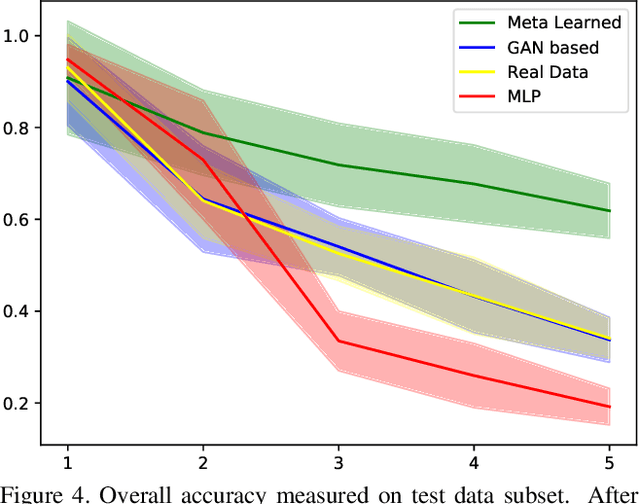
Catastrophic forgetting is a problem caused by neural networks' inability to learn data in sequence. After learning two tasks in sequence, performance on the first one drops significantly. This is a serious disadvantage that prevents many deep learning applications to real-life problems where not all object classes are known beforehand; or change in data requires adjustments to the model. To reduce this problem we investigate the use of synthetic data, namely we answer a question: Is it possible to generate such data synthetically which learned in sequence does not result in catastrophic forgetting? We propose a method to generate such data in two-step optimisation process via meta-gradients. Our experimental results on Split-MNIST dataset show that training a model on such synthetic data in sequence does not result in catastrophic forgetting. We also show that our method of generating data is robust to different learning scenarios.
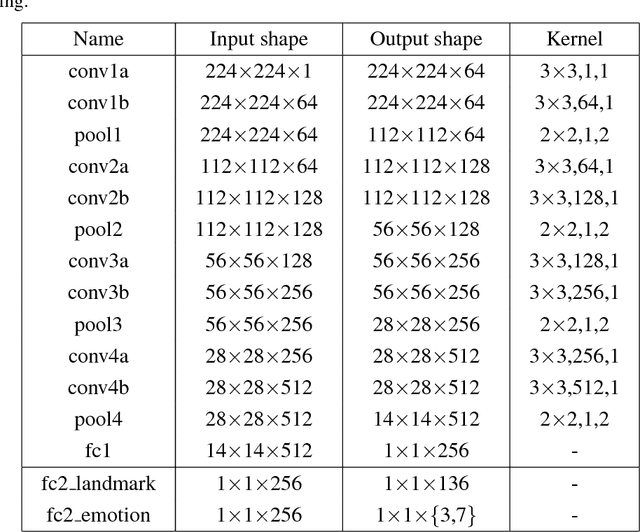
I Know How You Feel: Emotion Recognition with Facial Landmarks
Oct 23, 2018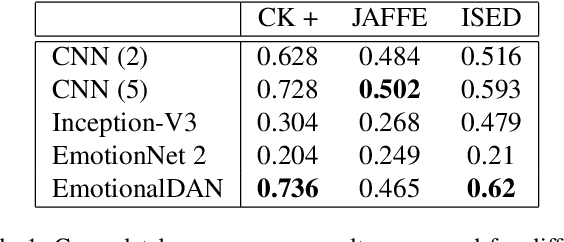

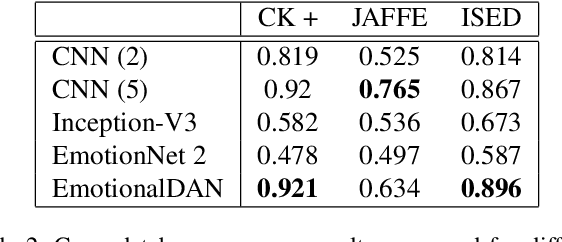
Classification of human emotions remains an important and challenging task for many computer vision algorithms, especially in the era of humanoid robots which coexist with humans in their everyday life. Currently proposed methods for emotion recognition solve this task using multi-layered convolutional networks that do not explicitly infer any facial features in the classification phase. In this work, we postulate a fundamentally different approach to solve emotion recognition task that relies on incorporating facial landmarks as a part of the classification loss function. To that end, we extend a recently proposed Deep Alignment Network (DAN), that achieves state-of-the-art results in the recent facial landmark recognition challenge, with a term related to facial features. Thanks to this simple modification, our model called EmotionalDAN is able to outperform state-of-the-art emotion classification methods on two challenging benchmark dataset by up to 5%.
Classifying and Visualizing Emotions with Emotional DAN
Oct 23, 2018

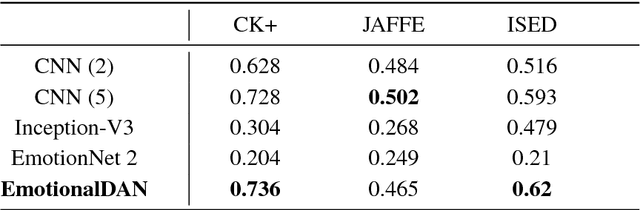
Classification of human emotions remains an important and challenging task for many computer vision algorithms, especially in the era of humanoid robots which coexist with humans in their everyday life. Currently proposed methods for emotion recognition solve this task using multi-layered convolutional networks that do not explicitly infer any facial features in the classification phase. In this work, we postulate a fundamentally different approach to solve emotion recognition task that relies on incorporating facial landmarks as a part of the classification loss function. To that end, we extend a recently proposed Deep Alignment Network (DAN) with a term related to facial features. Thanks to this simple modification, our model called EmotionalDAN is able to outperform state-of-the-art emotion classification methods on two challenging benchmark dataset by up to 5%. Furthermore, we visualize image regions analyzed by the network when making a decision and the results indicate that our EmotionalDAN model is able to correctly identify facial landmarks responsible for expressing the emotions.
What Looks Good with my Sofa: Multimodal Search Engine for Interior Design
Jan 08, 2018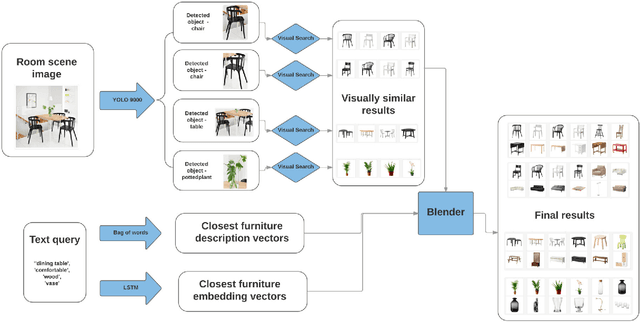

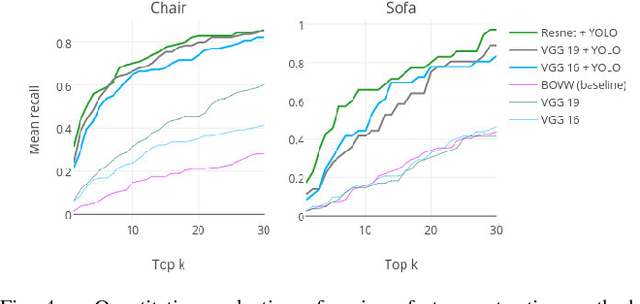
In this paper, we propose a multi-modal search engine for interior design that combines visual and textual queries. The goal of our engine is to retrieve interior objects, e.g. furniture or wall clocks, that share visual and aesthetic similarities with the query. Our search engine allows the user to take a photo of a room and retrieve with a high recall a list of items identical or visually similar to those present in the photo. Additionally, it allows to return other items that aesthetically and stylistically fit well together. To achieve this goal, our system blends the results obtained using textual and visual modalities. Thanks to this blending strategy, we increase the average style similarity score of the retrieved items by 11%. Our work is implemented as a Web-based application and it is planned to be opened to the public.
* FEDCSIS 5th Conference on Multimedia, Interaction, Design and Innovation (MIDI), 2017
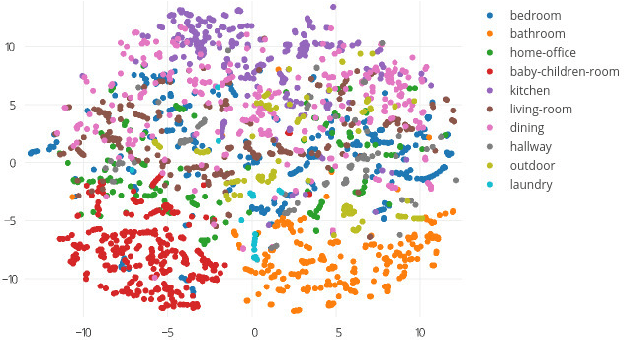
DeepStyle: Multimodal Search Engine for Fashion and Interior Design
Jan 08, 2018
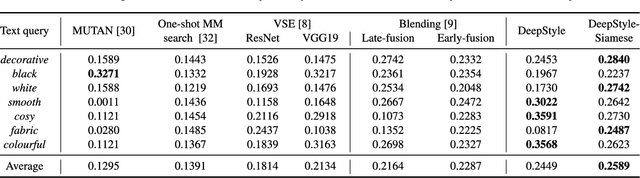
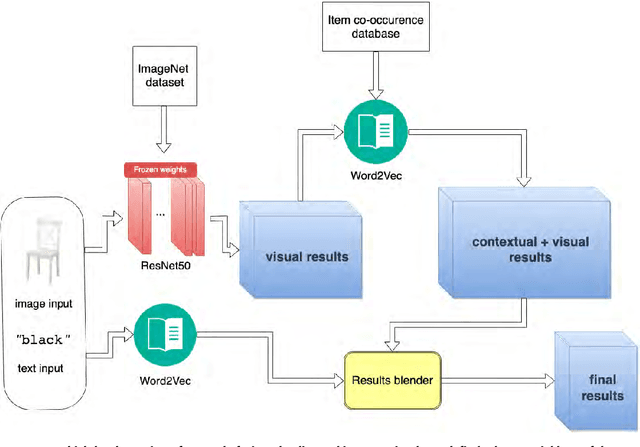
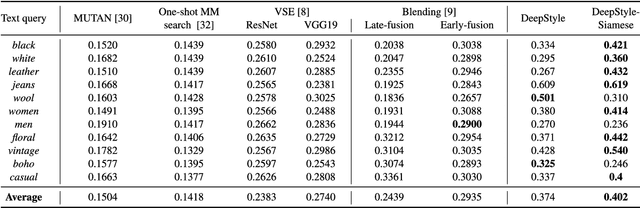
In this paper, we propose a multimodal search engine that combines visual and textual cues to retrieve items from a multimedia database aesthetically similar to the query. The goal of our engine is to enable intuitive retrieval of fashion merchandise such as clothes or furniture. Existing search engines treat textual input only as an additional source of information about the query image and do not correspond to the real-life scenario where the user looks for 'the same shirt but of denim'. Our novel method, dubbed DeepStyle, mitigates those shortcomings by using a joint neural network architecture to model contextual dependencies between features of different modalities. We prove the robustness of this approach on two different challenging datasets of fashion items and furniture where our DeepStyle engine outperforms baseline methods by 18-21% on the tested datasets. Our search engine is commercially deployed and available through a Web-based application.