 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMulti-View Unsupervised Image Generation with Cross Attention Guidance
Dec 07, 2023



The growing interest in novel view synthesis, driven by Neural Radiance Field (NeRF) models, is hindered by scalability issues due to their reliance on precisely annotated multi-view images. Recent models address this by fine-tuning large text2image diffusion models on synthetic multi-view data. Despite robust zero-shot generalization, they may need post-processing and can face quality issues due to the synthetic-real domain gap. This paper introduces a novel pipeline for unsupervised training of a pose-conditioned diffusion model on single-category datasets. With the help of pretrained self-supervised Vision Transformers (DINOv2), we identify object poses by clustering the dataset through comparing visibility and locations of specific object parts. The pose-conditioned diffusion model, trained on pose labels, and equipped with cross-frame attention at inference time ensures cross-view consistency, that is further aided by our novel hard-attention guidance. Our model, MIRAGE, surpasses prior work in novel view synthesis on real images. Furthermore, MIRAGE is robust to diverse textures and geometries, as demonstrated with our experiments on synthetic images generated with pretrained Stable Diffusion.
Sparse 3D Reconstruction via Object-Centric Ray Sampling
Sep 06, 2023



We propose a novel method for 3D object reconstruction from a sparse set of views captured from a 360-degree calibrated camera rig. We represent the object surface through a hybrid model that uses both an MLP-based neural representation and a triangle mesh. A key contribution in our work is a novel object-centric sampling scheme of the neural representation, where rays are shared among all views. This efficiently concentrates and reduces the number of samples used to update the neural model at each iteration. This sampling scheme relies on the mesh representation to ensure also that samples are well-distributed along its normals. The rendering is then performed efficiently by a differentiable renderer. We demonstrate that this sampling scheme results in a more effective training of the neural representation, does not require the additional supervision of segmentation masks, yields state of the art 3D reconstructions, and works with sparse views on the Google's Scanned Objects, Tank and Temples and MVMC Car datasets.
KaFiStO: A Kalman Filtering Framework for Stochastic Optimization
Jul 07, 2021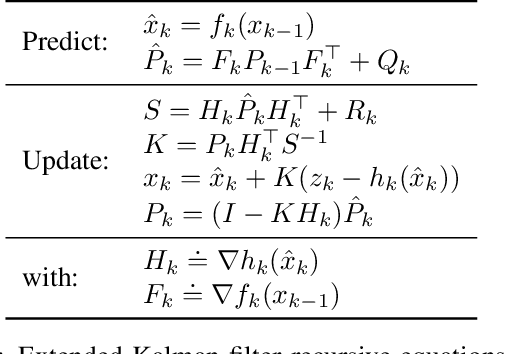
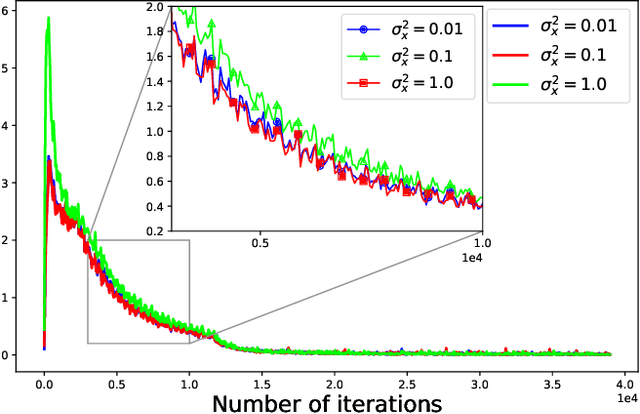
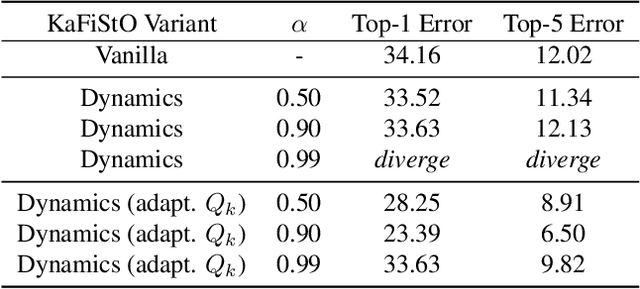
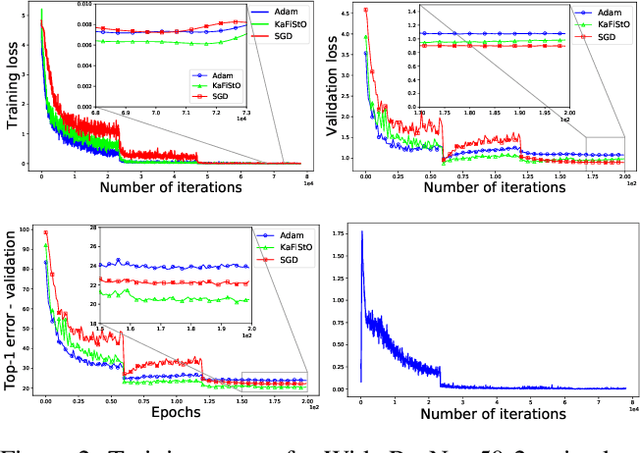
Optimization is often cast as a deterministic problem, where the solution is found through some iterative procedure such as gradient descent. However, when training neural networks the loss function changes over (iteration) time due to the randomized selection of a subset of the samples. This randomization turns the optimization problem into a stochastic one. We propose to consider the loss as a noisy observation with respect to some reference optimum. This interpretation of the loss allows us to adopt Kalman filtering as an optimizer, as its recursive formulation is designed to estimate unknown parameters from noisy measurements. Moreover, we show that the Kalman Filter dynamical model for the evolution of the unknown parameters can be used to capture the gradient dynamics of advanced methods such as Momentum and Adam. We call this stochastic optimization method KaFiStO. KaFiStO is an easy to implement, scalable, and efficient method to train neural networks. We show that it also yields parameter estimates that are on par with or better than existing optimization algorithms across several neural network architectures and machine learning tasks, such as computer vision and language modeling.
TDIOT: Target-driven Inference for Deep Video Object Tracking
Mar 23, 2021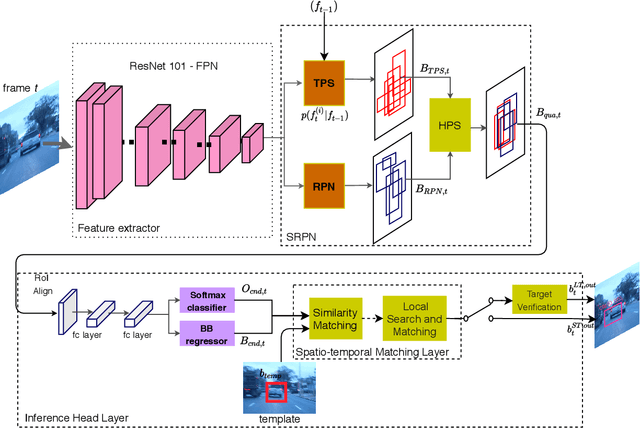

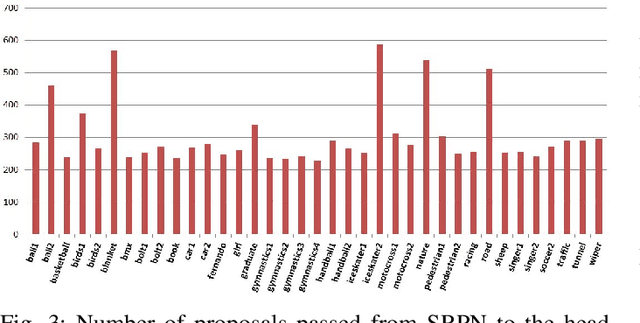
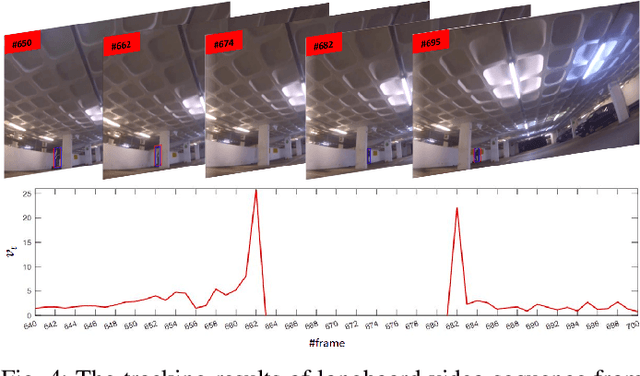
Recent tracking-by-detection approaches use deep object detectors as target detection baseline, because of their high performance on still images. For effective video object tracking, object detection is integrated with a data association step performed by either a custom design inference architecture or an end-to-end joint training for tracking purpose. In this work, we adopt the former approach and use the pre-trained Mask R-CNN deep object detector as the baseline. We introduce a novel inference architecture placed on top of FPN-ResNet101 backbone of Mask R-CNN to jointly perform detection and tracking, without requiring additional training for tracking purpose. The proposed single object tracker, TDIOT, applies an appearance similarity-based temporal matching for data association. In order to tackle tracking discontinuities, we incorporate a local search and matching module into the inference head layer that exploits SiamFC for short term tracking. Moreover, in order to improve robustness to scale changes, we introduce a scale adaptive region proposal network that enables to search the target at an adaptively enlarged spatial neighborhood specified by the trace of the target. In order to meet long term tracking requirements, a low cost verification layer is incorporated into the inference architecture to monitor presence of the target based on its LBP histogram model. Performance evaluation on videos from VOT2016, VOT2018 and VOT-LT2018 datasets demonstrate that TDIOT achieves higher accuracy compared to the state-of-the-art short-term trackers while it provides comparable performance in long term tracking.