 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOVE: Unsupervised Movable Object Segmentation and Detection
Oct 20, 2022
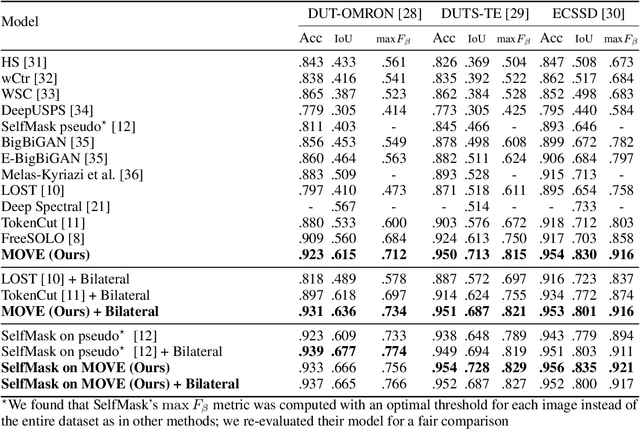


We introduce MOVE, a novel method to segment objects without any form of supervision. MOVE exploits the fact that foreground objects can be shifted locally relative to their initial position and result in realistic (undistorted) new images. This property allows us to train a segmentation model on a dataset of images without annotation and to achieve state of the art (SotA) performance on several evaluation datasets for unsupervised salient object detection and segmentation. In unsupervised single object discovery, MOVE gives an average CorLoc improvement of 7.2% over the SotA, and in unsupervised class-agnostic object detection it gives a relative AP improvement of 53% on average. Our approach is built on top of self-supervised features (e.g. from DINO or MAE), an inpainting network (based on the Masked AutoEncoder) and adversarial training.
Generative Adversarial Learning via Kernel Density Discrimination
Jul 13, 2021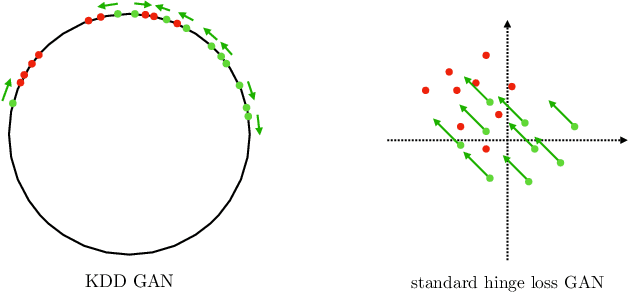
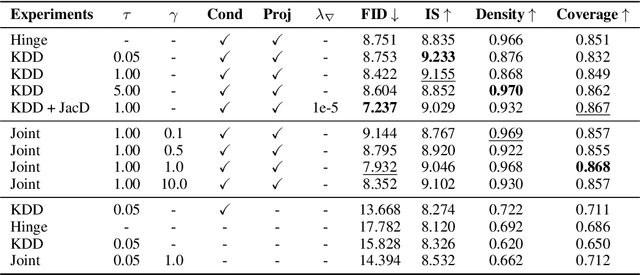

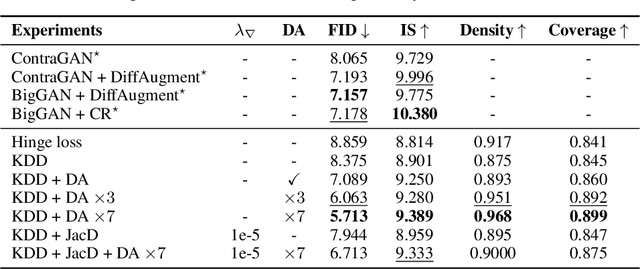
We introduce Kernel Density Discrimination GAN (KDD GAN), a novel method for generative adversarial learning. KDD GAN formulates the training as a likelihood ratio optimization problem where the data distributions are written explicitly via (local) Kernel Density Estimates (KDE). This is inspired by the recent progress in contrastive learning and its relation to KDE. We define the KDEs directly in feature space and forgo the requirement of invertibility of the kernel feature mappings. In our approach, features are no longer optimized for linear separability, as in the original GAN formulation, but for the more general discrimination of distributions in the feature space. We analyze the gradient of our loss with respect to the feature representation and show that it is better behaved than that of the original hinge loss. We perform experiments with the proposed KDE-based loss, used either as a training loss or a regularization term, on both CIFAR10 and scaled versions of ImageNet. We use BigGAN/SA-GAN as a backbone and baseline, since our focus is not to design the architecture of the networks. We show a boost in the quality of generated samples with respect to FID from 10% to 40% compared to the baseline. Code will be made available.
KaFiStO: A Kalman Filtering Framework for Stochastic Optimization
Jul 07, 2021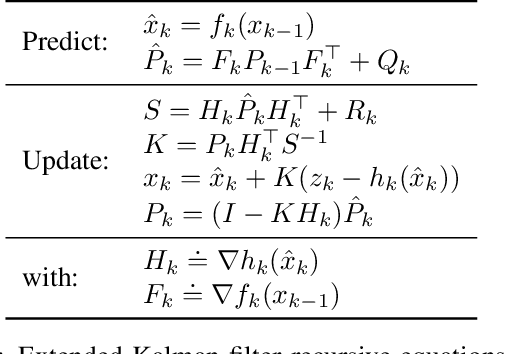
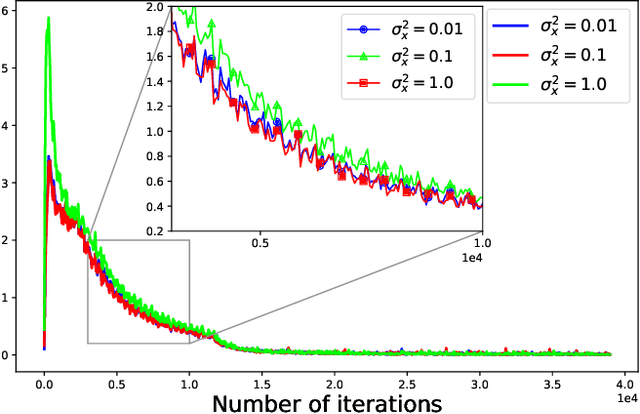
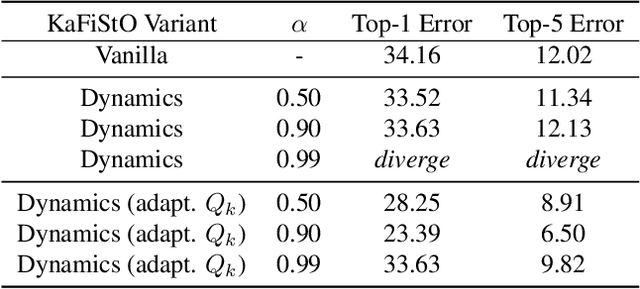
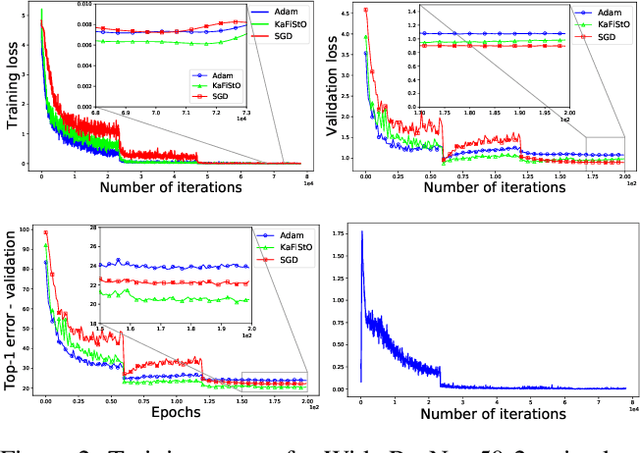
Optimization is often cast as a deterministic problem, where the solution is found through some iterative procedure such as gradient descent. However, when training neural networks the loss function changes over (iteration) time due to the randomized selection of a subset of the samples. This randomization turns the optimization problem into a stochastic one. We propose to consider the loss as a noisy observation with respect to some reference optimum. This interpretation of the loss allows us to adopt Kalman filtering as an optimizer, as its recursive formulation is designed to estimate unknown parameters from noisy measurements. Moreover, we show that the Kalman Filter dynamical model for the evolution of the unknown parameters can be used to capture the gradient dynamics of advanced methods such as Momentum and Adam. We call this stochastic optimization method KaFiStO. KaFiStO is an easy to implement, scalable, and efficient method to train neural networks. We show that it also yields parameter estimates that are on par with or better than existing optimization algorithms across several neural network architectures and machine learning tasks, such as computer vision and language modeling.
Emergence of Object Segmentation in Perturbed Generative Models
May 29, 2019



We introduce a novel framework to build a model that can learn how to segment objects from a collection of images without any human annotation. Our method builds on the observation that the location of object segments can be perturbed locally relative to a given background without affecting the realism of a scene. Our approach is to first train a generative model of a layered scene. The layered representation consists of a background image, a foreground image and the mask of the foreground. A composite image is then obtained by overlaying the masked foreground image onto the background. The generative model is trained in an adversarial fashion against a discriminator, which forces the generative model to produce realistic composite images. To force the generator to learn a representation where the foreground layer corresponds to an object, we perturb the output of the generative model by introducing a random shift of both the foreground image and mask relative to the background. Because the generator is unaware of the shift before computing its output, it must produce layered representations that are realistic for any such random perturbation. Finally, we learn to segment an image by defining an autoencoder consisting of an encoder, which we train, and the pre-trained generator as the decoder, which we freeze. The encoder maps an image to a feature vector, which is fed as input to the generator to give a composite image matching the original input image. Because the generator outputs an explicit layered representation of the scene, the encoder learns to detect and segment objects. We demonstrate this framework on real images of several object categories.
I Know How You Feel: Emotion Recognition with Facial Landmarks
Oct 23, 2018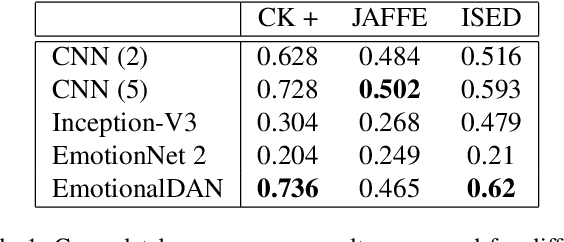

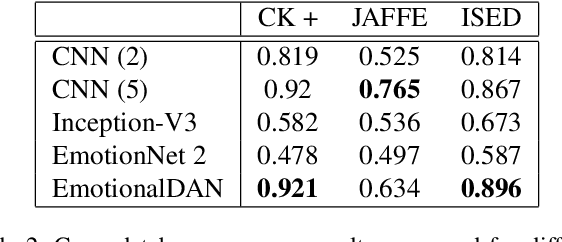
Classification of human emotions remains an important and challenging task for many computer vision algorithms, especially in the era of humanoid robots which coexist with humans in their everyday life. Currently proposed methods for emotion recognition solve this task using multi-layered convolutional networks that do not explicitly infer any facial features in the classification phase. In this work, we postulate a fundamentally different approach to solve emotion recognition task that relies on incorporating facial landmarks as a part of the classification loss function. To that end, we extend a recently proposed Deep Alignment Network (DAN), that achieves state-of-the-art results in the recent facial landmark recognition challenge, with a term related to facial features. Thanks to this simple modification, our model called EmotionalDAN is able to outperform state-of-the-art emotion classification methods on two challenging benchmark dataset by up to 5%.
Extracting textual overlays from social media videos using neural networks
May 01, 2018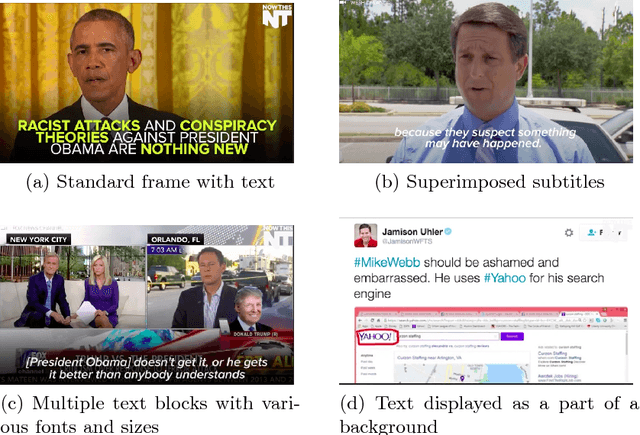
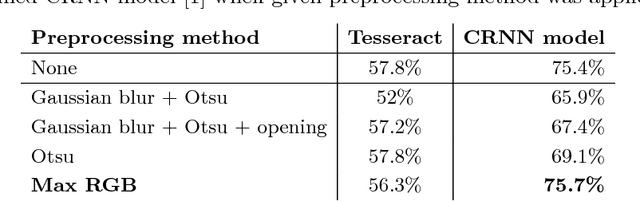
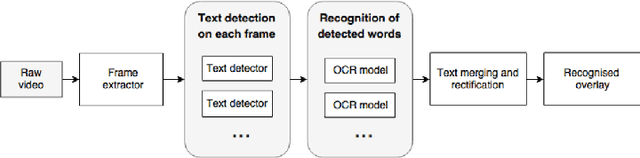
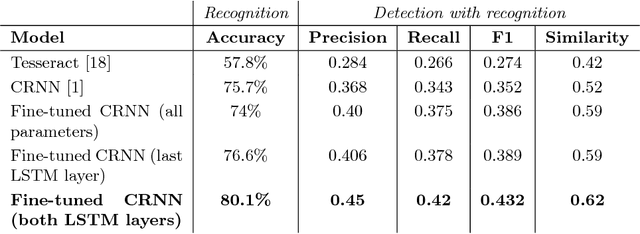
Textual overlays are often used in social media videos as people who watch them without the sound would otherwise miss essential information conveyed in the audio stream. This is why extraction of those overlays can serve as an important meta-data source, e.g. for content classification or retrieval tasks. In this work, we present a robust method for extracting textual overlays from videos that builds up on multiple neural network architectures. The proposed solution relies on several processing steps: keyframe extraction, text detection and text recognition. The main component of our system, i.e. the text recognition module, is inspired by a convolutional recurrent neural network architecture and we improve its performance using synthetically generated dataset of over 600,000 images with text prepared by authors specifically for this task. We also develop a filtering method that reduces the amount of overlapping text phrases using Levenshtein distance and further boosts system's performance. The final accuracy of our solution reaches over 80A% and is au pair with state-of-the-art methods.
Pay Attention to Virality: understanding popularity of social media videos with the attention mechanism
Apr 26, 2018

Predicting popularity of social media videos before they are published is a challenging task, mainly due to the complexity of content distribution network as well as the number of factors that play part in this process. As solving this task provides tremendous help for media content creators, many successful methods were proposed to solve this problem with machine learning. In this work, we change the viewpoint and postulate that it is not only the predicted popularity that matters, but also, maybe even more importantly, understanding of how individual parts influence the final popularity score. To that end, we propose to combine the Grad-CAM visualization method with a soft attention mechanism. Our preliminary results show that this approach allows for more intuitive interpretation of the content impact on video popularity, while achieving competitive results in terms of prediction accuracy.
SocialML: machine learning for social media video creators
Jan 25, 2018
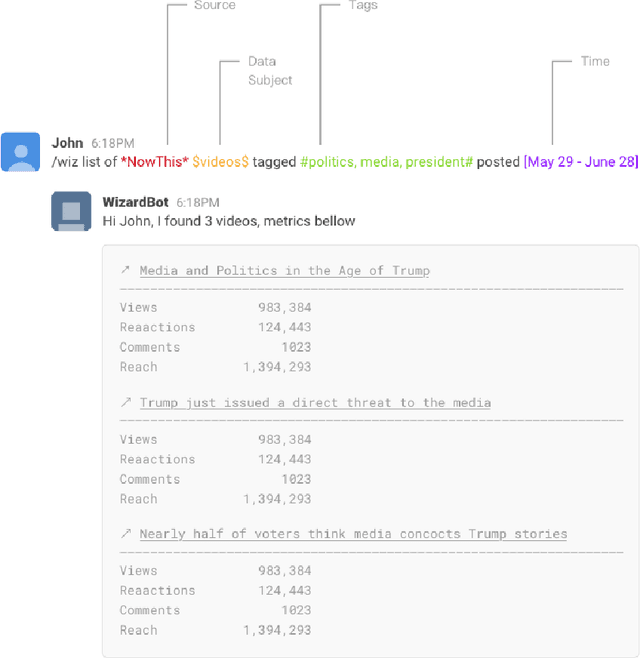


In the recent years, social media have become one of the main places where creative content is being published and consumed by billions of users. Contrary to traditional media, social media allow the publishers to receive almost instantaneous feedback regarding their creative work at an unprecedented scale. This is a perfect use case for machine learning methods that can use these massive amounts of data to provide content creators with inspirational ideas and constructive criticism of their work. In this work, we present a comprehensive overview of machine learning-empowered tools we developed for video creators at Group Nine Media - one of the major social media companies that creates short-form videos with over three billion views per month. Our main contribution is a set of tools that allow the creators to leverage massive amounts of data to improve their creation process, evaluate their videos before the publication and improve content quality. These applications include an interactive conversational bot that allows access to material archives, a Web-based application for automatic selection of optimal video thumbnail, as well as deep learning methods for optimizing headline and predicting video popularity. Our A/B tests show that deployment of our tools leads to significant increase of average video view count by 12.9%. Our additional contribution is a set of considerations collected during the deployment of those tools that can hel