 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRandomized Conditional Flow Matching for Video Prediction
Paper and Code
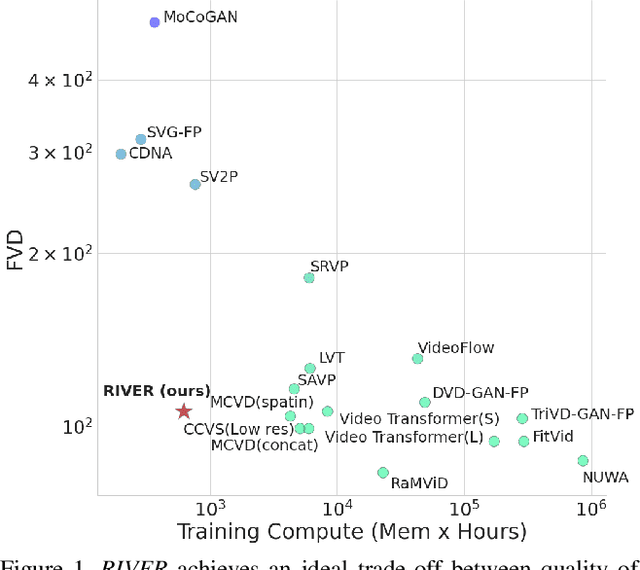
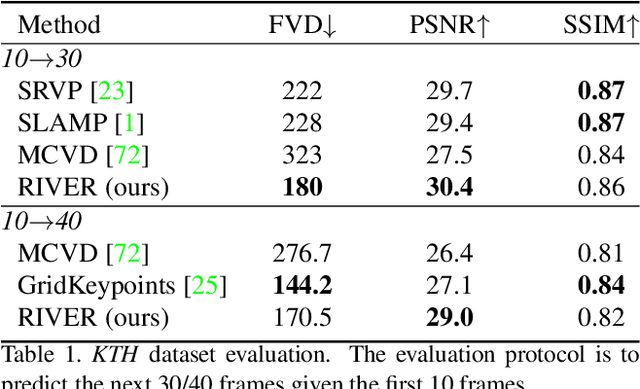
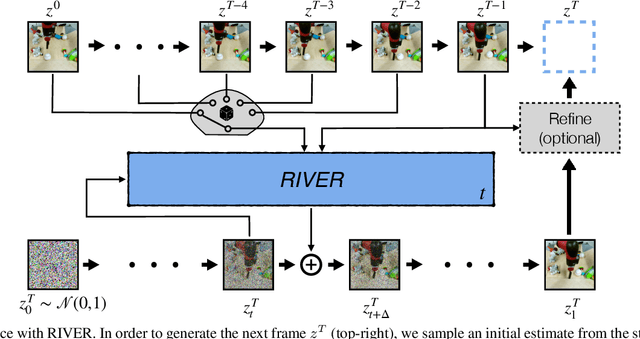
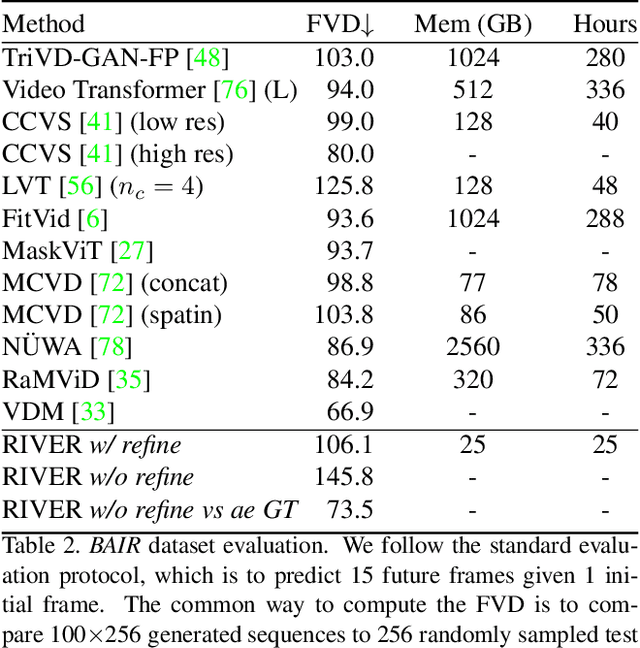
We introduce a novel generative model for video prediction based on latent flow matching, an efficient alternative to diffusion-based models. In contrast to prior work that either incurs a high training cost by modeling the past through a memory state, as in recurrent neural networks, or limits the computational load by conditioning only on a predefined window of past frames, we efficiently and effectively take the past into account by conditioning at inference time only on a small random set of past frames at each integration step of the learned flow. Moreover, to enable the generation of high-resolution videos and speed up the training, we work in the latent space of a pretrained VQGAN. Furthermore, we propose to approximate the initial condition of the flow ODE with the previous noisy frame. This allows to reduce the number of integration steps and hence, speed up the sampling at inference time. We call our model Random frame conditional flow Integration for VidEo pRediction, or, in short, RIVER. We show that RIVER achieves superior or on par performance compared to prior work on common video prediction benchmarks.