 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTDIOT: Target-driven Inference for Deep Video Object Tracking
Mar 23, 2021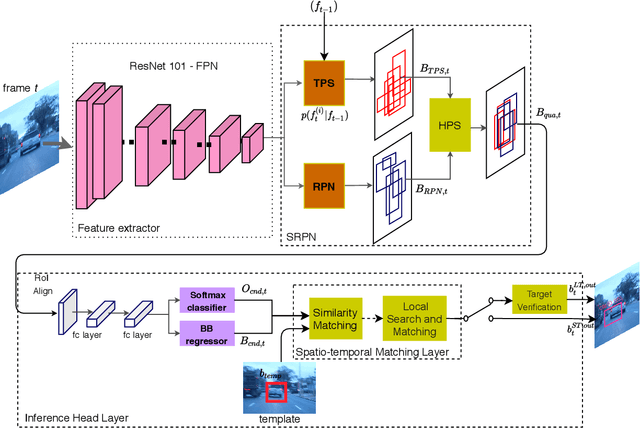

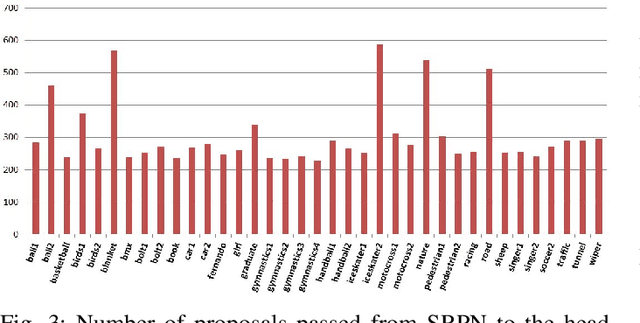
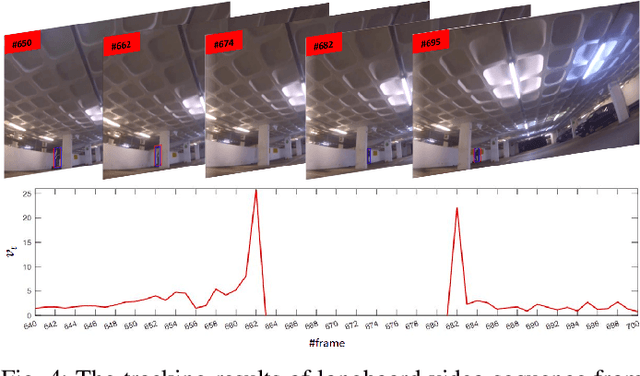
Recent tracking-by-detection approaches use deep object detectors as target detection baseline, because of their high performance on still images. For effective video object tracking, object detection is integrated with a data association step performed by either a custom design inference architecture or an end-to-end joint training for tracking purpose. In this work, we adopt the former approach and use the pre-trained Mask R-CNN deep object detector as the baseline. We introduce a novel inference architecture placed on top of FPN-ResNet101 backbone of Mask R-CNN to jointly perform detection and tracking, without requiring additional training for tracking purpose. The proposed single object tracker, TDIOT, applies an appearance similarity-based temporal matching for data association. In order to tackle tracking discontinuities, we incorporate a local search and matching module into the inference head layer that exploits SiamFC for short term tracking. Moreover, in order to improve robustness to scale changes, we introduce a scale adaptive region proposal network that enables to search the target at an adaptively enlarged spatial neighborhood specified by the trace of the target. In order to meet long term tracking requirements, a low cost verification layer is incorporated into the inference architecture to monitor presence of the target based on its LBP histogram model. Performance evaluation on videos from VOT2016, VOT2018 and VOT-LT2018 datasets demonstrate that TDIOT achieves higher accuracy compared to the state-of-the-art short-term trackers while it provides comparable performance in long term tracking.
Integration of Regularized l1 Tracking and Instance Segmentation for Video Object Tracking
Dec 30, 2019



We introduce a tracking-by-detection method that integrates a deep object detector with a particle filter tracker under the regularization framework where the tracked object is represented by a sparse dictionary. A novel observation model which establishes consensus between the detector and tracker is formulated that enables us to update the dictionary with the guidance of the deep detector. This yields an efficient representation of the object appearance through the video sequence hence improves robustness to occlusion and pose changes. Moreover we propose a new state vector consisting of translation, rotation, scaling and shearing parameters that allows tracking the deformed object bounding boxes hence significantly increases robustness to scale changes. Numerical results reported on challenging VOT2016 and VOT2018 benchmarking data sets demonstrate that the introduced tracker, L1DPF-M, achieves comparable robustness on both data sets while it outperforms state-of-the-art trackers on both data sets where the improvement achieved in success rate at IoU-th=0.5 is 11% and 9%, respectively.