 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNemotron 3 Super: Open, Efficient Mixture-of-Experts Hybrid Mamba-Transformer Model for Agentic Reasoning
Apr 14, 2026We describe the pre-training, post-training, and quantization of Nemotron 3 Super, a 120 billion (active 12 billion) parameter hybrid Mamba-Attention Mixture-of-Experts model. Nemotron 3 Super is the first model in the Nemotron 3 family to 1) be pre-trained in NVFP4, 2) leverage LatentMoE, a new Mixture-of-Experts architecture that optimizes for both accuracy per FLOP and accuracy per parameter, and 3) include MTP layers for inference acceleration through native speculative decoding. We pre-trained Nemotron 3 Super on 25 trillion tokens followed by post-training using supervised fine tuning (SFT) and reinforcement learning (RL). The final model supports up to 1M context length and achieves comparable accuracy on common benchmarks, while also achieving up to 2.2x and 7.5x higher inference throughput compared to GPT-OSS-120B and Qwen3.5-122B, respectively. Nemotron 3 Super datasets, along with the base, post-trained, and quantized checkpoints, are open-sourced on HuggingFace.
NVIDIA Nemotron Nano 2: An Accurate and Efficient Hybrid Mamba-Transformer Reasoning Model
Aug 21, 2025



We introduce Nemotron-Nano-9B-v2, a hybrid Mamba-Transformer language model designed to increase throughput for reasoning workloads while achieving state-of-the-art accuracy compared to similarly-sized models. Nemotron-Nano-9B-v2 builds on the Nemotron-H architecture, in which the majority of the self-attention layers in the common Transformer architecture are replaced with Mamba-2 layers, to achieve improved inference speed when generating the long thinking traces needed for reasoning. We create Nemotron-Nano-9B-v2 by first pre-training a 12-billion-parameter model (Nemotron-Nano-12B-v2-Base) on 20 trillion tokens using an FP8 training recipe. After aligning Nemotron-Nano-12B-v2-Base, we employ the Minitron strategy to compress and distill the model with the goal of enabling inference on up to 128k tokens on a single NVIDIA A10G GPU (22GiB of memory, bfloat16 precision). Compared to existing similarly-sized models (e.g., Qwen3-8B), we show that Nemotron-Nano-9B-v2 achieves on-par or better accuracy on reasoning benchmarks while achieving up to 6x higher inference throughput in reasoning settings like 8k input and 16k output tokens. We are releasing Nemotron-Nano-9B-v2, Nemotron-Nano12B-v2-Base, and Nemotron-Nano-9B-v2-Base checkpoints along with the majority of our pre- and post-training datasets on Hugging Face.
Enabling Visual Composition and Animation in Unsupervised Video Generation
Mar 21, 2024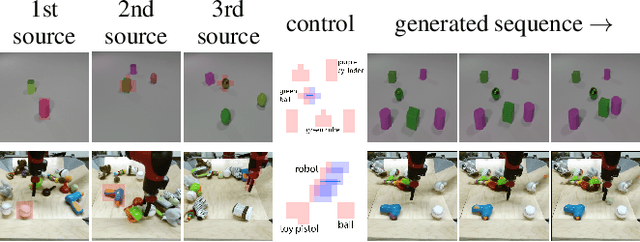



In this work we propose a novel method for unsupervised controllable video generation. Once trained on a dataset of unannotated videos, at inference our model is capable of both composing scenes of predefined object parts and animating them in a plausible and controlled way. This is achieved by conditioning video generation on a randomly selected subset of local pre-trained self-supervised features during training. We call our model CAGE for visual Composition and Animation for video GEneration. We conduct a series of experiments to demonstrate capabilities of CAGE in various settings. Project website: https://araachie.github.io/cage.
Multi-View Unsupervised Image Generation with Cross Attention Guidance
Dec 07, 2023



The growing interest in novel view synthesis, driven by Neural Radiance Field (NeRF) models, is hindered by scalability issues due to their reliance on precisely annotated multi-view images. Recent models address this by fine-tuning large text2image diffusion models on synthetic multi-view data. Despite robust zero-shot generalization, they may need post-processing and can face quality issues due to the synthetic-real domain gap. This paper introduces a novel pipeline for unsupervised training of a pose-conditioned diffusion model on single-category datasets. With the help of pretrained self-supervised Vision Transformers (DINOv2), we identify object poses by clustering the dataset through comparing visibility and locations of specific object parts. The pose-conditioned diffusion model, trained on pose labels, and equipped with cross-frame attention at inference time ensures cross-view consistency, that is further aided by our novel hard-attention guidance. Our model, MIRAGE, surpasses prior work in novel view synthesis on real images. Furthermore, MIRAGE is robust to diverse textures and geometries, as demonstrated with our experiments on synthetic images generated with pretrained Stable Diffusion.
Spatio-Temporal Crop Aggregation for Video Representation Learning
Nov 30, 2022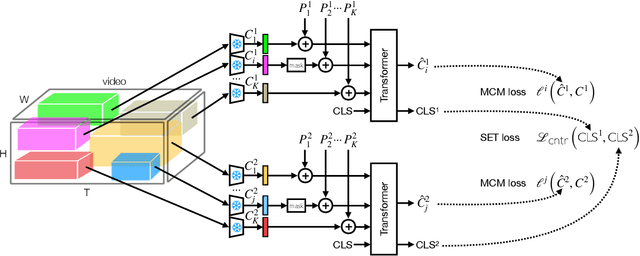
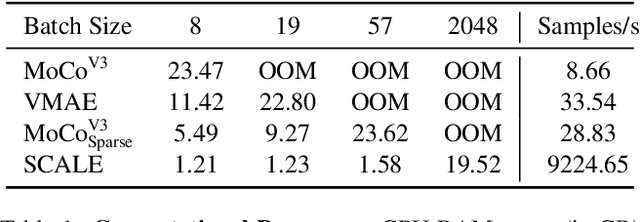
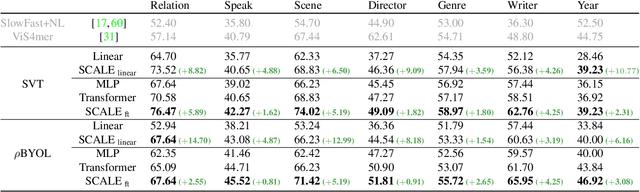
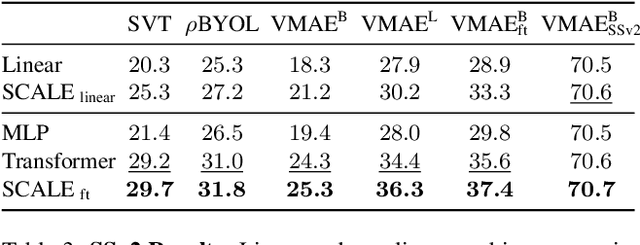
We propose Spatio-temporal Crop Aggregation for video representation LEarning (SCALE), a novel method that enjoys high scalability at both training and inference time. Our model builds long-range video features by learning from sets of video clip-level features extracted with a pre-trained backbone. To train the model, we propose a self-supervised objective consisting of masked clip feature prediction. We apply sparsity to both the input, by extracting a random set of video clips, and to the loss function, by only reconstructing the sparse inputs. Moreover, we use dimensionality reduction by working in the latent space of a pre-trained backbone applied to single video clips. The video representation is then obtained by taking the ensemble of the concatenation of embeddings of separate video clips with a video clip set summarization token. These techniques make our method not only extremely efficient to train, but also highly effective in transfer learning. We demonstrate that our video representation yields state-of-the-art performance with linear, non-linear, and $k$-NN probing on common action classification datasets.
Randomized Conditional Flow Matching for Video Prediction
Nov 26, 2022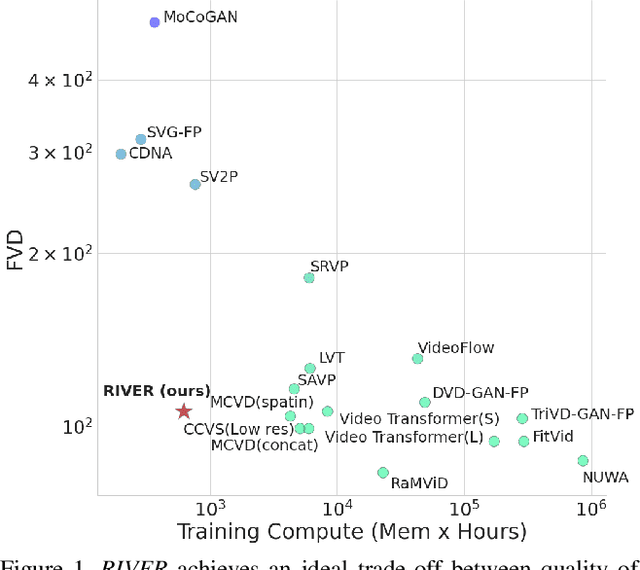
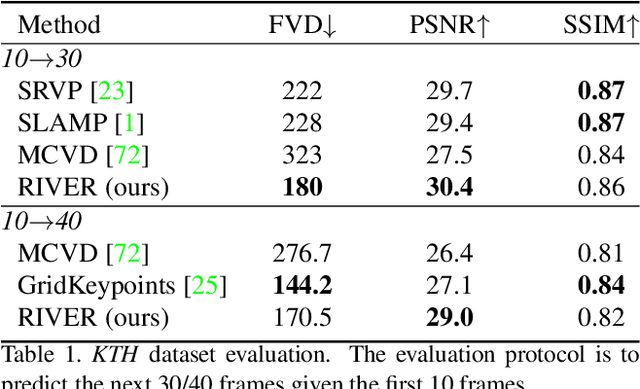
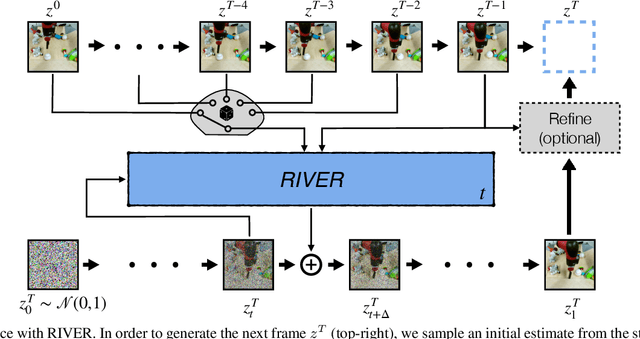
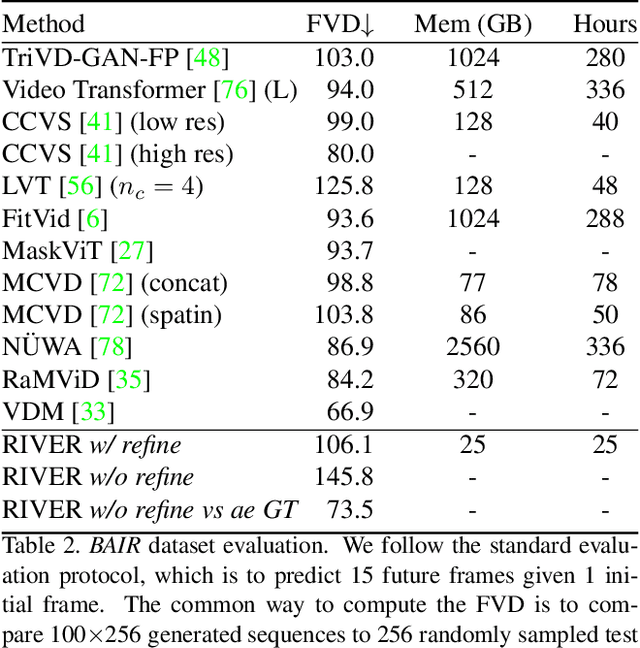
We introduce a novel generative model for video prediction based on latent flow matching, an efficient alternative to diffusion-based models. In contrast to prior work that either incurs a high training cost by modeling the past through a memory state, as in recurrent neural networks, or limits the computational load by conditioning only on a predefined window of past frames, we efficiently and effectively take the past into account by conditioning at inference time only on a small random set of past frames at each integration step of the learned flow. Moreover, to enable the generation of high-resolution videos and speed up the training, we work in the latent space of a pretrained VQGAN. Furthermore, we propose to approximate the initial condition of the flow ODE with the previous noisy frame. This allows to reduce the number of integration steps and hence, speed up the sampling at inference time. We call our model Random frame conditional flow Integration for VidEo pRediction, or, in short, RIVER. We show that RIVER achieves superior or on par performance compared to prior work on common video prediction benchmarks.
DILEMMA: Self-Supervised Shape and Texture Learning with Transformers
Apr 10, 2022

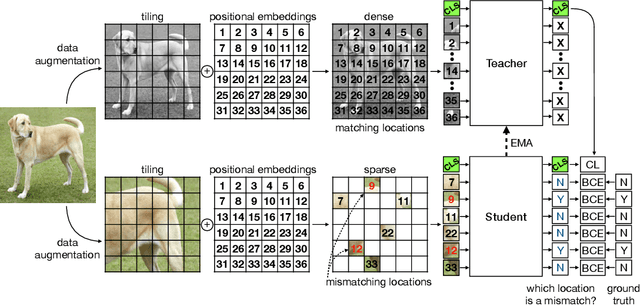

There is a growing belief that deep neural networks with a shape bias may exhibit better generalization capabilities than models with a texture bias, because shape is a more reliable indicator of the object category. However, we show experimentally that existing measures of shape bias are not stable predictors of generalization and argue that shape discrimination should not come at the expense of texture discrimination. Thus, we propose a pseudo-task to explicitly boost both shape and texture discriminability in models trained via self-supervised learning. For this purpose, we train a ViT to detect which input token has been combined with an incorrect positional embedding. To retain texture discrimination, the ViT is also trained as in MoCo with a student-teacher architecture and a contrastive loss over an extra learnable class token. We call our method DILEMMA, which stands for Detection of Incorrect Location EMbeddings with MAsked inputs. We evaluate our method through fine-tuning on several datasets and show that it outperforms MoCoV3 and DINO. Moreover, we show that when downstream tasks are strongly reliant on shape (such as in the YOGA-82 pose dataset), our pre-trained features yield a significant gain over prior work. Code will be released upon publication.
KaFiStO: A Kalman Filtering Framework for Stochastic Optimization
Jul 07, 2021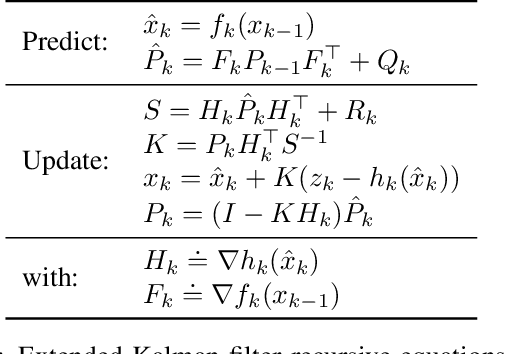
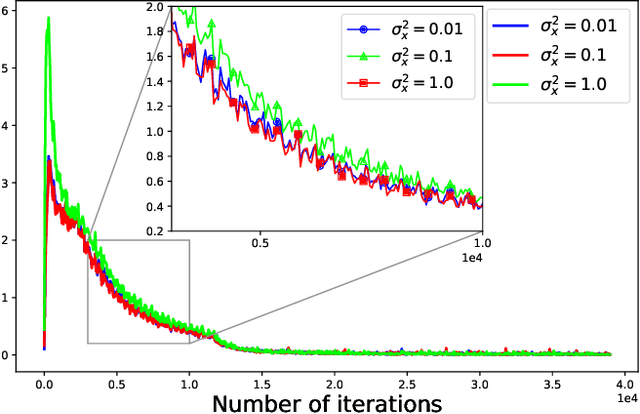
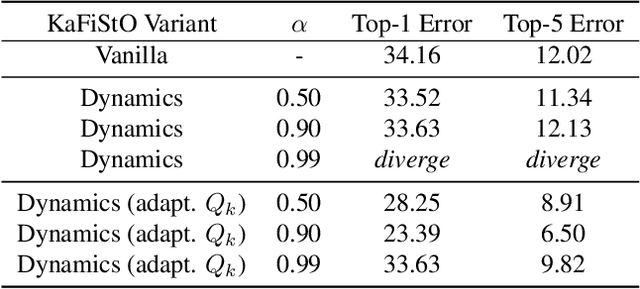
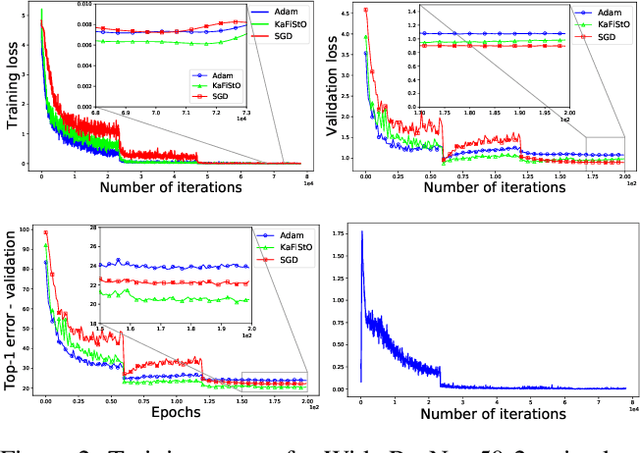
Optimization is often cast as a deterministic problem, where the solution is found through some iterative procedure such as gradient descent. However, when training neural networks the loss function changes over (iteration) time due to the randomized selection of a subset of the samples. This randomization turns the optimization problem into a stochastic one. We propose to consider the loss as a noisy observation with respect to some reference optimum. This interpretation of the loss allows us to adopt Kalman filtering as an optimizer, as its recursive formulation is designed to estimate unknown parameters from noisy measurements. Moreover, we show that the Kalman Filter dynamical model for the evolution of the unknown parameters can be used to capture the gradient dynamics of advanced methods such as Momentum and Adam. We call this stochastic optimization method KaFiStO. KaFiStO is an easy to implement, scalable, and efficient method to train neural networks. We show that it also yields parameter estimates that are on par with or better than existing optimization algorithms across several neural network architectures and machine learning tasks, such as computer vision and language modeling.