 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoCR-RAG: Enhancing Retrieval-Augmented Generation in Web Q&A via Concept-oriented Context Reconstruction
Mar 25, 2026Retrieval-augmented generation (RAG) has shown promising results in enhancing Q&A by incorporating information from the web and other external sources. However, the supporting documents retrieved from the heterogeneous web often originate from multiple sources with diverse writing styles, varying formats, and inconsistent granularity. Fusing such multi-source documents into a coherent and knowledge-intensive context remains a significant challenge, as the presence of irrelevant and redundant information can compromise the factual consistency of the inferred answers. This paper proposes the Concept-oriented Context Reconstruction RAG (CoCR-RAG), a framework that addresses the multi-source information fusion problem in RAG through linguistically grounded concept-level integration. Specifically, we introduce a concept distillation algorithm that extracts essential concepts from Abstract Meaning Representation (AMR), a stable semantic representation that structures the meaning of texts as logical graphs. The distilled concepts from multiple retrieved documents are then fused and reconstructed into a unified, information-intensive context by Large Language Models, which supplement only the necessary sentence elements to highlight the core knowledge. Experiments on the PopQA and EntityQuestions datasets demonstrate that CoCR-RAG significantly outperforms existing context-reconstruction methods across these Web Q&A benchmarks. Furthermore, CoCR-RAG shows robustness across various backbone LLMs, establishing itself as a flexible, plug-and-play component adaptable to different RAG frameworks.
FedMLAC: Mutual Learning Driven Heterogeneous Federated Audio Classification
Jun 11, 2025
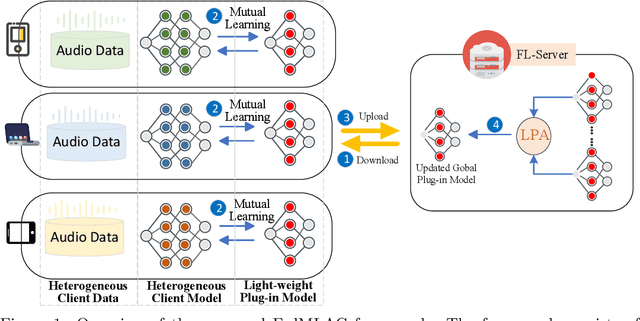

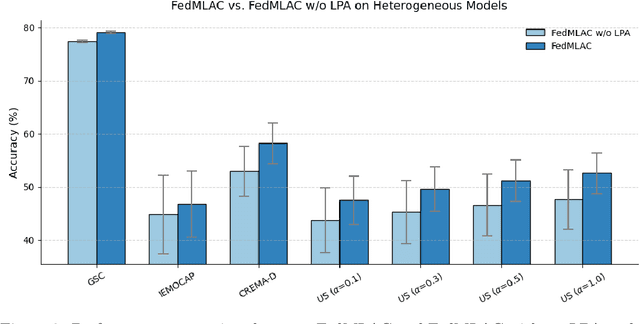
Federated Learning (FL) provides a privacy-preserving paradigm for training audio classification (AC) models across distributed clients without sharing raw data. However, Federated Audio Classification (FedAC) faces three critical challenges that substantially hinder performance: data heterogeneity, model heterogeneity, and data poisoning. While prior works have attempted to address these issues, they are typically treated independently, lacking a unified and robust solution suited to real-world federated audio scenarios. To bridge this gap, we propose FedMLAC, a unified mutual learning framework designed to simultaneously tackle these challenges in FedAC. Specifically, FedMLAC introduces a dual-model architecture on each client, comprising a personalized local AC model and a lightweight, globally shared Plug-in model. Through bidirectional knowledge distillation, the Plug-in model enables global knowledge transfer while adapting to client-specific data distributions, thus supporting both generalization and personalization. To further enhance robustness against corrupted audio data, we develop a Layer-wise Pruning Aggregation (LPA) strategy that filters unreliable Plug-in model updates based on parameter deviations during server-side aggregation. Extensive experiments on four diverse audio classification benchmarks, spanning both speech and non-speech tasks, demonstrate that FedMLAC consistently outperforms existing state-of-the-art methods in terms of classification accuracy and robustness to noisy data.
Divide-and-Conquer: Cold-Start Bundle Recommendation via Mixture of Diffusion Experts
May 08, 2025Cold-start bundle recommendation focuses on modeling new bundles with insufficient information to provide recommendations. Advanced bundle recommendation models usually learn bundle representations from multiple views (e.g., interaction view) at both the bundle and item levels. Consequently, the cold-start problem for bundles is more challenging than that for traditional items due to the dual-level multi-view complexity. In this paper, we propose a novel Mixture of Diffusion Experts (MoDiffE) framework, which employs a divide-and-conquer strategy for cold-start bundle recommendation and follows three steps:(1) Divide: The bundle cold-start problem is divided into independent but similar sub-problems sequentially by level and view, which can be summarized as the poor representation of feature-missing bundles in prior-embedding models. (2) Conquer: Beyond prior-embedding models that fundamentally provide the embedded representations, we introduce a diffusion-based method to solve all sub-problems in a unified way, which directly generates diffusion representations using diffusion models without depending on specific features. (3) Combine: A cold-aware hierarchical Mixture of Experts (MoE) is employed to combine results of the sub-problems for final recommendations, where the two models for each view serve as experts and are adaptively fused for different bundles in a multi-layer manner. Additionally, MoDiffE adopts a multi-stage decoupled training pipeline and introduces a cold-start gating augmentation method to enable the training of gating for cold bundles. Through extensive experiments on three real-world datasets, we demonstrate that MoDiffE significantly outperforms existing solutions in handling cold-start bundle recommendation. It achieves up to a 0.1027 absolute gain in Recall@20 in cold-start scenarios and up to a 47.43\% relative improvement in all-bundle scenarios.
Random Forest-of-Thoughts: Uncertainty-aware Reasoning for Computational Social Science
Feb 26, 2025



Social surveys in computational social science are well-designed by elaborate domain theories that can effectively reflect the interviewee's deep thoughts without concealing their true feelings. The candidate questionnaire options highly depend on the interviewee's previous answer, which results in the complexity of social survey analysis, the time, and the expertise required. The ability of large language models (LLMs) to perform complex reasoning is well-enhanced by prompting learning such as Chain-of-thought (CoT) but still confined to left-to-right decision-making processes or limited paths during inference. This means they can fall short in problems that require exploration and uncertainty searching. In response, a novel large language model prompting method, called Random Forest of Thoughts (RFoT), is proposed for generating uncertainty reasoning to fit the area of computational social science. The RFoT allows LLMs to perform deliberate decision-making by generating diverse thought space and randomly selecting the sub-thoughts to build the forest of thoughts. It can extend the exploration and prediction of overall performance, benefiting from the extensive research space of response. The method is applied to optimize computational social science analysis on two datasets covering a spectrum of social survey analysis problems. Our experiments show that RFoT significantly enhances language models' abilities on two novel social survey analysis problems requiring non-trivial reasoning.
Exploring Incremental Unlearning: Techniques, Challenges, and Future Directions
Feb 23, 2025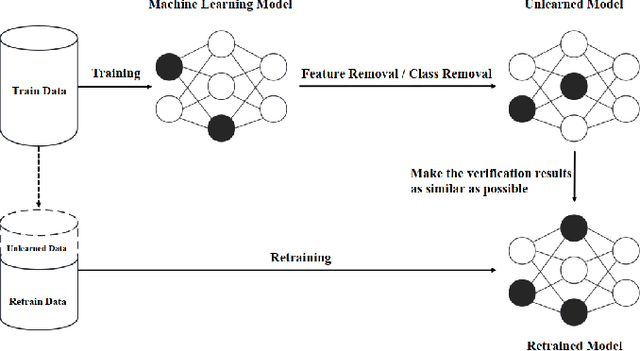
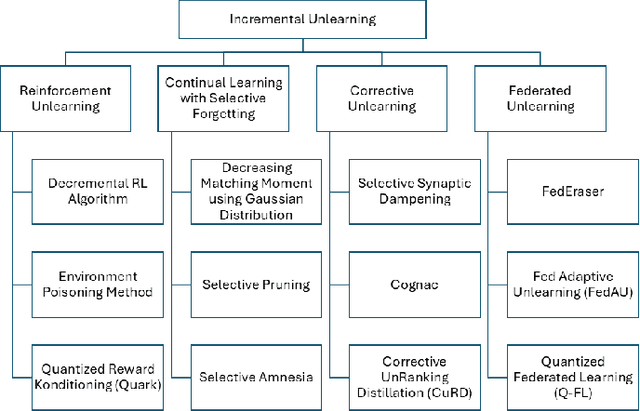
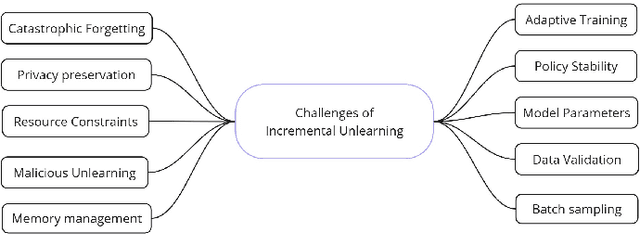

The growing demand for data privacy in Machine Learning (ML) applications has seen Machine Unlearning (MU) emerge as a critical area of research. As the `right to be forgotten' becomes regulated globally, it is increasingly important to develop mechanisms that delete user data from AI systems while maintaining performance and scalability of these systems. Incremental Unlearning (IU) is a promising MU solution to address the challenges of efficiently removing specific data from ML models without the need for expensive and time-consuming full retraining. This paper presents the various techniques and approaches to IU. It explores the challenges faced in designing and implementing IU mechanisms. Datasets and metrics for evaluating the performance of unlearning techniques are discussed as well. Finally, potential solutions to the IU challenges alongside future research directions are offered. This survey provides valuable insights for researchers and practitioners seeking to understand the current landscape of IU and its potential for enhancing privacy-preserving intelligent systems.
FedDW: Distilling Weights through Consistency Optimization in Heterogeneous Federated Learning
Dec 05, 2024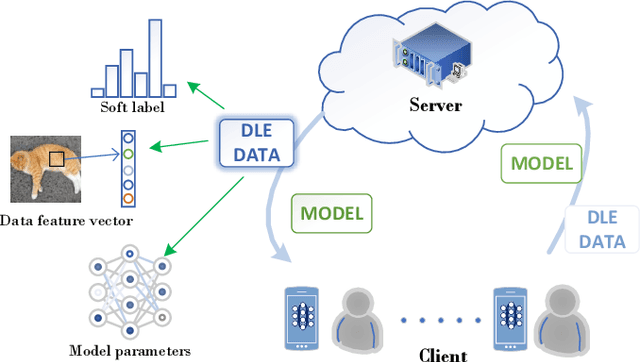
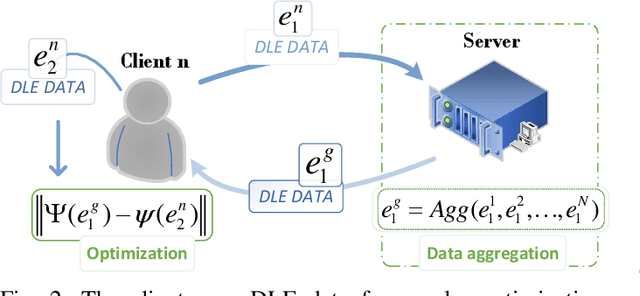
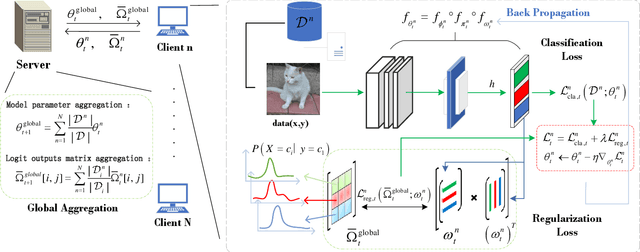
Federated Learning (FL) is an innovative distributed machine learning paradigm that enables neural network training across devices without centralizing data. While this addresses issues of information sharing and data privacy, challenges arise from data heterogeneity across clients and increasing network scale, leading to impacts on model performance and training efficiency. Previous research shows that in IID environments, the parameter structure of the model is expected to adhere to certain specific consistency principles. Thus, identifying and regularizing these consistencies can mitigate issues from heterogeneous data. We found that both soft labels derived from knowledge distillation and the classifier head parameter matrix, when multiplied by their own transpose, capture the intrinsic relationships between data classes. These shared relationships suggest inherent consistency. Therefore, the work in this paper identifies the consistency between the two and leverages it to regulate training, underpinning our proposed FedDW framework. Experimental results show FedDW outperforms 10 state-of-the-art FL methods, improving accuracy by an average of 3% in highly heterogeneous settings. Additionally, we provide a theoretical proof that FedDW offers higher efficiency, with the additional computational load from backpropagation being negligible. The code is available at https://github.com/liuvvvvv1/FedDW.
A Survey on Bundle Recommendation: Methods, Applications, and Challenges
Nov 01, 2024

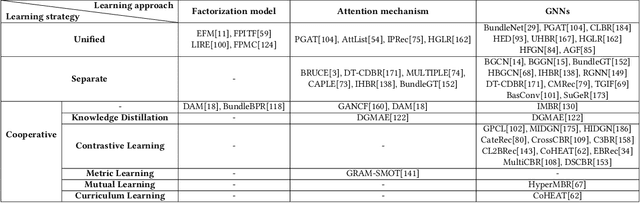
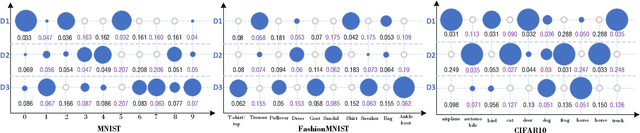
In recent years, bundle recommendation systems have gained significant attention in both academia and industry due to their ability to enhance user experience and increase sales by recommending a set of items as a bundle rather than individual items. This survey provides a comprehensive review on bundle recommendation, beginning by a taxonomy for exploring product bundling. We classify it into two categories based on bundling strategy from various application domains, i.e., discriminative and generative bundle recommendation. Then we formulate the corresponding tasks of the two categories and systematically review their methods: 1) representation learning from bundle and item levels and interaction modeling for discriminative bundle recommendation; 2) representation learning from item level and bundle generation for generative bundle recommendation. Subsequently, we survey the resources of bundle recommendation including datasets and evaluation metrics, and conduct reproducibility experiments on mainstream models. Lastly, we discuss the main challenges and highlight the promising future directions in the field of bundle recommendation, aiming to serve as a useful resource for researchers and practitioners. Our code and datasets are publicly available at https://github.com/WUT-IDEA/bundle-recommendation-survey.
A Unified Solution to Diverse Heterogeneities in One-shot Federated Learning
Oct 28, 2024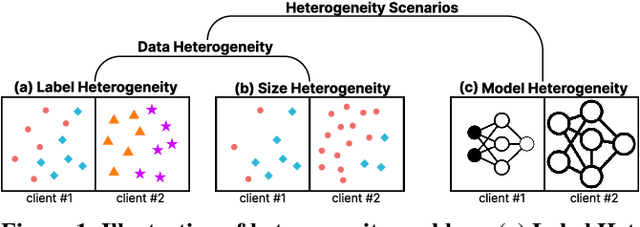

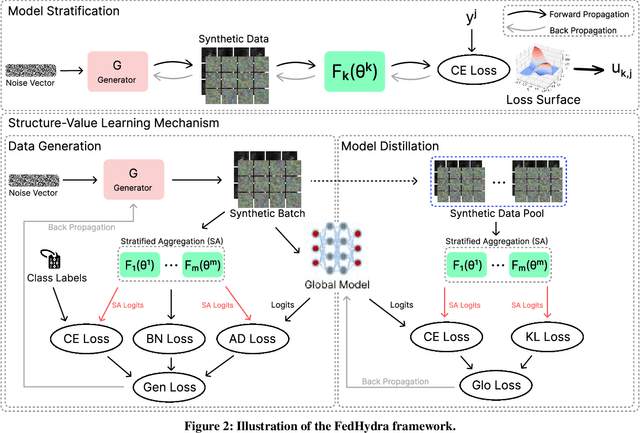
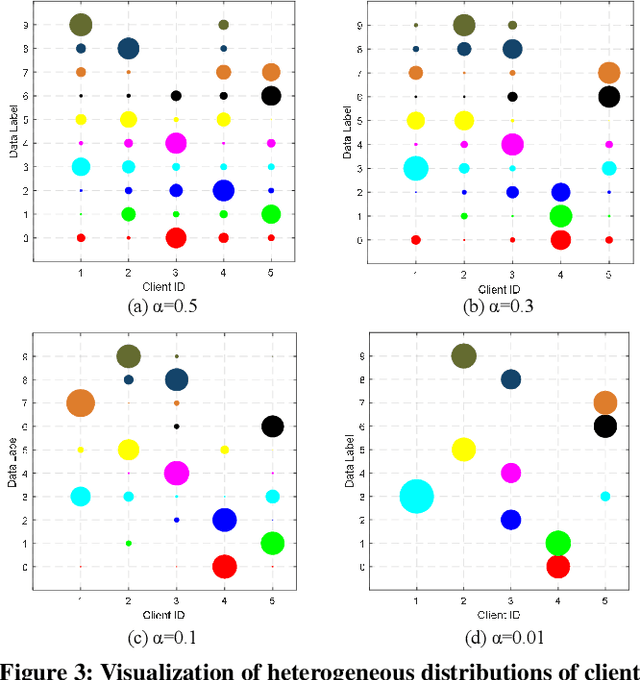
One-shot federated learning (FL) limits the communication between the server and clients to a single round, which largely decreases the privacy leakage risks in traditional FLs requiring multiple communications. However, we find existing one-shot FL frameworks are vulnerable to distributional heterogeneity due to their insufficient focus on data heterogeneity while concentrating predominantly on model heterogeneity. Filling this gap, we propose a unified, data-free, one-shot federated learning framework (FedHydra) that can effectively address both model and data heterogeneity. Rather than applying existing value-only learning mechanisms, a structure-value learning mechanism is proposed in FedHydra. Specifically, a new stratified learning structure is proposed to cover data heterogeneity, and the value of each item during computation reflects model heterogeneity. By this design, the data and model heterogeneity issues are simultaneously monitored from different aspects during learning. Consequently, FedHydra can effectively mitigate both issues by minimizing their inherent conflicts. We compared FedHydra with three SOTA baselines on four benchmark datasets. Experimental results show that our method outperforms the previous one-shot FL methods in both homogeneous and heterogeneous settings.
Exploring ChatGPT-based Augmentation Strategies for Contrastive Aspect-based Sentiment Analysis
Sep 17, 2024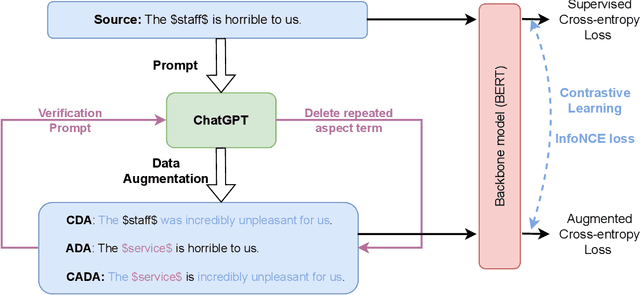

Aspect-based sentiment analysis (ABSA) involves identifying sentiment towards specific aspect terms in a sentence and allows us to uncover nuanced perspectives and attitudes on particular aspects of a product, service, or topic. However, the scarcity of labeled data poses a significant challenge to training high-quality models. To address this issue, we explore the potential of data augmentation using ChatGPT, a well-performing large language model (LLM), to enhance the sentiment classification performance towards aspect terms. Specifically, we explore three data augmentation strategies based on ChatGPT: context-focused, aspect-focused, and context-aspect data augmentation techniques. Context-focused data augmentation focuses on changing the word expression of context words in the sentence while keeping aspect terms unchanged. In contrast, aspect-focused data augmentation aims to change aspect terms but keep context words unchanged. Context-Aspect data augmentation integrates the above two data augmentations to generate augmented samples. Furthermore, we incorporate contrastive learning into the ABSA tasks to improve performance. Extensive experiments show that all three data augmentation techniques lead to performance improvements, with the context-aspect data augmentation strategy performing best and surpassing the performance of the baseline models.
Enhancing Suicide Risk Detection on Social Media through Semi-Supervised Deep Label Smoothing
May 09, 2024Suicide is a prominent issue in society. Unfortunately, many people at risk for suicide do not receive the support required. Barriers to people receiving support include social stigma and lack of access to mental health care. With the popularity of social media, people have turned to online forums, such as Reddit to express their feelings and seek support. This provides the opportunity to support people with the aid of artificial intelligence. Social media posts can be classified, using text classification, to help connect people with professional help. However, these systems fail to account for the inherent uncertainty in classifying mental health conditions. Unlike other areas of healthcare, mental health conditions have no objective measurements of disease often relying on expert opinion. Thus when formulating deep learning problems involving mental health, using hard, binary labels does not accurately represent the true nature of the data. In these settings, where human experts may disagree, fuzzy or soft labels may be more appropriate. The current work introduces a novel label smoothing method which we use to capture any uncertainty within the data. We test our approach on a five-label multi-class classification problem. We show, our semi-supervised deep label smoothing method improves classification accuracy above the existing state of the art. Where existing research reports an accuracy of 43\% on the Reddit C-SSRS dataset, using empirical experiments to evaluate our novel label smoothing method, we improve upon this existing benchmark to 52\%. These improvements in model performance have the potential to better support those experiencing mental distress. Future work should explore the use of probabilistic methods in both natural language processing and quantifying contributions of both epistemic and aleatoric uncertainty in noisy datasets.