 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizer choice matters for the emergence of Neural Collapse
Feb 18, 2026Neural Collapse (NC) refers to the emergence of highly symmetric geometric structures in the representations of deep neural networks during the terminal phase of training. Despite its prevalence, the theoretical understanding of NC remains limited. Existing analyses largely ignore the role of the optimizer, thereby suggesting that NC is universal across optimization methods. In this work, we challenge this assumption and demonstrate that the choice of optimizer plays a critical role in the emergence of NC. The phenomenon is typically quantified through NC metrics, which, however, are difficult to track and analyze theoretically. To overcome this limitation, we introduce a novel diagnostic metric, NC0, whose convergence to zero is a necessary condition for NC. Using NC0, we provide theoretical evidence that NC cannot emerge under decoupled weight decay in adaptive optimizers, as implemented in AdamW. Concretely, we prove that SGD, SignGD with coupled weight decay (a special case of Adam), and SignGD with decoupled weight decay (a special case of AdamW) exhibit qualitatively different NC0 dynamics. Also, we show the accelerating effect of momentum on NC (beyond convergence of train loss) when trained with SGD, being the first result concerning momentum in the context of NC. Finally, we conduct extensive empirical experiments consisting of 3,900 training runs across various datasets, architectures, optimizers, and hyperparameters, confirming our theoretical results. This work provides the first theoretical explanation for optimizer-dependent emergence of NC and highlights the overlooked role of weight-decay coupling in shaping the implicit biases of optimizers.
On consequences of finetuning on data with highly discriminative features
Oct 30, 2023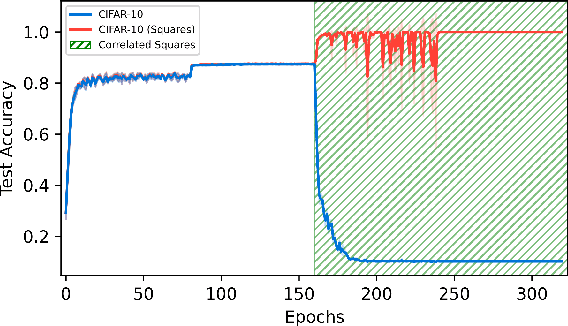


In the era of transfer learning, training neural networks from scratch is becoming obsolete. Transfer learning leverages prior knowledge for new tasks, conserving computational resources. While its advantages are well-documented, we uncover a notable drawback: networks tend to prioritize basic data patterns, forsaking valuable pre-learned features. We term this behavior "feature erosion" and analyze its impact on network performance and internal representations.
The Tunnel Effect: Building Data Representations in Deep Neural Networks
May 31, 2023
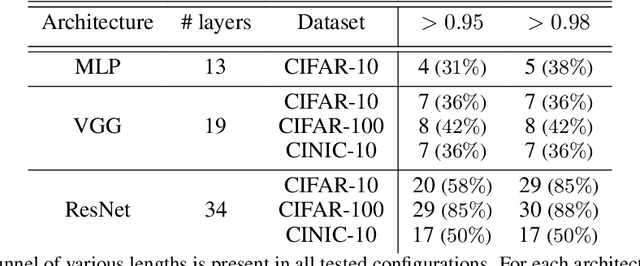
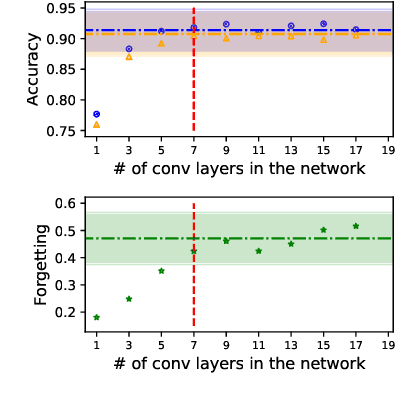
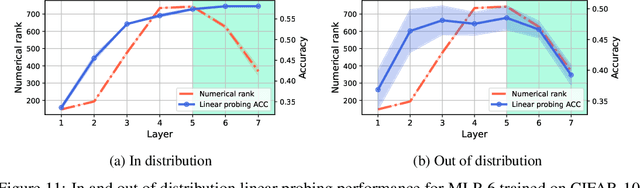
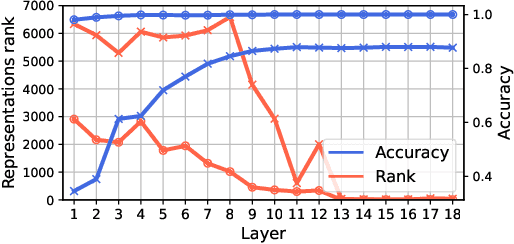
Deep neural networks are widely known for their remarkable effectiveness across various tasks, with the consensus that deeper networks implicitly learn more complex data representations. This paper shows that sufficiently deep networks trained for supervised image classification split into two distinct parts that contribute to the resulting data representations differently. The initial layers create linearly-separable representations, while the subsequent layers, which we refer to as \textit{the tunnel}, compress these representations and have a minimal impact on the overall performance. We explore the tunnel's behavior through comprehensive empirical studies, highlighting that it emerges early in the training process. Its depth depends on the relation between the network's capacity and task complexity. Furthermore, we show that the tunnel degrades out-of-distribution generalization and discuss its implications for continual learning.
Classification and Self-Supervised Regression of Arrhythmic ECG Signals Using Convolutional Neural Networks
Oct 25, 2022
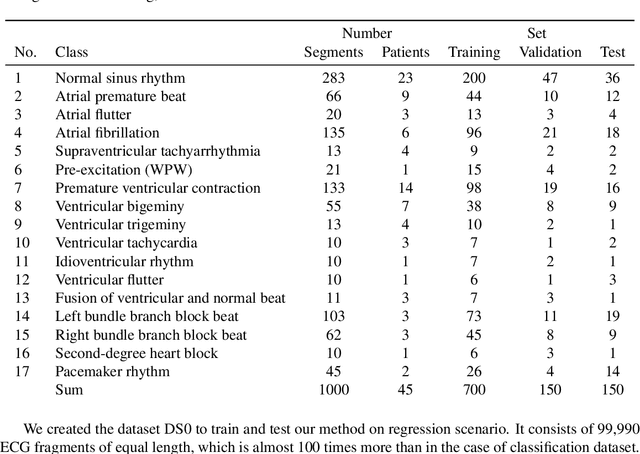
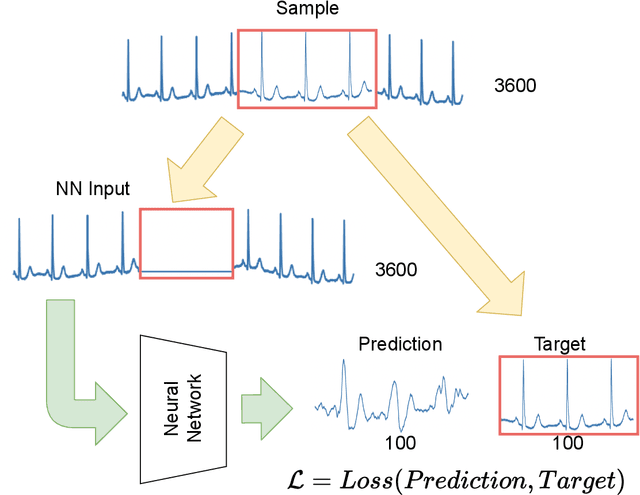

Interpretation of electrocardiography (ECG) signals is required for diagnosing cardiac arrhythmia. Recently, machine learning techniques have been applied for automated computer-aided diagnosis. Machine learning tasks can be divided into regression and classification. Regression can be used for noise and artifacts removal as well as resolve issues of missing data from low sampling frequency. Classification task concerns the prediction of output diagnostic classes according to expert-labeled input classes. In this work, we propose a deep neural network model capable of solving regression and classification tasks. Moreover, we combined the two approaches, using unlabeled and labeled data, to train the model. We tested the model on the MIT-BIH Arrhythmia database. Our method showed high effectiveness in detecting cardiac arrhythmia based on modified Lead II ECG records, as well as achieved high quality of ECG signal approximation. For the former, our method attained overall accuracy of 87:33% and balanced accuracy of 80:54%, on par with reference approaches. For the latter, application of self-supervised learning allowed for training without the need for expert labels. The regression model yielded satisfactory performance with fairly accurate prediction of QRS complexes. Transferring knowledge from regression to the classification task, our method attained higher overall accuracy of 87:78%.
Reinforcement learning with experience replay and adaptation of action dispersion
Jul 30, 2022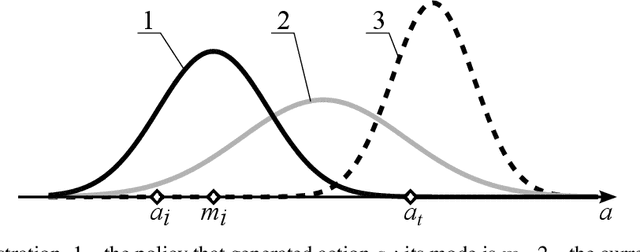


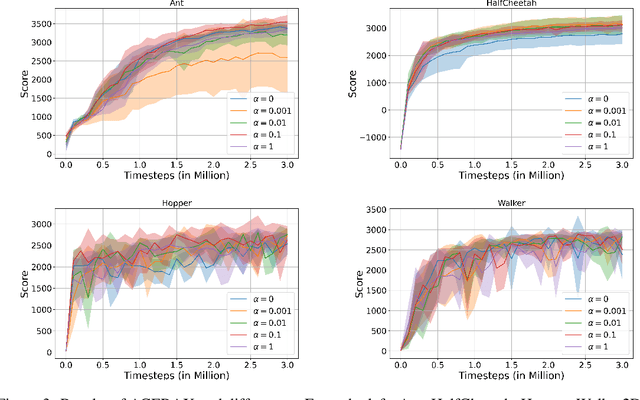
Effective reinforcement learning requires a proper balance of exploration and exploitation defined by the dispersion of action distribution. However, this balance depends on the task, the current stage of the learning process, and the current environment state. Existing methods that designate the action distribution dispersion require problem-dependent hyperparameters. In this paper, we propose to automatically designate the action distribution dispersion using the following principle: This distribution should have sufficient dispersion to enable the evaluation of future policies. To that end, the dispersion should be tuned to assure a sufficiently high probability (densities) of the actions in the replay buffer and the modes of the distributions that generated them, yet this dispersion should not be higher. This way, a policy can be effectively evaluated based on the actions in the buffer, but exploratory randomness in actions decreases when this policy converges. The above principle is verified here on challenging benchmarks Ant, HalfCheetah, Hopper, and Walker2D, with good results. Our method makes the action standard deviations converge to values similar to those resulting from trial-and-error optimization.
Logarithmic Continual Learning
Jan 17, 2022We introduce a neural network architecture that logarithmically reduces the number of self-rehearsal steps in the generative rehearsal of continually learned models. In continual learning (CL), training samples come in subsequent tasks, and the trained model can access only a single task at a time. To replay previous samples, contemporary CL methods bootstrap generative models and train them recursively with a combination of current and regenerated past data. This recurrence leads to superfluous computations as the same past samples are regenerated after each task, and the reconstruction quality successively degrades. In this work, we address these limitations and propose a new generative rehearsal architecture that requires at most logarithmic number of retraining for each sample. Our approach leverages allocation of past data in a~set of generative models such that most of them do not require retraining after a~task. The experimental evaluation of our logarithmic continual learning approach shows the superiority of our method with respect to the state-of-the-art generative rehearsal methods.
On robustness of generative representations against catastrophic forgetting
Sep 04, 2021

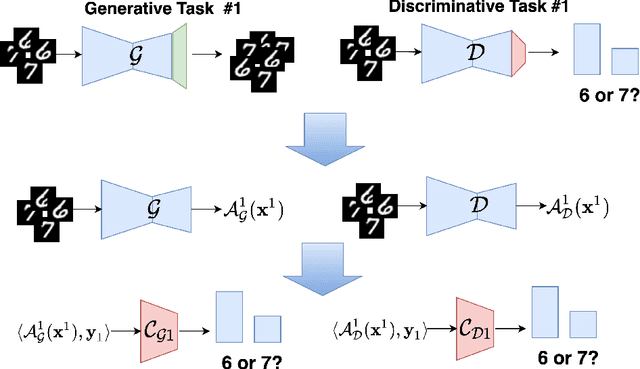
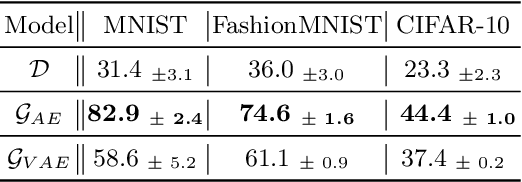
Catastrophic forgetting of previously learned knowledge while learning new tasks is a widely observed limitation of contemporary neural networks. Although many continual learning methods are proposed to mitigate this drawback, the main question remains unanswered: what is the root cause of catastrophic forgetting? In this work, we aim at answering this question by posing and validating a set of research hypotheses related to the specificity of representations built internally by neural models. More specifically, we design a set of empirical evaluations that compare the robustness of representations in discriminative and generative models against catastrophic forgetting. We observe that representations learned by discriminative models are more prone to catastrophic forgetting than their generative counterparts, which sheds new light on the advantages of developing generative models for continual learning. Finally, our work opens new research pathways and possibilities to adopt generative models in continual learning beyond mere replay mechanisms.
Multiband VAE: Latent Space Partitioning for Knowledge Consolidation in Continual Learning
Jun 23, 2021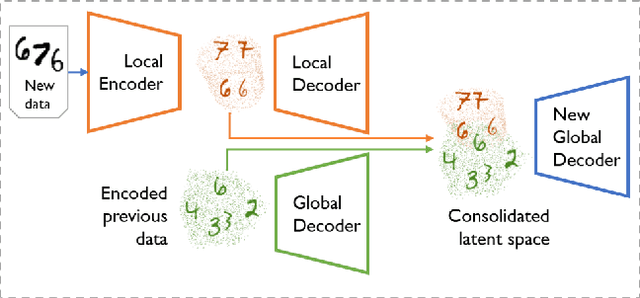
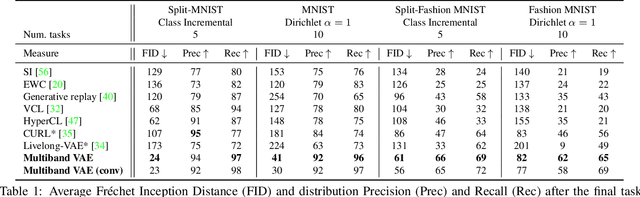
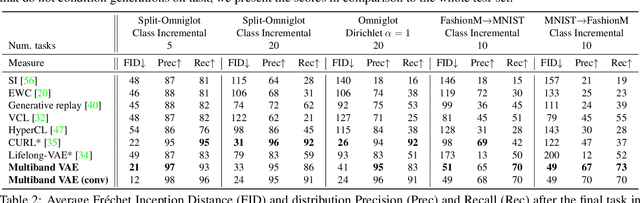
We propose a new method for unsupervised continual knowledge consolidation in generative models that relies on the partitioning of Variational Autoencoder's latent space. Acquiring knowledge about new data samples without forgetting previous ones is a critical problem of continual learning. Currently proposed methods achieve this goal by extending the existing model while constraining its behavior not to degrade on the past data, which does not exploit the full potential of relations within the entire training dataset. In this work, we identify this limitation and posit the goal of continual learning as a knowledge accumulation task. We solve it by continuously re-aligning latent space partitions that we call bands which are representations of samples seen in different tasks, driven by the similarity of the information they contain. In addition, we introduce a simple yet effective method for controlled forgetting of past data that improves the quality of reconstructions encoded in latent bands and a latent space disentanglement technique that improves knowledge consolidation. On top of the standard continual learning evaluation benchmarks, we evaluate our method on a new knowledge consolidation scenario and show that the proposed approach outperforms state-of-the-art by up to twofold across all testing scenarios.
Reinforcement learning for optimization of variational quantum circuit architectures
Mar 30, 2021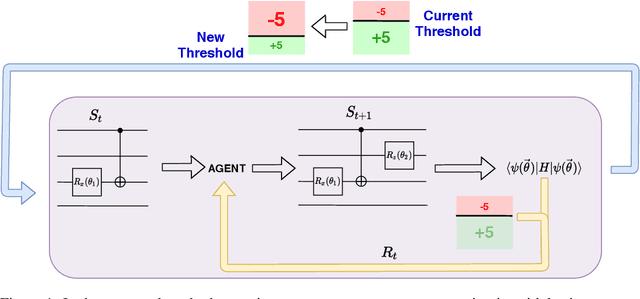

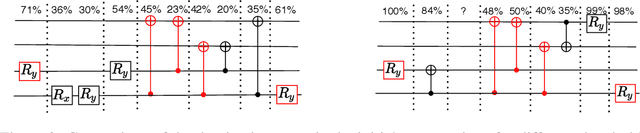
The study of Variational Quantum Eigensolvers (VQEs) has been in the spotlight in recent times as they may lead to real-world applications of near-term quantum devices. However, their performance depends on the structure of the used variational ansatz, which requires balancing the depth and expressivity of the corresponding circuit. In recent years, various methods for VQE structure optimization have been introduced but the capacities of machine learning to aid with this problem has not yet been fully investigated. In this work, we propose a reinforcement learning algorithm that autonomously explores the space of possible ans{\"a}tze, identifying economic circuits which still yield accurate ground energy estimates. The algorithm is intrinsically motivated, and it incrementally improves the accuracy of the result while minimizing the circuit depth. We showcase the performance of our algorithm on the problem of estimating the ground-state energy of lithium hydride (LiH). In this well-known benchmark problem, we achieve chemical accuracy, as well as state-of-the-art results in terms of circuit depth.
BinPlay: A Binary Latent Autoencoder for Generative Replay Continual Learning
Nov 25, 2020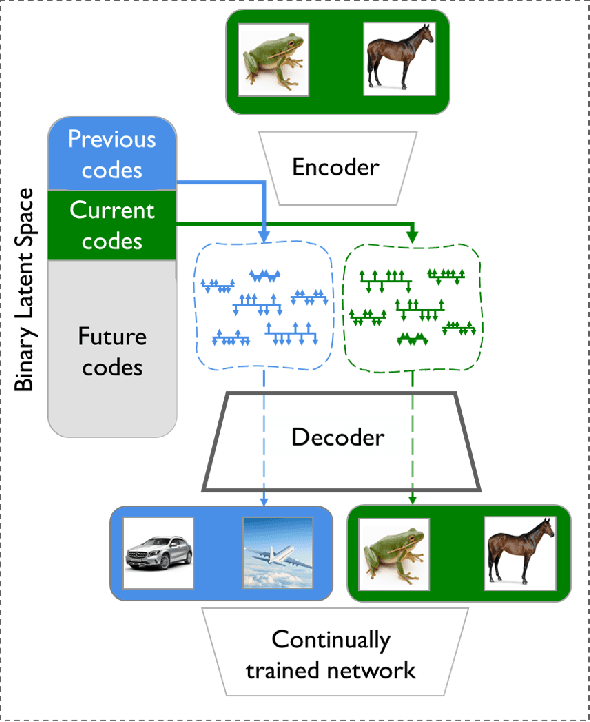

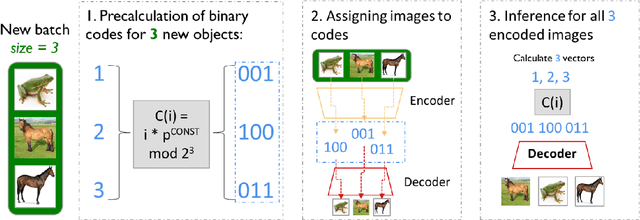
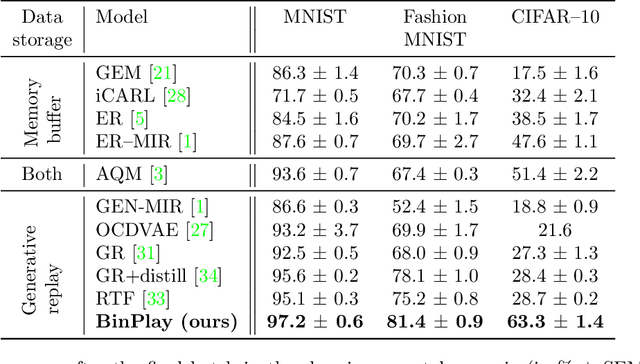
We introduce a binary latent space autoencoder architecture to rehearse training samples for the continual learning of neural networks. The ability to extend the knowledge of a model with new data without forgetting previously learned samples is a fundamental requirement in continual learning. Existing solutions address it by either replaying past data from memory, which is unsustainable with growing training data, or by reconstructing past samples with generative models that are trained to generalize beyond training data and, hence, miss important details of individual samples. In this paper, we take the best of both worlds and introduce a novel generative rehearsal approach called BinPlay. Its main objective is to find a quality-preserving encoding of past samples into precomputed binary codes living in the autoencoder's binary latent space. Since we parametrize the formula for precomputing the codes only on the chronological indices of the training samples, the autoencoder is able to compute the binary embeddings of rehearsed samples on the fly without the need to keep them in memory. Evaluation on three benchmark datasets shows up to a twofold accuracy improvement of BinPlay versus competing generative replay methods.