 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExtracting textual overlays from social media videos using neural networks
Paper and Code
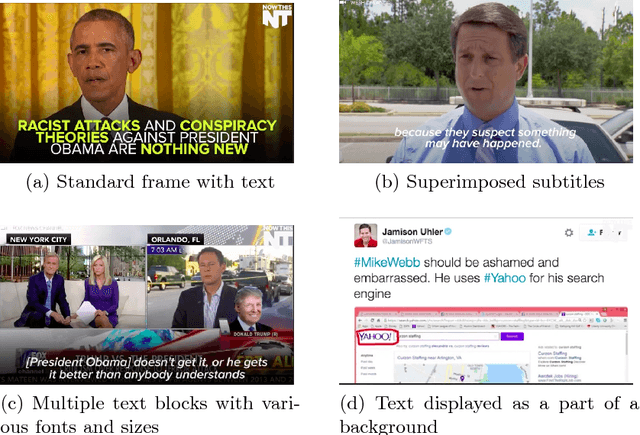
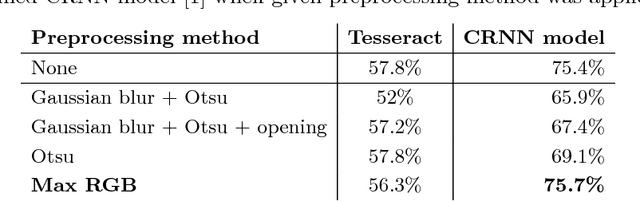
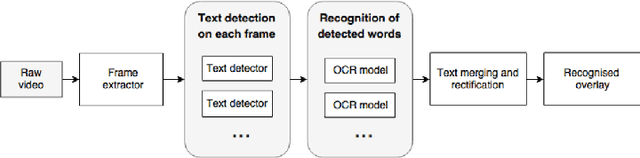
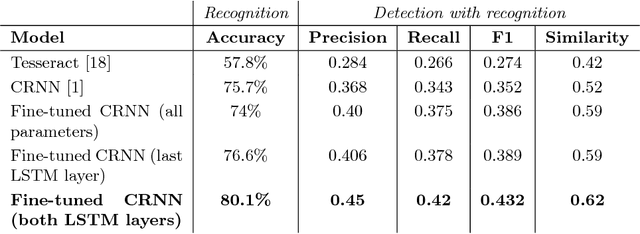
Textual overlays are often used in social media videos as people who watch them without the sound would otherwise miss essential information conveyed in the audio stream. This is why extraction of those overlays can serve as an important meta-data source, e.g. for content classification or retrieval tasks. In this work, we present a robust method for extracting textual overlays from videos that builds up on multiple neural network architectures. The proposed solution relies on several processing steps: keyframe extraction, text detection and text recognition. The main component of our system, i.e. the text recognition module, is inspired by a convolutional recurrent neural network architecture and we improve its performance using synthetically generated dataset of over 600,000 images with text prepared by authors specifically for this task. We also develop a filtering method that reduces the amount of overlapping text phrases using Levenshtein distance and further boosts system's performance. The final accuracy of our solution reaches over 80A% and is au pair with state-of-the-art methods.