 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDILEMMA: Self-Supervised Shape and Texture Learning with Transformers
Paper and Code


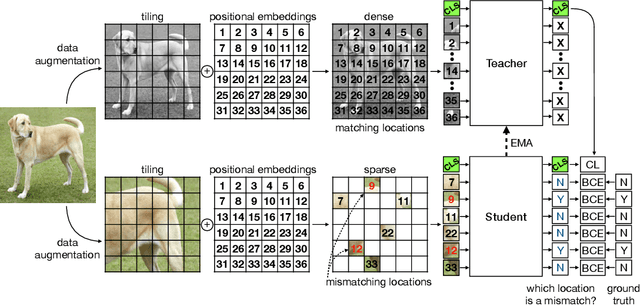

There is a growing belief that deep neural networks with a shape bias may exhibit better generalization capabilities than models with a texture bias, because shape is a more reliable indicator of the object category. However, we show experimentally that existing measures of shape bias are not stable predictors of generalization and argue that shape discrimination should not come at the expense of texture discrimination. Thus, we propose a pseudo-task to explicitly boost both shape and texture discriminability in models trained via self-supervised learning. For this purpose, we train a ViT to detect which input token has been combined with an incorrect positional embedding. To retain texture discrimination, the ViT is also trained as in MoCo with a student-teacher architecture and a contrastive loss over an extra learnable class token. We call our method DILEMMA, which stands for Detection of Incorrect Location EMbeddings with MAsked inputs. We evaluate our method through fine-tuning on several datasets and show that it outperforms MoCoV3 and DINO. Moreover, we show that when downstream tasks are strongly reliant on shape (such as in the YOGA-82 pose dataset), our pre-trained features yield a significant gain over prior work. Code will be released upon publication.