 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom ACR O-RADS 2022 to Explainable Deep Learning: Comparative Performance of Expert Radiologists, Convolutional Neural Networks, Vision Transformers, and Fusion Models in Ovarian Masses
Nov 09, 2025Background: The 2022 update of the Ovarian-Adnexal Reporting and Data System (O-RADS) ultrasound classification refines risk stratification for adnexal lesions, yet human interpretation remains subject to variability and conservative thresholds. Concurrently, deep learning (DL) models have demonstrated promise in image-based ovarian lesion characterization. This study evaluates radiologist performance applying O-RADS v2022, compares it to leading convolutional neural network (CNN) and Vision Transformer (ViT) models, and investigates the diagnostic gains achieved by hybrid human-AI frameworks. Methods: In this single-center, retrospective cohort study, a total of 512 adnexal mass images from 227 patients (110 with at least one malignant cyst) were included. Sixteen DL models, including DenseNets, EfficientNets, ResNets, VGGs, Xception, and ViTs, were trained and validated. A hybrid model integrating radiologist O-RADS scores with DL-predicted probabilities was also built for each scheme. Results: Radiologist-only O-RADS assessment achieved an AUC of 0.683 and an overall accuracy of 68.0%. CNN models yielded AUCs of 0.620 to 0.908 and accuracies of 59.2% to 86.4%, while ViT16-384 reached the best performance, with an AUC of 0.941 and an accuracy of 87.4%. Hybrid human-AI frameworks further significantly enhanced the performance of CNN models; however, the improvement for ViT models was not statistically significant (P-value >0.05). Conclusions: DL models markedly outperform radiologist-only O-RADS v2022 assessment, and the integration of expert scores with AI yields the highest diagnostic accuracy and discrimination. Hybrid human-AI paradigms hold substantial potential to standardize pelvic ultrasound interpretation, reduce false positives, and improve detection of high-risk lesions.
ResCap-DBP: A Lightweight Residual-Capsule Network for Accurate DNA-Binding Protein Prediction Using Global ProteinBERT Embeddings
Jul 27, 2025DNA-binding proteins (DBPs) are integral to gene regulation and cellular processes, making their accurate identification essential for understanding biological functions and disease mechanisms. Experimental methods for DBP identification are time-consuming and costly, driving the need for efficient computational prediction techniques. In this study, we propose a novel deep learning framework, ResCap-DBP, that combines a residual learning-based encoder with a one-dimensional Capsule Network (1D-CapsNet) to predict DBPs directly from raw protein sequences. Our architecture incorporates dilated convolutions within residual blocks to mitigate vanishing gradient issues and extract rich sequence features, while capsule layers with dynamic routing capture hierarchical and spatial relationships within the learned feature space. We conducted comprehensive ablation studies comparing global and local embeddings from ProteinBERT and conventional one-hot encoding. Results show that ProteinBERT embeddings substantially outperform other representations on large datasets. Although one-hot encoding showed marginal advantages on smaller datasets, such as PDB186, it struggled to scale effectively. Extensive evaluations on four pairs of publicly available benchmark datasets demonstrate that our model consistently outperforms current state-of-the-art methods. It achieved AUC scores of 98.0% and 89.5% on PDB14189andPDB1075, respectively. On independent test sets PDB2272 and PDB186, the model attained top AUCs of 83.2% and 83.3%, while maintaining competitive performance on larger datasets such as PDB20000. Notably, the model maintains a well balanced sensitivity and specificity across datasets. These results demonstrate the efficacy and generalizability of integrating global protein representations with advanced deep learning architectures for reliable and scalable DBP prediction in diverse genomic contexts.
Enhancing Suicide Risk Detection on Social Media through Semi-Supervised Deep Label Smoothing
May 09, 2024Suicide is a prominent issue in society. Unfortunately, many people at risk for suicide do not receive the support required. Barriers to people receiving support include social stigma and lack of access to mental health care. With the popularity of social media, people have turned to online forums, such as Reddit to express their feelings and seek support. This provides the opportunity to support people with the aid of artificial intelligence. Social media posts can be classified, using text classification, to help connect people with professional help. However, these systems fail to account for the inherent uncertainty in classifying mental health conditions. Unlike other areas of healthcare, mental health conditions have no objective measurements of disease often relying on expert opinion. Thus when formulating deep learning problems involving mental health, using hard, binary labels does not accurately represent the true nature of the data. In these settings, where human experts may disagree, fuzzy or soft labels may be more appropriate. The current work introduces a novel label smoothing method which we use to capture any uncertainty within the data. We test our approach on a five-label multi-class classification problem. We show, our semi-supervised deep label smoothing method improves classification accuracy above the existing state of the art. Where existing research reports an accuracy of 43\% on the Reddit C-SSRS dataset, using empirical experiments to evaluate our novel label smoothing method, we improve upon this existing benchmark to 52\%. These improvements in model performance have the potential to better support those experiencing mental distress. Future work should explore the use of probabilistic methods in both natural language processing and quantifying contributions of both epistemic and aleatoric uncertainty in noisy datasets.
DE-CGAN: Boosting rTMS Treatment Prediction with Diversity Enhancing Conditional Generative Adversarial Networks
Apr 25, 2024Repetitive Transcranial Magnetic Stimulation (rTMS) is a well-supported, evidence-based treatment for depression. However, patterns of response to this treatment are inconsistent. Emerging evidence suggests that artificial intelligence can predict rTMS treatment outcomes for most patients using fMRI connectivity features. While these models can reliably predict treatment outcomes for many patients for some underrepresented fMRI connectivity measures DNN models are unable to reliably predict treatment outcomes. As such we propose a novel method, Diversity Enhancing Conditional General Adversarial Network (DE-CGAN) for oversampling these underrepresented examples. DE-CGAN creates synthetic examples in difficult-to-classify regions by first identifying these data points and then creating conditioned synthetic examples to enhance data diversity. Through empirical experiments we show that a classification model trained using a diversity enhanced training set outperforms traditional data augmentation techniques and existing benchmark results. This work shows that increasing the diversity of a training dataset can improve classification model performance. Furthermore, this work provides evidence for the utility of synthetic patients providing larger more robust datasets for both AI researchers and psychiatrists to explore variable relationships.
Novel entropy difference-based EEG channel selection technique for automated detection of ADHD
Apr 15, 2024Attention deficit hyperactivity disorder (ADHD) is one of the common neurodevelopmental disorders in children. This paper presents an automated approach for ADHD detection using the proposed entropy difference (EnD)- based encephalogram (EEG) channel selection approach. In the proposed approach, we selected the most significant EEG channels for the accurate identification of ADHD using an EnD-based channel selection approach. Secondly, a set of features is extracted from the selected channels and fed to a classifier. To verify the effectiveness of the channels selected, we explored three sets of features and classifiers. More specifically, we explored discrete wavelet transform (DWT), empirical mode decomposition (EMD) and symmetrically-weighted local binary pattern (SLBP)-based features. To perform automated classification, we have used k-nearest neighbor (k-NN), Ensemble classifier, and support vectors machine (SVM) classifiers. Our proposed approach yielded the highest accuracy of 99.29% using the public database. In addition, the proposed EnD-based channel selection has consistently provided better classification accuracies than the entropy-based channel selection approach. Also, the developed method
NRC-Net: Automated noise robust cardio net for detecting valvular cardiac diseases using optimum transformation method with heart sound signals
Apr 29, 2023Cardiovascular diseases (CVDs) can be effectively treated when detected early, reducing mortality rates significantly. Traditionally, phonocardiogram (PCG) signals have been utilized for detecting cardiovascular disease due to their cost-effectiveness and simplicity. Nevertheless, various environmental and physiological noises frequently affect the PCG signals, compromising their essential distinctive characteristics. The prevalence of this issue in overcrowded and resource-constrained hospitals can compromise the accuracy of medical diagnoses. Therefore, this study aims to discover the optimal transformation method for detecting CVDs using noisy heart sound signals and propose a noise robust network to improve the CVDs classification performance.For the identification of the optimal transformation method for noisy heart sound data mel-frequency cepstral coefficients (MFCCs), short-time Fourier transform (STFT), constant-Q nonstationary Gabor transform (CQT) and continuous wavelet transform (CWT) has been used with VGG16. Furthermore, we propose a novel convolutional recurrent neural network (CRNN) architecture called noise robust cardio net (NRC-Net), which is a lightweight model to classify mitral regurgitation, aortic stenosis, mitral stenosis, mitral valve prolapse, and normal heart sounds using PCG signals contaminated with respiratory and random noises. An attention block is included to extract important temporal and spatial features from the noisy corrupted heart sound.The results of this study indicate that,CWT is the optimal transformation method for noisy heart sound signals. When evaluated on the GitHub heart sound dataset, CWT demonstrates an accuracy of 95.69% for VGG16, which is 1.95% better than the second-best CQT transformation technique. Moreover, our proposed NRC-Net with CWT obtained an accuracy of 97.4%, which is 1.71% higher than the VGG16.
Uncertainty Aware Neural Network from Similarity and Sensitivity
Apr 27, 2023Researchers have proposed several approaches for neural network (NN) based uncertainty quantification (UQ). However, most of the approaches are developed considering strong assumptions. Uncertainty quantification algorithms often perform poorly in an input domain and the reason for poor performance remains unknown. Therefore, we present a neural network training method that considers similar samples with sensitivity awareness in this paper. In the proposed NN training method for UQ, first, we train a shallow NN for the point prediction. Then, we compute the absolute differences between prediction and targets and train another NN for predicting those absolute differences or absolute errors. Domains with high average absolute errors represent a high uncertainty. In the next step, we select each sample in the training set one by one and compute both prediction and error sensitivities. Then we select similar samples with sensitivity consideration and save indexes of similar samples. The ranges of an input parameter become narrower when the output is highly sensitive to that parameter. After that, we construct initial uncertainty bounds (UB) by considering the distribution of sensitivity aware similar samples. Prediction intervals (PIs) from initial uncertainty bounds are larger and cover more samples than required. Therefore, we train bound correction NN. As following all the steps for finding UB for each sample requires a lot of computation and memory access, we train a UB computation NN. The UB computation NN takes an input sample and provides an uncertainty bound. The UB computation NN is the final product of the proposed approach. Scripts of the proposed method are available in the following GitHub repository: github.com/dipuk0506/UQ
Classification and Self-Supervised Regression of Arrhythmic ECG Signals Using Convolutional Neural Networks
Oct 25, 2022
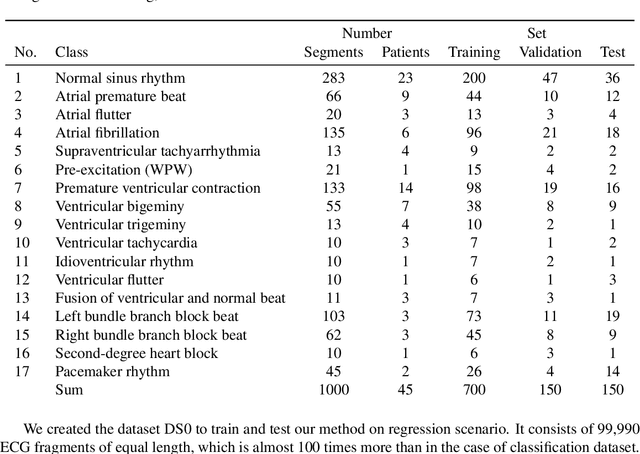
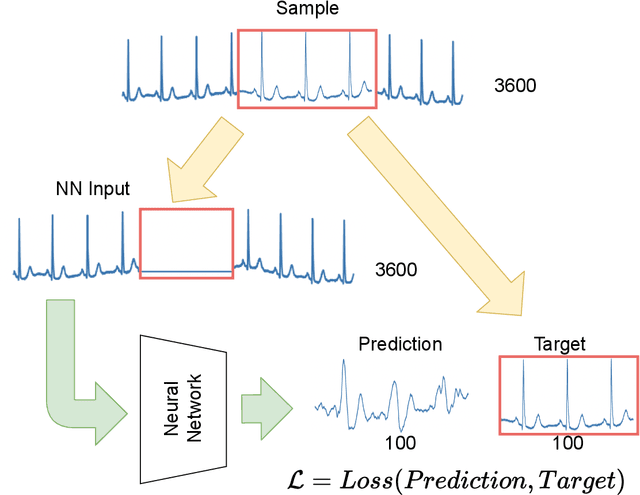

Interpretation of electrocardiography (ECG) signals is required for diagnosing cardiac arrhythmia. Recently, machine learning techniques have been applied for automated computer-aided diagnosis. Machine learning tasks can be divided into regression and classification. Regression can be used for noise and artifacts removal as well as resolve issues of missing data from low sampling frequency. Classification task concerns the prediction of output diagnostic classes according to expert-labeled input classes. In this work, we propose a deep neural network model capable of solving regression and classification tasks. Moreover, we combined the two approaches, using unlabeled and labeled data, to train the model. We tested the model on the MIT-BIH Arrhythmia database. Our method showed high effectiveness in detecting cardiac arrhythmia based on modified Lead II ECG records, as well as achieved high quality of ECG signal approximation. For the former, our method attained overall accuracy of 87:33% and balanced accuracy of 80:54%, on par with reference approaches. For the latter, application of self-supervised learning allowed for training without the need for expert labels. The regression model yielded satisfactory performance with fairly accurate prediction of QRS complexes. Transferring knowledge from regression to the classification task, our method attained higher overall accuracy of 87:78%.
FedStack: Personalized activity monitoring using stacked federated learning
Sep 27, 2022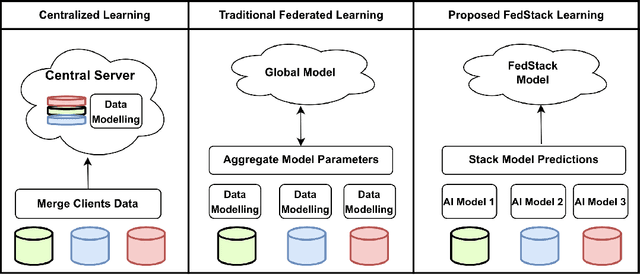
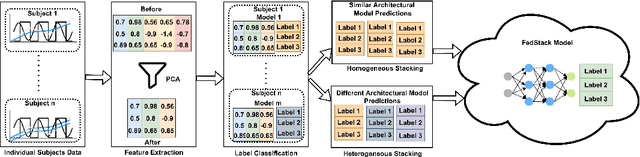
Recent advances in remote patient monitoring (RPM) systems can recognize various human activities to measure vital signs, including subtle motions from superficial vessels. There is a growing interest in applying artificial intelligence (AI) to this area of healthcare by addressing known limitations and challenges such as predicting and classifying vital signs and physical movements, which are considered crucial tasks. Federated learning is a relatively new AI technique designed to enhance data privacy by decentralizing traditional machine learning modeling. However, traditional federated learning requires identical architectural models to be trained across the local clients and global servers. This limits global model architecture due to the lack of local models heterogeneity. To overcome this, a novel federated learning architecture, FedStack, which supports ensembling heterogeneous architectural client models was proposed in this study. This work offers a protected privacy system for hospitalized in-patients in a decentralized approach and identifies optimum sensor placement. The proposed architecture was applied to a mobile health sensor benchmark dataset from 10 different subjects to classify 12 routine activities. Three AI models, ANN, CNN, and Bi-LSTM were trained on individual subject data. The federated learning architecture was applied to these models to build local and global models capable of state of the art performances. The local CNN model outperformed ANN and Bi-LSTM models on each subject data. Our proposed work has demonstrated better performance for heterogeneous stacking of the local models compared to homogeneous stacking. This work sets the stage to build an enhanced RPM system that incorporates client privacy to assist with clinical observations for patients in an acute mental health facility and ultimately help to prevent unexpected death.
Resource allocation optimization using artificial intelligence methods in various computing paradigms: A Review
Mar 23, 2022
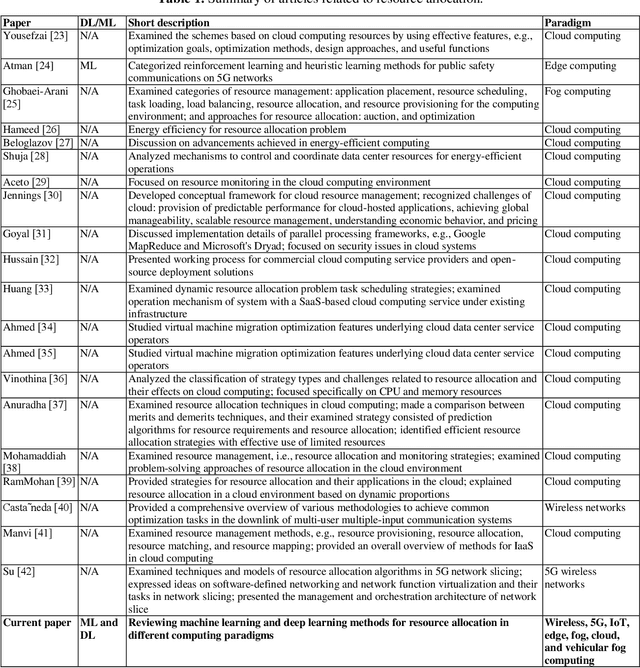
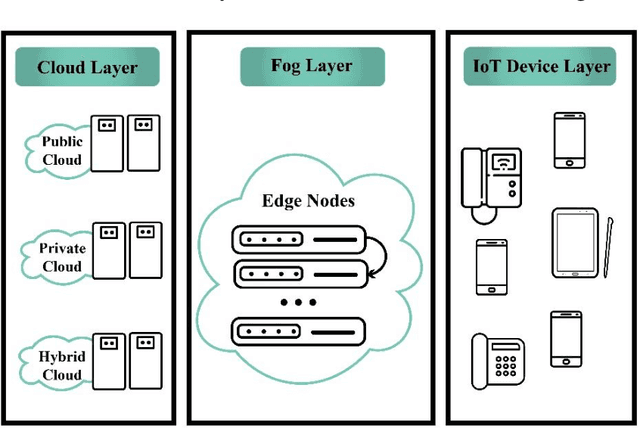
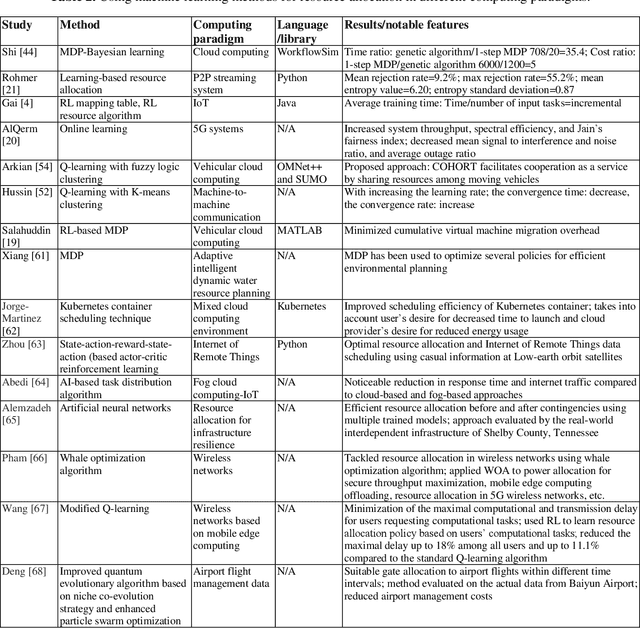
With the advent of smart devices, the demand for various computational paradigms such as the Internet of Things, fog, and cloud computing has increased. However, effective resource allocation remains challenging in these paradigms. This paper presents a comprehensive literature review on the application of artificial intelligence (AI) methods such as deep learning (DL) and machine learning (ML) for resource allocation optimization in computational paradigms. To the best of our knowledge, there are no existing reviews on AI-based resource allocation approaches in different computational paradigms. The reviewed ML-based approaches are categorized as supervised and reinforcement learning (RL). Moreover, DL-based approaches and their combination with RL are surveyed. The review ends with a discussion on open research directions and a conclusion.