 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeI Want This Product but Different : Multimodal Retrieval with Synthetic Query Expansion
Paper and Code
Feb 17, 2021

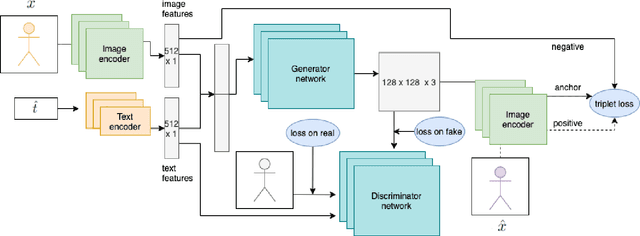
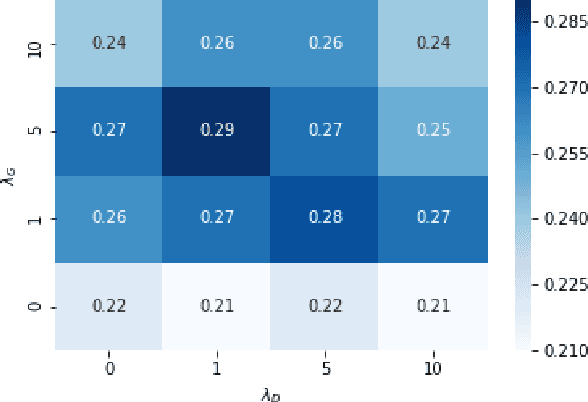
This paper addresses the problem of media retrieval using a multimodal query (a query which combines visual input with additional semantic information in natural language feedback). We propose a SynthTriplet GAN framework which resolves this task by expanding the multimodal query with a synthetically generated image that captures semantic information from both image and text input. We introduce a novel triplet mining method that uses a synthetic image as an anchor to directly optimize for embedding distances of generated and target images. We demonstrate that apart from the added value of retrieval illustration with synthetic image with the focus on customization and user feedback, the proposed method greatly surpasses other multimodal generation methods and achieves state of the art results in the multimodal retrieval task. We also show that in contrast to other retrieval methods, our method provides explainable embeddings.