 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatio-Temporal Crop Aggregation for Video Representation Learning
Paper and Code
Nov 30, 2022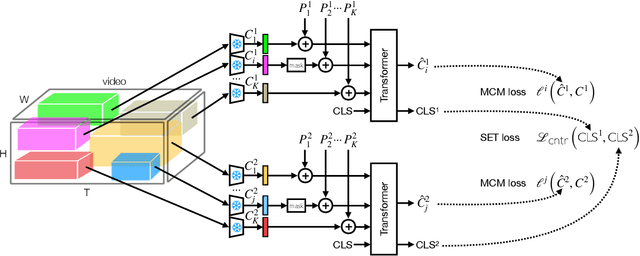
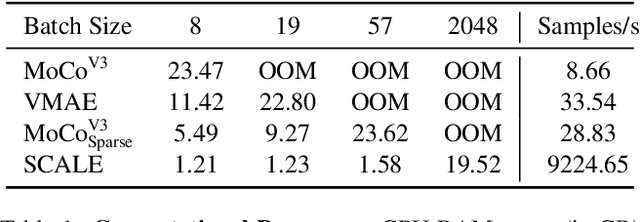
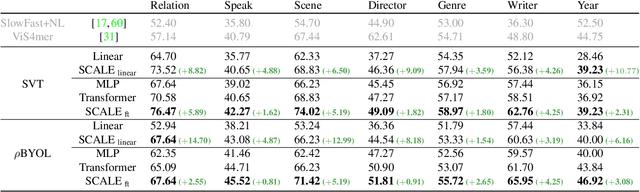
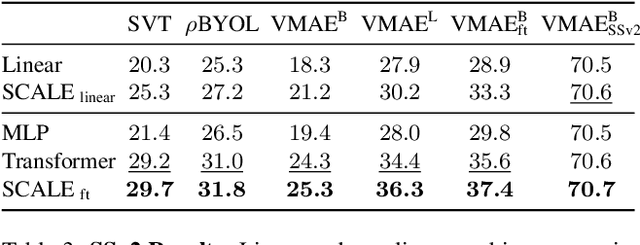
We propose Spatio-temporal Crop Aggregation for video representation LEarning (SCALE), a novel method that enjoys high scalability at both training and inference time. Our model builds long-range video features by learning from sets of video clip-level features extracted with a pre-trained backbone. To train the model, we propose a self-supervised objective consisting of masked clip feature prediction. We apply sparsity to both the input, by extracting a random set of video clips, and to the loss function, by only reconstructing the sparse inputs. Moreover, we use dimensionality reduction by working in the latent space of a pre-trained backbone applied to single video clips. The video representation is then obtained by taking the ensemble of the concatenation of embeddings of separate video clips with a video clip set summarization token. These techniques make our method not only extremely efficient to train, but also highly effective in transfer learning. We demonstrate that our video representation yields state-of-the-art performance with linear, non-linear, and $k$-NN probing on common action classification datasets.